
Title: Progressive Web Components
Author: fnd
Date: 2016–12–02
keywords: web, goto, progressive
published_at: 2016–12–02
A couple of weeks ago, Stefan and I gave a talk titled “Progressive Web Components” at GOTO Berlin.
Here’s an abridged write-up. Consider this an approximation of the way I would have liked to present it.

I should preface this by saying that I appreciate the positive influence various single-page application frameworks have had on the web platform: They’ve been advancing the state of the art and put evolutionary pressure on the platform.
Having said that, you shouldn’t actually be using them.

Browsers have given us all this power — and what do we do? We turn around and abuse it, to the point that websites are now actually slower and more brittle than they used to be.
It’s really quite disheartening.
Any sufficiently complicated JavaScript client application contains an ad-hoc, informally-specified, bug-ridden, slow implementation of half a browser.
Stefan Tilkovwith apologies to Philip Greenspun
It’s now commonplace for applications to ship code that does a whole bunch of things that go way beyond application-level concerns. They’re essentially reinventing the browser in userland.
While it’s nice that JavaScript can serve as this escape hatch — allowing us to experiment with concepts beyond what the platform originally imagined — this does create real problems in practice.
Hard to put into words how utterly broken JS-first web development is. So many parts of the system work against you when you take the reins.
Alex Russell
If you’re wresting control from the browser, you assume responsibility for a whole range of things which are normally handled by the platform.
Not only does this lead to ballooning complexity on the developer side, it also means we’re being irresponsibly wasteful of end users' limited resources — be it CPU, memory, battery or bandwidth.
Processing hundreds of kilobytes of JavaScript is still expensive today. This whole situation is part of the reason Google felt compelled to come up with Accelerated Mobile Pages (AMP).
Alex Russell is one of Google’s developer evangelists — but you should listen to him anyway. In particular, he’s been very vocal recently about the impact all this has on mobile devices.
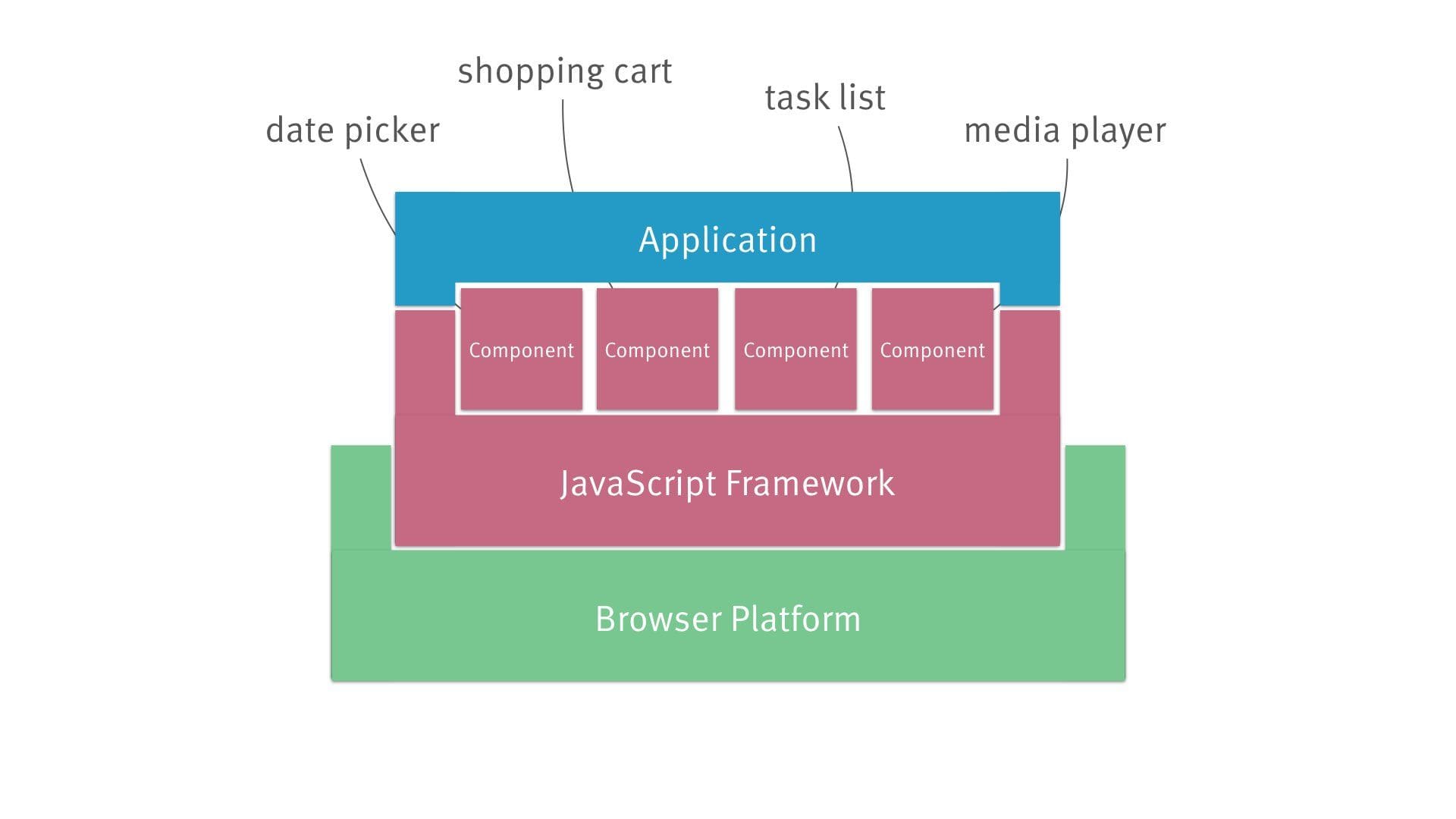
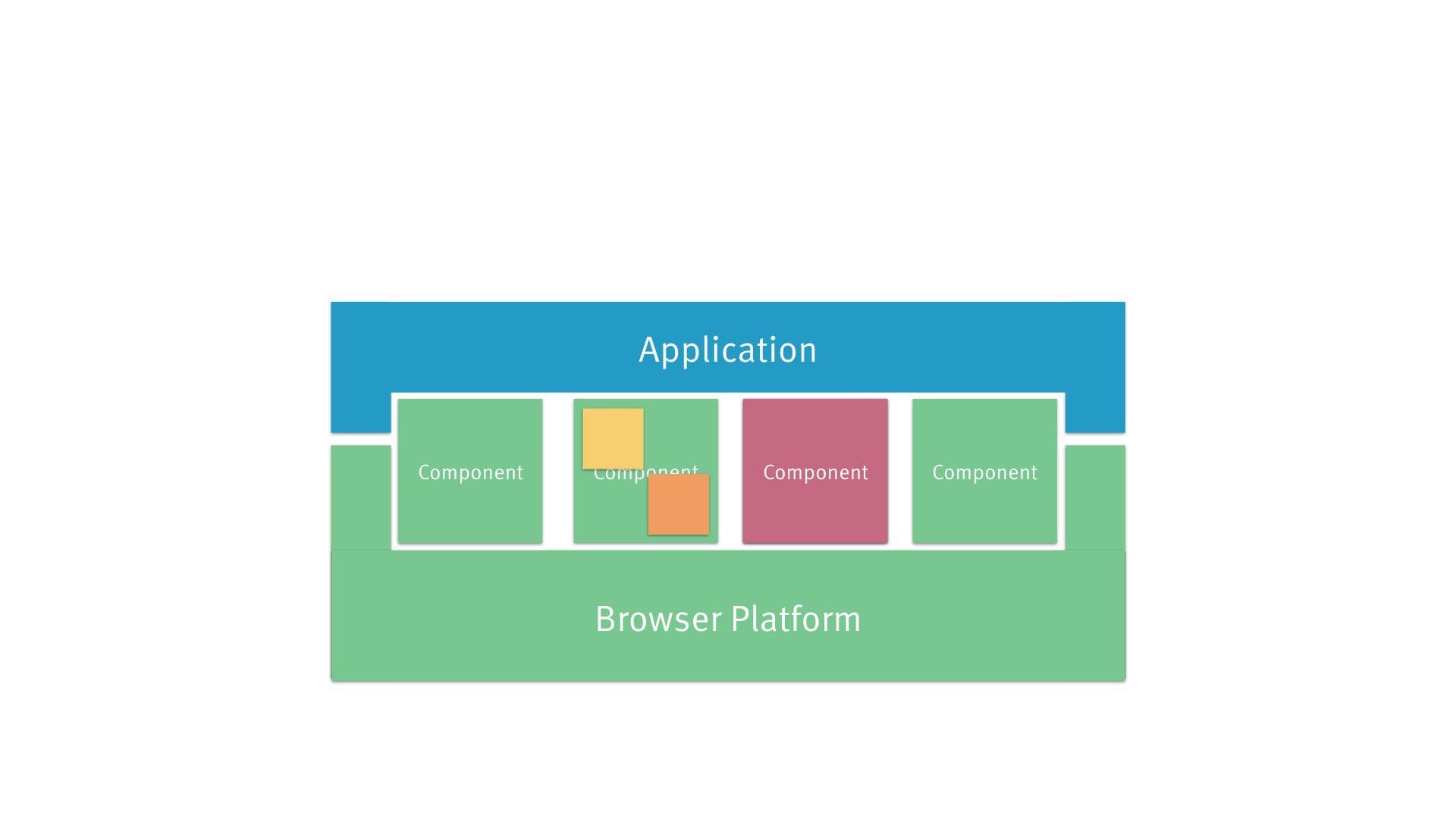
So this is what it looks like from an architectural perspective:
- The browser serves as runtime environment…
- … with your JavaScript framework sitting on top.
- It’s pretty much consensus now that a component-based approach is the way to go.
- Plus there’s application logic on top, tying it all together.

