

Microservices [1][2][3][4] bedeuten Unabhängigkeit. So legen die Teams los und es entstehen viele Microservices. Nach dem ersten Problem in Produktion wird klar: Alle Microservices brauchen Logging, Monitoring und Tracing. Um Angriffen vorzubeugen, muss die Kommunikation außerdem authentisiert und verschlüsselt werden. Eine weitere Herausforderung ist, die Services vor den Effekten von jederzeit möglichen Netzwerk- oder Service-Ausfälle zu schützen.
Keine Microservices-Frameworks bitte!
Was tun? Für Entwickler liegt es nahe, technische Probleme mit einem Framework zu lösen. Ein Microservices-Framework hat jedoch den Nachteil, dass es nur eine bestimmte Programmiersprache unterstützt. Das schränkt die Auswahl der Implementierungstechnologien für die Microservices ein. Damit gibt das Team eine große Stärke der Microservices auf, nämlich die Technologie-Freiheit. Diese Freiheit erlaubt es, für jeden Microservice die beste Technologie zu wählen. Wenn ein anderer Technologie-Stack oder eine Programmiersprache für ein Detail-Probleme in einem System besser geeignet ist, dann kann man diese Technologie einfach in dem Microservice für diese Detail-Probleme einführen. Wenn die Microservices-Bibliothek mit der neuen Programmiersprache oder dem neuen Technologie-Stack inkompatibel ist, dann ist dieser Weg leider unmöglich.
Auch für einen einheitlichen Technologie-Stack ergibt die Technologie-Freiheit Vorteile. Jeder Technologie-Stack veraltet früher oder später. Durch die Technologie-Freiheit kann ein Update auf einen neue Version des Technologie-Stacks oder einer Bibliothek zunächst in einem einzigen Microservice umgesetzt werden, was das Risiko minimiert. So helfen Microservices dabei, ein System risikoarm modern zu halten. Wenn nun das Microservices-Framework mit der neuen Version des Technologie-Stack oder der Bibliothek inkompatibel ist, dann ist das Update entweder erschwert und völlig unmöglich.
Unabhängig davon, ob die technischen Herausforderungen mit Microservices-Frameworks oder anders gelöst werden, hat die Entscheidung erhebliche Konsequenzen. Der Netflix-Stack enthält beispielsweise die Java-Bibliothek Hystrix, mit der die Kommunikation zwischen Microservices bei Ausfällen einzelner Microservices abgesichert werden kann. Leider pflegt Netflix diese Bibliothek aber mittlerweile nicht mehr. So wird Code, der diese Bibliothek nutzt, plötzlich zu veraltetem Code, der so umgeschrieben werden muss, dass er die Bibliothek nicht mehr nutzt.
Was ist ein Service Mesh?
Microservices, die ein Service Mesh nutzen, können auf viele Bibliotheken verzichten. Dazu gehören insbesondere Monitoring-, Tracing- und Circuit-Breaking-Bibliotheken, die bisher von allen Microservices benötigt wurden. Ein Service Mesh hebt diese und weitere Funktionen aus der Anwendungsebene in die Infrastruktur. Es ist bei weitem nicht das erste Konzept mit diesem Ziel, aber das erste, das dem dezentralen Ansatz einer Microservice-Architektur folgt. Während andere Lösungen wie API Gateways auf zentralen Komponenten basieren, stellt ein Service Mesh jeder Microservice-Instanz eine zusätzliche Anwendung zur Seite, in der beispielsweise Monitoring und Circuit Breaking implementiert sind. Die Microservice-Instanz und diese Anwendung können über den localhost miteinander kommunizieren. Dieses Pattern wird “Sidecar” (dt. Beiwagen) genannt. Jegliche eingehende und ausgehende Kommunikation der Microservice-Anwendung verläuft über die als Sidecar bereitgestellte Anwendung, die deshalb auch als Service Proxy bezeichnet wird. Um den Verkehr automatisch an die Service Proxys zu lenken, können Netzwerkkonfigurationen vorgenommen werden, sodass die Microservices völlig unverändert bleiben können
Ein Service Mesh besteht, wie Abbildung 1 zeigt, aus zwei Ebenen, einer Control Plane und einer Data Plane. Die Data Plane ist eine dezentrale Ebene, die aus der Menge aller Service Proxys besteht. Diese liefern flächendeckend Daten zum Netzwerkverkehr und stellen sie der Control Plane zur Verfügung. Die Control Plane besteht aus zentralen Komponenten. Sie verarbeitet die von der Data Plane erfassten Daten und konfiguriert die Service Proxys.
