

Dieser Blogpost ist auch auf Deutsch verfügbar
The Hypertext Application Language (abbr. HAL) is an open specification that provides a structure to represent RESTful resources. It defines two hypermedia types to extend for XML and JSON. Initially proposed in 2011 by Mike Kelly, HAL is hardly a newcomer and has been used extensively in countless projects to organise and structure APIs.
During the last couple of years we have been working in developing a midsize API that provides access to an internal collection of resources in a large corporation. Instead of going for one of the new cutting edge technologies and inspired by the Richardson Maturity Model, we took a pragmatic approach and used HAL as a proven, mature technology. Throughout the project, we built our APIs and services through several incarnations and in the process we had the chance to collect a great deal of practical, day-to-day experience in designing, developing, maintaining and advocating a HAL based architecture.
The basics of HAL
As is the case with most technologies that have been around for a while, there is plenty of documentation and tutorials online for HAL, so in this section we will present just the basics required to understand the rest of this article. In its essence, HAL is a hypermedia format to represent resources and to connect them in a usable way. HAL is organised around two main concepts: embedding related resources and listing related links to other resources.
Each HAL representation includes a map (conveniently called _links) containing a list of links to navigate from the
resource, and an optional map of embedded resources (_embedded) which again includes _links to find the entire
resource via its self link (think of an ID). For clients consuming the API, the use of these links and the extensive
availability of solid tools supporting HAL (e.g. in Spring HATEOAS) helps in building software that remains
independent of hardcoded URIs with private IDs belonging to the internal space of the API.
The links inside a resource are identified by a relation name or “rel” that defines the semantic of the link. HAL uses
established standards (RFC 8288) to define which elements can be included in the links of a resource, such as self
for the current resource; or previous and next for other pages of a paginated collection of resources.
Generic relationships provide only the basic for defining a functional API. To create a usable domain language, the IANA registry allows the creation of custom relation types in addition to the standard predefined link relations. The identifier for the relation is a URI pointing to the documentation of the relation. In a customer management system, for example, we might need a link to list all orders for a customer:
{
"name": "Jon Doe",
"_links": {
"self": {
"href": "http://example.com/customer/123"
},
"http://example.com/rels/customer-orders": { // bulky rel identifier
"href": "http://example.com/customer/123/orders"
}
}
}The use of the Curie (= compact URI) mechanism provides a way of avoiding bulky rel identifiers and to easily
access the documentation for custom rels in the context of HAL. Resources include a templated URL that can be parametrized
with the resource type identifier and used to retrieve the documentation for the rel. In the following example, the
rel rel=ex:customer-orders would lead to the documentation stored in http://example.com/rels/customer-address.
{
"name": "Jon Doe",
"_links": {
"self": {
"href": "http://example.com/customer/123"
},
"ex:customer-orders": { // now a handy rel identifier
"href": "http://example.com/customer/123/orders"
},
"curies": [
{
"href": "http://example.com/rels/{rel}",
"name": "ex",
"templated": true
}
]
},
"_embedded": { // optional; embedded Orders resource of the Customer
"ex:customer-orders": [ // same rel as in the _links section
{
"orderNumber": "123ASDF",
"shippingAddress": "Ohlauer Str. 43, 10999 Berlin",
"_links": {
"self": {
"href": "http://example.com/customer/123/orders/ASDF"
},
"ex:customer": {
"href": "http://example.com/customer/123"
}
}
}
]
}
}Domain specific relations can be used not only as identifiers for navigational links between resources, but also for
embedded resources (such as parent or child resources). An OrderResource, for example, could contain an embedded
CustomerAddressResource, saving the consumers of the API the need for a further GET round-trips following the
rel=ex:customer-address link to obtain the address of the customer. While developing the application, we often started
by providing meaningful (stateful) links to all related resources and then further optimised responses by replacing some
links with the corresponding embedded resource based on feedback collected from consumers of the API.
Thanks to the design of HAL, this evolution was fully transparent for API consumers, since the difference between a link and an embedded resource was noticeable only in a change of the required number calls to fulfill the request for a certain navigational path.