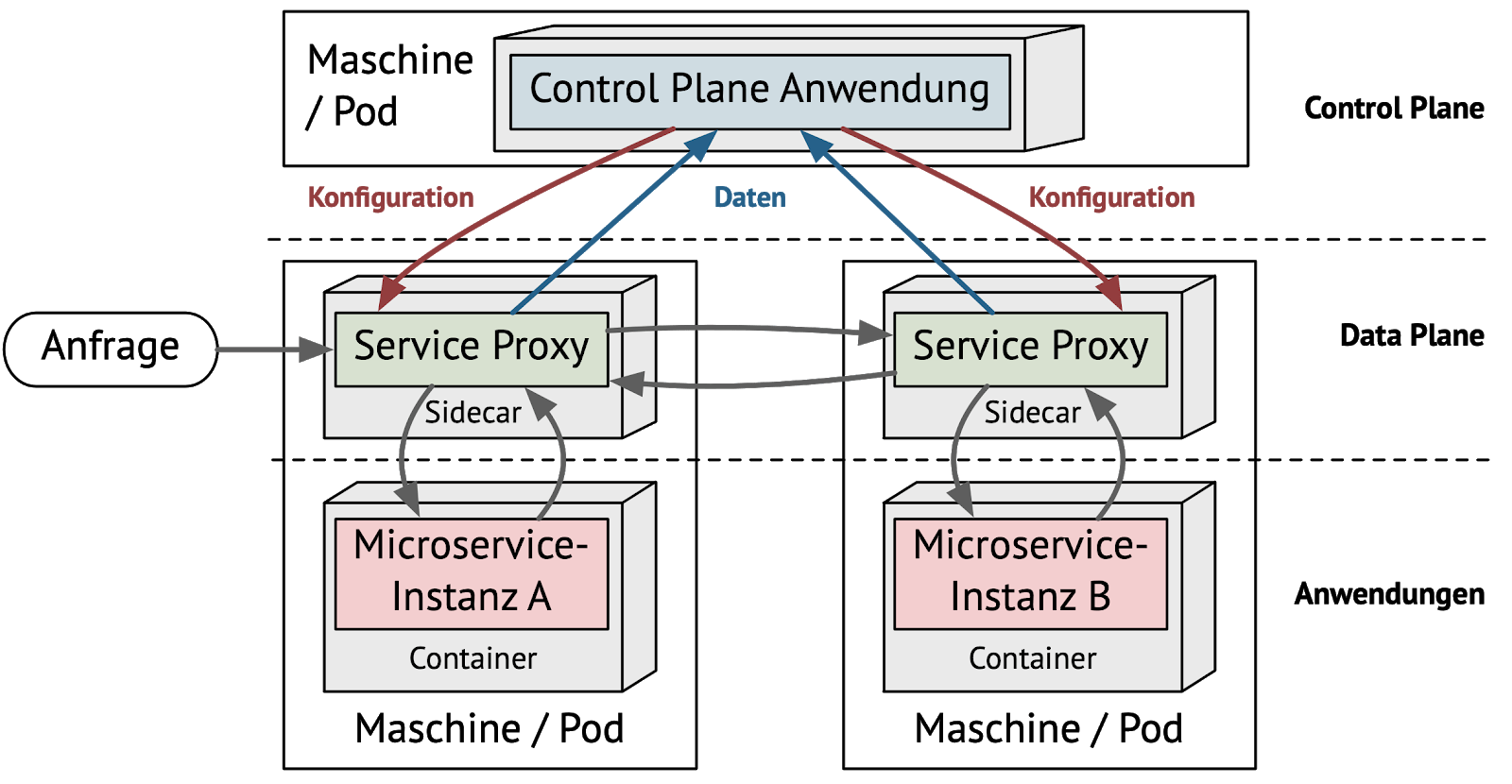
Durch die verteilte Data Plane aus Service Proxys und die zentrale Control Plane, die diese konfiguriert und Daten verarbeitet, kann ein Service Mesh viele Funktionen implementieren:
- Transparenz: Monitoring, Logging und Tracing
- Resilienz: Timeouts, Retrys, Circuit Breaking, Fault Injection
- Routing: A/B-Testing, Canary Releasing
- Sicherheit: Authentifizierung, Verschlüsselung und Autorisierung
Marktüberblick
Die Aufmerksamkeit, die das Thema erhält, hat zu einer Vielzahl von Service Mesh Implementierungen geführt, von denen viele allerdings noch unausgereift sind oder sehr wenige Funktionen umfassen. Bemerkenswert ist, dass alle großen Cloud-Anbieter Service Meshes in Form eigener Produkte (z.B. AWS App Mesh oder Add-ons für existierende Service Meshes anbieten. Die erste Implementierung eines Service Mesh ist Linkerd, dessen zweite Version aus Performance- und Komplexitätsgründen vollständig neu implementiert wurde. Anders als Istio, das zwar für Kubernetes optimiert, aber nicht darauf beschränkt ist, ist Linkerd 2 ausschließlich für Kubernetes verfügbar. In Linkerd 2 ist bisher nur ein Teil der Features implementiert, die Istio umfasst. Linkerd 2 unterstützt weder Tracing noch Möglichkeiten, Regeln für das Routing, Circuit Breaking und Autorisierung zu formulieren. Ähnliche Einschränkungen hat das erst im März produktionsreif verfügbare App Mesh von AWS. Consul, ursprünglich eine Service Discovery Lösung, bezeichnet sich heute als Service Mesh. Allerdings implementiert Consul aktuell lediglich die Sicherheits-Features eines Service Mesh.
Das Istio Service Mesh
Das mit Abstand populärste Service Mesh ist Istio. Es wird beispielsweise von Google Cloud, IBM Cloud und Cloud Foundry als Add-on integriert. Wie auch der Container-Orchestrierer Kubernetes ist es aus einem internen Projekt von Google entstanden. Neben Google tragen auch IBM und der Uber-Konkurrent Lyft von Beginn an zu dem Open Source Projekt bei. Damit haben sich einige der wichtigsten Spieler im IT-Bereich hinter der Technologie versammelt.
Die aktuell primär unterstützte Umgebung für Istio ist Kubernetes. Allerdings ist Istio auch mit Nomad und Consul kompatibel und soll zukünftig noch flexibler werden. Istio basiert zum großen Teil auf bewährten Tools wie dem Monitoring-System Prometheus, dem Dashboard Grafana, dem Tracing-System [Jaeger] (https://www.jaegertracing.io/) und dem Service Proxy Envoy, der für die Sidecars genutzt wird. Die Data Plane in Istio besteht aus adaptierten Envoy Proxys, durch die der gesamte Netzwerkverkehr geleitet wird. Die Control Plane von Istio ist der eigentliche Kern des Istio Service Mesh. Sie ermöglicht die Anbindung von Infrastruktur-Backends wie Prometheus und verteilt die Konfiguration für beispielsweise Routing, Authentifizierung und Circuit Breaking auf die Sidecars.