Developing a HAL based API - Pragmatism rather than dogmatism
As we moved along the project, we passed across several incarnations of our system, built upon several tech stacks ranging from Dropwizard, Rails, Grails, Ktor and consolidating finally on Spring Boot. In the process, we committed to HATEOAS and the use of JSON/HAL as the standard to define the API and to encode the resources requested by the clients.
Developing and operating an HTTP API, even for a relatively small and well-known universe of clients, involves not only technical challenges but also organisational ones. As we moved forward, we realised the need for what we liked to call API hygiene in our project. Functional and non-functional requirements clashed over each other and pushed for correct solutions. The development process often becomes a balancing act between pragmatically answer to user requirements and future proofing the API by following proper RESTful principles. In the following sections, we illustrate several decisions that emerged from this process, using examples taken from the delivered implementation of the system.
Aggregated results as filter input for query params
For most of our collection-resources we offered filtering options that could be configured through the use of query
parameters. In addition to the mandatory rel=self, we added 3 additional templated links in our responses that were
prepopulated with the filter criteria used to retrieve the resource. This enabled both computer and human clients to
further drill down into the collection-resource. To support the exploration of the search space and find values
leading to non-empty search results, we introduced aggregation-resources, or resources that provided an SQL group
by of sorts. The aggregation resources also offered a parameterizable search end point similar to the one provided by
collection-resources, but instead of a list of resources, the returned response contained buckets for each of the
search query parameters, which were filled with the aggregation of values for the field matching the original search
query. The returned resource provided links pointing to the corresponding collection-resources, which allowed clients
to build sophisticated workflows including complex UIs for exploring and navigating the rather complex and large data space.
{
"_embedded": {
"ex:planes": [ // only 1 plane here displayed for demonstration
{
"_links": {
"self": {
"href": "http://example.com/planes/123"
}
},
"makeName": "CESSNA",
"modelName": "Skycatcher",
"modelYear": 2018,
"trimLevel": "PERFORMANCE",
"wingCount": 5
}
]
},
"_links": {
"self": {
"href": "http://example.com/planes?makeName=CESSNA&modelName=Skycatcher&modelYear=2018"
},
"ex:planes": { // current filter of planes
"href": "http://example.com/planes?makeName=CESSNA&modelName=Skycatcher&modelYear=2018{&hasImages,country,trimLevel,wingCount,bodyType,andManyMore,sort,page,size}",
"title": "PLANES (Collection)",
"templated": true
},
"ex:planes_agg": { // current filter of planes' unique attributes for further drill-down (eg in HTML select-boxes)
"href": "http://example.com/planes-agg?makeName=CESSNA&modelName=Skycatcher&modelYear=2018{&hasImages,country,trimLevel,wingCount,bodyType,andManyMore}",
"title": "PLANES_AGG (Aggregation)",
"templated": true // non-templated direct link omitted
}
}
}{
"_links": {
"self": {
"href": "http://example.com/planes-agg?makeName=CESSNA&modelName=Skycatcher&modelYear=2018"
},
"ex:planes_agg": { // self-link with additional templated variables for further drill-down
"href": "http://example.com/planes-agg?makeName=CESSNA&modelName=Skycatcher&modelYear=2018{&hasImages,country,trimLevel,wingCount,bodyType,andManyMore}",
"title": "PLANES_AGG (Aggregation)",
"templated": true
},
"ex:planes": { // resulting list of planes by applying the current filter
"href": "http://example.com/planes?makeName=CESSNA&modelName=Skycatcher&modelYear=2018{&hasImages,country,trimLevel,wingCount,bodyType,andManyMore,sort,page,size}",
"title": "PLANES (Collection)",
"templated": true // non-templated direct link omitted
}
},
"makeName": [
"CESSNA"
],
"modelName": [
"Skycatcher"
],
"modelYear": [
2018,
2017
],
"country": [
"GER",
"USA",
"CHL"
],
"trimLevel": [
"ALLTRACK",
"PERFORMANCE",
"DELUXE EDITION"
]
}Bulk-Assignments using magic endpoints
Several times, while building the API, we bumped into situations that forced us to take shortcuts in the API which doesn’t
make us particularly proud, but which decided to take nonetheless, as they proved to be the only pragmatic solution to follow.
One example of this was the requirement by the main administration client to support batch updates
for large collection of resources. For certain workflows, we had to simultaneously update hundreds of resources in
response to a single click in the UI. This was the case when resources needed a parent-child relationship update for
which we didn’t want to introduce additional transfer-resources. For these cases, we went for a simple and bodiless
relation-resource with templated ID variables and offering only PUT and DELETE operations, as seen in the example
below, in the rel=ex:model-planes link. The example clearly breaks the HATEOAS principle forbidding memorized
IDs, but we decided to live with this violation as it was a very important use case.
{
"_links": {
"self": {
"href": "http://example.com/models/123"
},
"ex:planes": {
"href": "http://example.com/planes?modelId=123"
},
"ex:model-planes": [
{
"href": "http://example.com/models/123/planes/{planeIds}",
"title": "MODEL has PLANES",
"name": "modelHasPlanesTemplated",
"templated": true
},
{
"href": "http://example.com/models/123/planes/1,2,3,4,5", // current assignment (Shortcut)
"title": "MODEL has PLANES",
"name": "modelHasPlanes"
}
],
"curies": // omitted for namespace ex
}
}HAL extensions to disclose HTTP methods
The specification of HAL links does not provide methods to find out which media-type is used and which HTTP methods
are permitted for a particular resource. To obtain this information beforehand, a client should use OPTIONS and HEAD
requests instead. In reality, this round trip is rarely implemented in runtime by the consumers of the API, which often
prefer to hard code this information based on the documentation (eg. by looking at the code repository or checking
Swagger).
Spring HATEOAS, by means of the Affordances API, provides a proper way to bundle several endpoints behind HTTP
methods for any given relation-name. In order to expose these bundles for HAL representations, one could resort to
extensions like HAL Forms, but this often tends to result in a bloated LinkObject. For our needs, we opted for a more
lightweight approach and extended the original LinkObject by adding a custom methods attribute. We populated the
field with the information resulting from polling (cached) JAVA reflection data for annotations in the endpoint methods
such as @PutMapping and @DeleteMapping, for a certain URI path pattern. The resulting field can be seen in the
representation below:
{
"_links": {
"self": {
"href": "http://example.com/customer/jon-doe",
"title": "Jon Doe (age 30)",
"methods": ["GET", "PUT"] // not in standard but very useful for consumers
}
},
"name": "Jon Doe",
"birthday": "1990-01-01"
}Rels instead of URIs as structuring focus for documentation
Documenting an API is as important as the API itself, specially in cases like ours, where the API is open for consumption in a complex ecosystem of clients. A common approach is the use of definition languages such as Swagger/OpenAPI, RAML or Blueprint; and the associated software tools built upon these languages, which allow generating human-readable documentation. Two good examples of such tools are Swagger UI and Redoc, both based on the OpenAPI specification. Most of these documenting tools can be seamlessly integrated by client rendering for existing APIs.
In an early iteration of our work, we used tags in the source code to generate Swagger documentation for the endpoints in the API and link them to the rels. But while this simplified the maintenance of documentation, it defeated one of the most basic benefits of using REST: it brought back the use of URIs, by focusing the documentation around endpoints instead of around relation identifiers (links) used in hypermedia. Over time, we observed that API consumers tend to ignore the provided rels and make assumptions based on reading URIs and very often these assumptions are not correct or provide a distorted idea of the functionality. In the newest version of the project we decided to hide URIs and internal IDs as much as possible, and moved from Swagger UI to [HAL Browser], a generic HAL exploration tool for the browser.
For our API, we came up with an adapted documenting approach. We created profile-resources (see ALPS JsonSchema) for all representation models and for each of our custom rels we generated a relation-resource providing a detailed description (endpoints, status codes, deprecation status and extra markdown for ADR’s for example) - and linked them together. Finally, we listed all relation-resources in a root document (think of a custom rel-registry) and made their documentation available through their Curie identifier.