Das Beispiel
Die Frage ist nun, wie sich Istio auf ein konkretes Projekt auswirkt. Auf Github steht eine beispielhafte Anwendung bereit, die mit Istio implementiert ist. Das Beispiel hat eine ausführliche Anleitung, mit der es recht einfach in einer eigenen Umgebung zum Laufen gebracht werden kann, um Erfahrungen mit den wesentlichen Features von Istio zu sammeln.
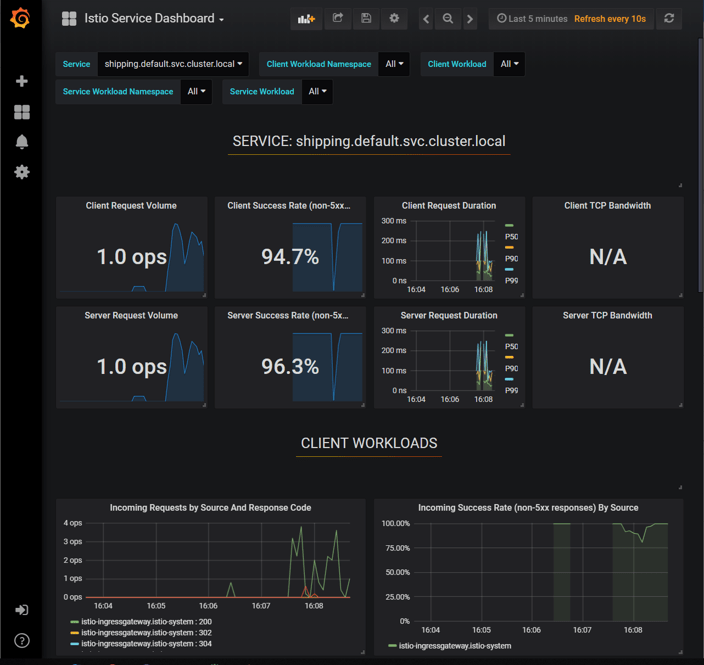
Konkret löst das Beispiel die Microservices-Herausforderungen folgendermaßen:
- Für das Monitoring kann Istio Latenzzeiten, die Anzahl der Requests und die Anzahl der Fehler mit dem Proxy messen. Der Proxy versteht HTTP und kann daher durch die HTTP Status Codes entscheiden, ob es in dem System zu einem Fehler gekommen ist. Die Daten schickt Istio dann an Prometheus. Grafana greift auf die Daten zu und bietet gleich Dashboards für die Services an (siehe Abbildung 2). Istio kann so das Verhalten eines Microservice aus Nutzersicht anzeigen. Der Nutzer nimmt vor allem Fehler und langsame Antworten wahr. Diese Metriken sind also besonders wichtig. Dazu ist keine Zeile Code notwendig. Die Microservices könnten natürlich zusätzlich weitere interne Metriken, zum Beispiel zu Thread Pools oder Database Connection Pools, zugänglich machen. Grafana und Prometheus sind in einer Standardinstallation von Istio enthalten.
- Tracing zeigt an, wie ein Aufruf eines Microservices weitere Microservices aufruft. Istio nutzt zur Visualisierung Jaeger. Istios Proxys können dazu die Aufrufe abfangen und dem Tracing zugänglich machen. Im Code müssen allerdings HTTP Header aus dem eingehenden HTTP Request in alle ausgehenden Requests kopiert werden. Nur so kann Jaeger erkennen, welcher Request welchen Request erzeugt hat. Auch Jaeger installiert Istio gleich mit.
- Für Logging könnte Istio HTTP Requests in ein Log schreiben. Für eine Fehlersuche ist das aber bei weitem nicht ausreichend. Im Beispiel ist das Logging daher vollständig selbst implementiert: Wenn etwas wichtiges passiert, wird ein Log-Eintrag geschrieben. Das Beispiel nutzt die Istio-Features für Logging nicht.