<h1>Documentation for rel='planes'</h1>
<div id="deprecation">
<h2>Deprecation</h2>false
</div>
<div id="description">
<h2>Description</h2>
<h3>PLANES (Collection)</h3>
<p>Lorem Ipsum Lorem Ipsum Lorem Ipsum …</p>
</div>
<div id="endpoints">
<h2>Endpoints</h2><!-- status codes omitted -->
<ul>
<li>GET http://example.com/planes{?makeName,modelName,modelYear,...,sort,page,size}</li>
<li>POST http://example.com/planes</li>
</ul>
</div>
<div id="profiles">
<h2>Profile (Schema)</h2>
<ul>
<li><a href="http://example.com/profile/PlaneResource">PlaneResource</a></li>
</ul>
</div>{
"type": "object",
"id": "urn:jsonschema:com:example:resource:PlaneResource",
"description": "Profile for com.example.resource.PlaneResource",
"properties": {
"links": {
"type": "array",
"items": {
"type": "object",
"$ref": "urn:jsonschema:org:springframework:hateoas:Link"
}
},
"urn": {
"type": "string",
"readonly": true
},
"country": {
"type": "string",
"code": [
"GER",
"USA",
"CHL"
]
},
"makeName": {
"type": "object",
"$ref": "urn:jsonschema:com:example:NameValue"
},
"modelName": {
"type": "object",
"$ref": "urn:jsonschema:com:example:NameValue"
},
"trimLevel": {
"type": "object",
"$ref": "urn:jsonschema:com:example:NameValue"
}
}
}{
"_links": {
"self": {
"href": "http://example.com/planes/123"
},
"ex:planes": {
"href": "http://example.com/planes/"
},
"profile": {
"href": "http://example.com/profile/PlaneResource",
},
"curies": // omitted for namespace ex
}
}The whole construction played along very nicely with tools such as HAL Explorer which is shown in the screenshot below. Each of the linked relations in the list contains an icon titled docs linking to documentation of the relation. Behind the stage, HAL Browser is simply instantiating the templated relation pointing to the relation register, with the Curie-identifier of the respective relation.
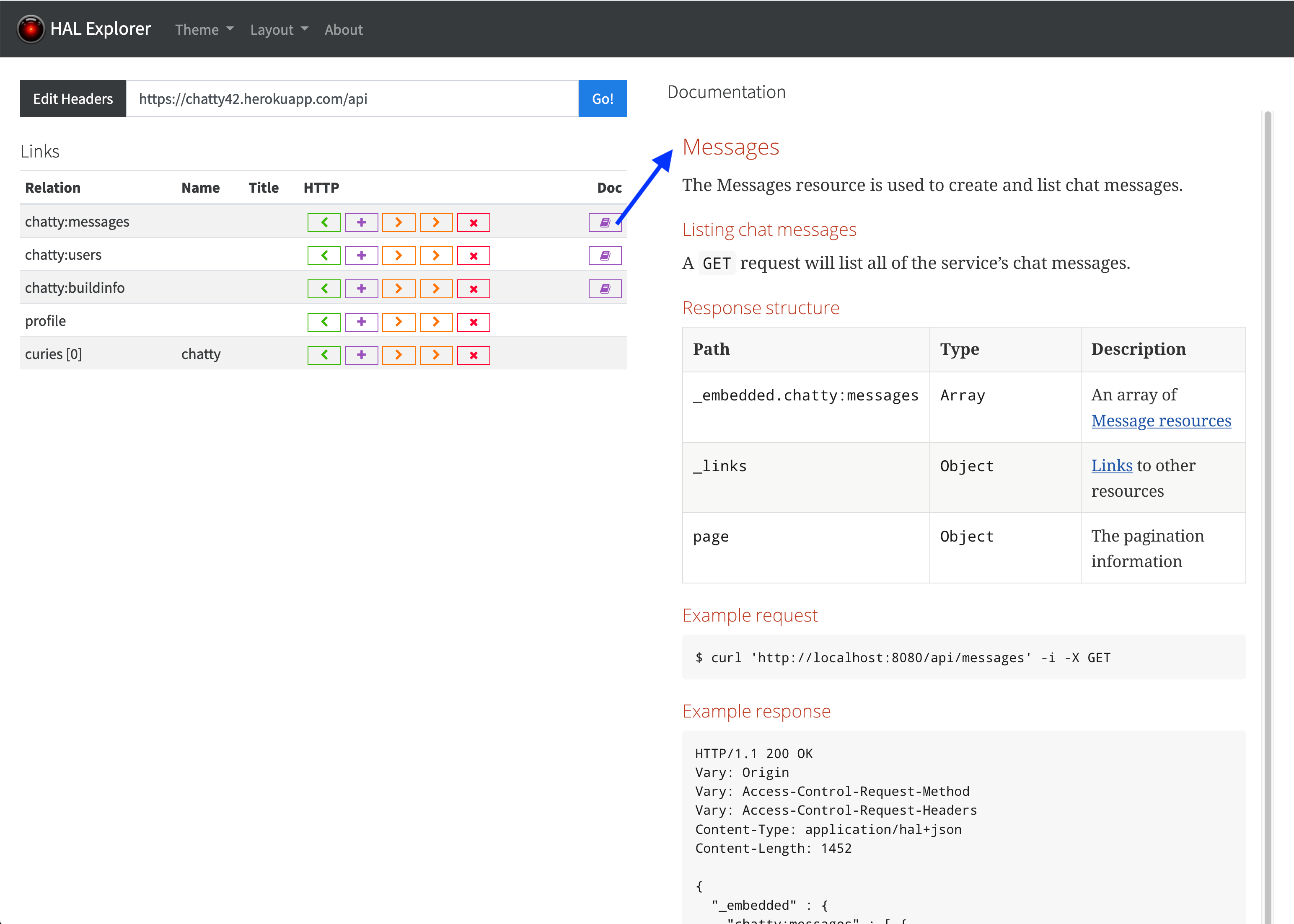
Strict reliance on rels instead of URLs in the administration tool of the API
There were several clients for the backend we developed for our customer, but probably the most complex of them was the administration tool, designed and built to support our users in updating and maintaining the information available in the system. The user base for the administration system was small, but the requirements were very dynamic and grew organically with the progressive availability of new data in the system.
One of the earliest conveniences of using a mature technology was the rich availability of tools for implementing our client. We used a selection of Open Source libraries that were readily available, all around for several years and in a mature, production-ready status. The main tool for navigating HAL was Traverson, a Hypermedia API/HATEOAS Client developed for NodeJS. The tool provides a high level, chainable collection of methods to navigate the API and handle the resources based only on a starting root resource and the names of relations that represent the steps to reach a required resource. A typical call for requesting a resource list looks as follows:
const childList = await traverson
.from("http://example.com")
.withRequestOptions(apiRequestHeaders)
.jsonHal()
.newRequest()
.withTemplateParameters({ parentId })
.follow("ex:planes", "ex:models")
.getResource()
.result;Behind the scenes, Traverson will request the root resource from the entrypoint, will parse and find the url for the relation “ex:planes”. If the relation is templated and expects a parentId, it will create the instance of the url with the passed template parameter and it will request it. Traverson will then parse the list, find “ex:models” and send a GET request to the associated URL and return the retrieved result.
The use of labels greatly simplified the task of expressing complex resources lookups by means of chaining commands. It also made very easy to keep an eye on the coupling between the API and the client. By using unique identifiers instead or URLs, it was very easy to find all places consuming a particular relationship in the whole code base of the administration application and to react easily to changes and provide feedback to the team developing the backend.
What now?
There are plenty of alternatives to HAL. Our humble opinion is however, that most of them take too much control over the final presentation of the resources (see Siren, UBER, Collection+JSON) and tend to be very verbose without really adding much of an extra value. In the case of HAL, the representation of resources can remain stable, and the elements from HAL can be added gradually.
HAL made the progressive evolution of the API more manageable. All URL changes happened behind the scenes, and as long as the traversal list of relationships remained the same, the changes didn’t cause any breaks in the client side. And for the cases where the relationships themselves changed, HAL provided standard mechanisms for deprecation of portions of the API, which help in developing a process to eventually manage breaking changes. Clients never had to rewrite, generate or manipulate URLs in any form, which completely removed a very important cause for common errors.
Maybe the biggest challenge of implementing HAL is of organisational nature. HAL is essentially a convention and as such, its success is based on the commitment of the people following this convention. It required a good deal of discipline from the developers to avoid straying away from the standards of HAL and HATEOAS while looking for shortcuts. This presented a challenge at the beginning and for people coming in later into the project, but the learning curve is not really steep, and it was not difficult to dive in and understand the design philosophy behind our API. We are sure HAL has its limitations, but we found ways in which it can be extended and still can be considered as HAL, and benefit from the many advantages of using it.