- Für Resilience zeigt das Beispiel, wie Aufrufe mit einem Timeout nach einiger Zeit abgebrochen werden können, damit der Microservice nicht blockiert. Retrys ermöglichen es, Requests zu wiederholen, um so einen vorübergehenden Ausfall zu kompensieren. Circuit Breaker (deutsch: Sicherung) brechen Requests ab, wenn der Ziel-Microservice unter hoher Last steht, so dass der Ausfall des Microservices abgewendet wird.
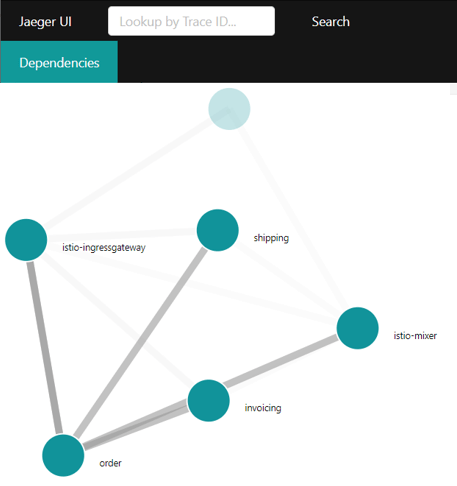
Die Bereiche Monitoring, Tracing und Reslience kann Istio also in der Beispielanwendung abdecken. Dabei muss der Microservice nur für das Tracing HTTP Header von den eingehenden Requests in die ausgehenden Requests kopieren. Das ist im Beispiel mit der Bibliothek Spring Cloud Sleuth und einer Zeile Konfiguration implementiert, könnte aber natürlich auch anders implementiert werden. Die Technologie-Unabhängigkeit ist also gewährleistet. So löst Istio diese Probleme mit minimalem Aufwand für die Entwickler. Noch nicht einmal die Kubernetes-Konfigurationen müssen angepasst werden. Und auch die Werkzeuge zur Visualisierung installiert Istio gleich mit. Zumindest für das Beispiel hilft Istio jedoch beim Logging nicht.
Weitere Features von Istio
Der Funktionsumfang von Istio geht aber noch sehr viel weiter. Beispielsweise können die Sidecars automatisch wechselseitig authentifizierte TLS-Verbindungen (mutual TLS / mTLS) auf- und abbauen und somit die Kommunikation zwischen den Microservice-Instanzen authentifizieren und verschlüsseln. Auch in diesem Fall ist keine Änderung am Code der Microservices nötig. Istio implementiert außerdem ein rollenbasiertes Zugriffssystem (Istio RBAC), mit dem Autorisierungsregeln für Endnutzer und Services formuliert und durch die Envoy Proxys angewendet werden können.
Um zwei Versionen einer Anwendung in einem A/B-Test zu vergleichen, können in Istio Routing-Regeln definiert werden, die den Netzwerkverkehr auf mehrere Versionen einer Anwendung verteilen. Routing-Regeln können sogar auf Basis von HTTP-Headern oder der URL formuliert werden. Damit kann Istio auch beim Canary Releasing, das schrittweise, kontrollierte Einführen von neuen Versionen, unterstützen. Benutzer können z.B. nach verwendetem Browser unterschieden werden und sehen dann die neue oder alte Versionen der Website. Ebenso kann ein bestimmter, zufälliger Anteil der Benutzer die neue Version bekommen.
In der Praxis laufen nicht alle Anwendungen in einem Kubernetes Cluster. Eines der neuesten Features von Istio ist deshalb die Kontrolle und Beobachtung des Netzwerkverkehrs über ein Cluster hinaus. Zum einen können Services einbezogen werden, die in virtuellen oder physischen Maschinen laufen. Zum anderen können mit Istio mehrere Kubernetes-Cluster verbunden werden.
Der Haken
Viele Service Mesh Implementierungen wie Istio sind produktionsreif, werden von einem kompetenten Team entwickelt und decken einen bemerkenswerten Funktionsumfang ab. Es scheint fast zu gut um wahr zu sein - wäre da nicht der Lernaufwand, der zusätzliche Ressourcenverbrauch und die erhöhte Latenz.
Ein Service Mesh muss konzeptionell verstanden werden, um entscheiden zu können, ob es sich für eine Anwendung lohnt und welche Technologie am geeignetsten ist. Anschließend steht dem Entwicklungsteam die komplexe Aufgabe der Konfiguration des Service Mesh bevor.Neben dem mentalen gibt es auch technischen Mehraufwand. Die Komponenten der Control Plane und die zusätzlichen Service Proxys, die jedem Container zur Seite gestellt werden, benötigen zusätzliche CPU- und Arbeitsspeicherressourcen, die sich wiederum auf die Kosten für den Betrieb des Clusters auswirken. Der konkrete Mehrbedarf an Ressourcen hängt von der Anzahl der Anfragen und vom Service Mesh Produkt und dessen Konfiguration ab. Unsere Untersuchungen haben gezeigt, dass Istio mehr Ressourcen benötigt als Linkerd 2.
Ein weiterer Nachteil eines Service Mesh sind die Latenzeinbußen, die sich auf das Erlebnis der Endnutzer auswirken können. Die höhere Latenz entsteht durch den zusätzlichen Aufruf der Service Proxys bei jeder Anfrage. Denn statt einem direkten Aufruf zwischen Containern sind in einem Service Mesh nun zwei Proxys - auf Sender- und Empfängerseite - beteiligt. Istio beispielsweise gibt offiziell an, dass 90% der Anfragen eine Verzögerung von 8ms oder weniger aufweisen. Wie unsere Untersuchungen gezeigt haben, ist der Wert ist jedoch stark abhängig von dem konkreten Microservice-System und von der Istio-Konfiguration. Wenn Latenz ein wichtiger Faktor ist, muss die Latenz ohne und mit Istio gegebenenfalls in einem Testcluster verglichen werden, bevor Istio ins Produktionssystem Einzug erhält.
Fazit
Ein Service Mesh scheint den Technologie-Stack für Microservices perfekt zu machen. Es ermöglicht die zentrale Kontrolle von Monitoring, Resilienz, Routing und Sicherheit, die dezentral in den Sidecars umgesetzt werden. Damit fügt sich ein Service Mesh harmonisch in Microservice-Architekturen ein und kann API Gateways und viele Bibliotheken ersetzen. Istio als bekanntester Vertreter eines Service Mesh kann seine Stärken vor allem in Kubernetes-Umgebungen ausspielen, erlaubt aber auch, einzelne virtuelle Maschinen oder Container einzubinden.
Der Preis eines Service Mesh ist der Aufwand für die Einführung neuer Technologien, ein erhöhter Ressourcenverbrauch und eine höhere Latenz. Im konkreten Fall müssen diese Auswirkungen untersucht und Vor- und Nachteile abgewogen werden. Doch da es für Microservice-Systeme keine eleganteren Alternativen gibt, wird wohl kein Weg an einem Service Mesh vorbei führen.
Links & Literatur
-
Eberhard Wolff: Microservices: Grundlagen flexibler Softwarearchitekturen, 2. Auflage, dpunkt, 2018, ISBN 978–3864905551 ↩︎
-
Eberhard Wolff: Das Microservices-Praxisbuch: Grundlagen, Konzepte und Rezepte, dpunkt, 2018, ISBN 978–3864905261 ↩︎
-
Eberhard Wolff: Microservices Rezepte - Technologien im Überblick, kostenlos unter https://microservices-praxisbuch.de/rezepte.html ↩︎
-
Eberhard Wolff: Microservices - Ein Überblick, kostenlos unter https://microservices-buch.de/ueberblick.html ↩︎