But let’s step back a bit here: The browser already provides us with a native component model — and it even comes with a nicely declarative syntax.

The tag name serves as the main identifier.

Attributes and properties are used as parameters.

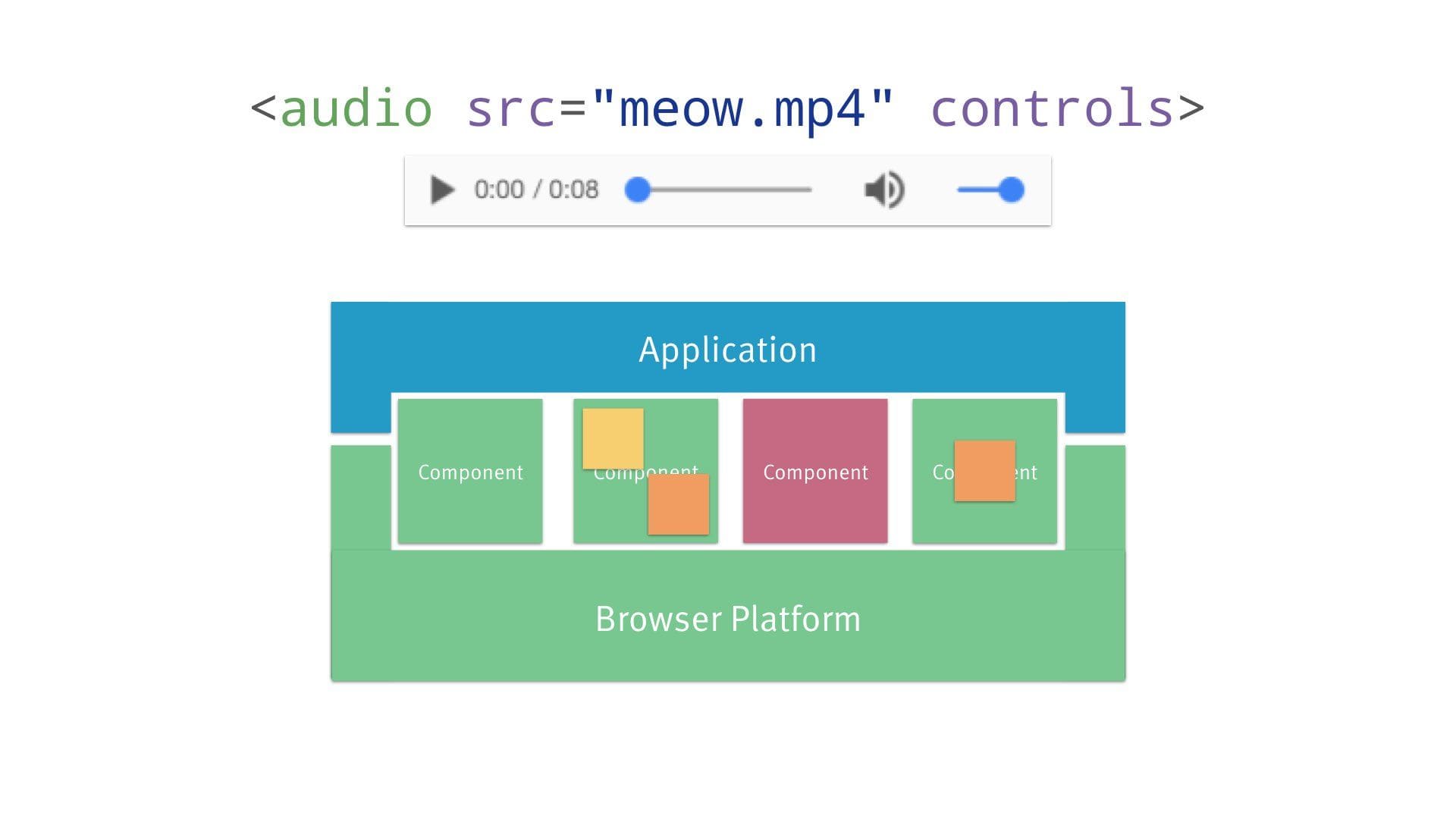
<video src="bunny.mp4" controls>
<track kind="subtitles" …>
</video>You can even use child elements for more complex parameters.
All this isn’t unlike a function signature. It’s the native way to control data flow.

On top of that, you also get event notifications. In fact, the DOM’s pub/sub mechanism is comparatively powerful, thanks to element scoping and event bubbling.

Of course you also get a regular JavaScript API, so you can call methods on DOM nodes.
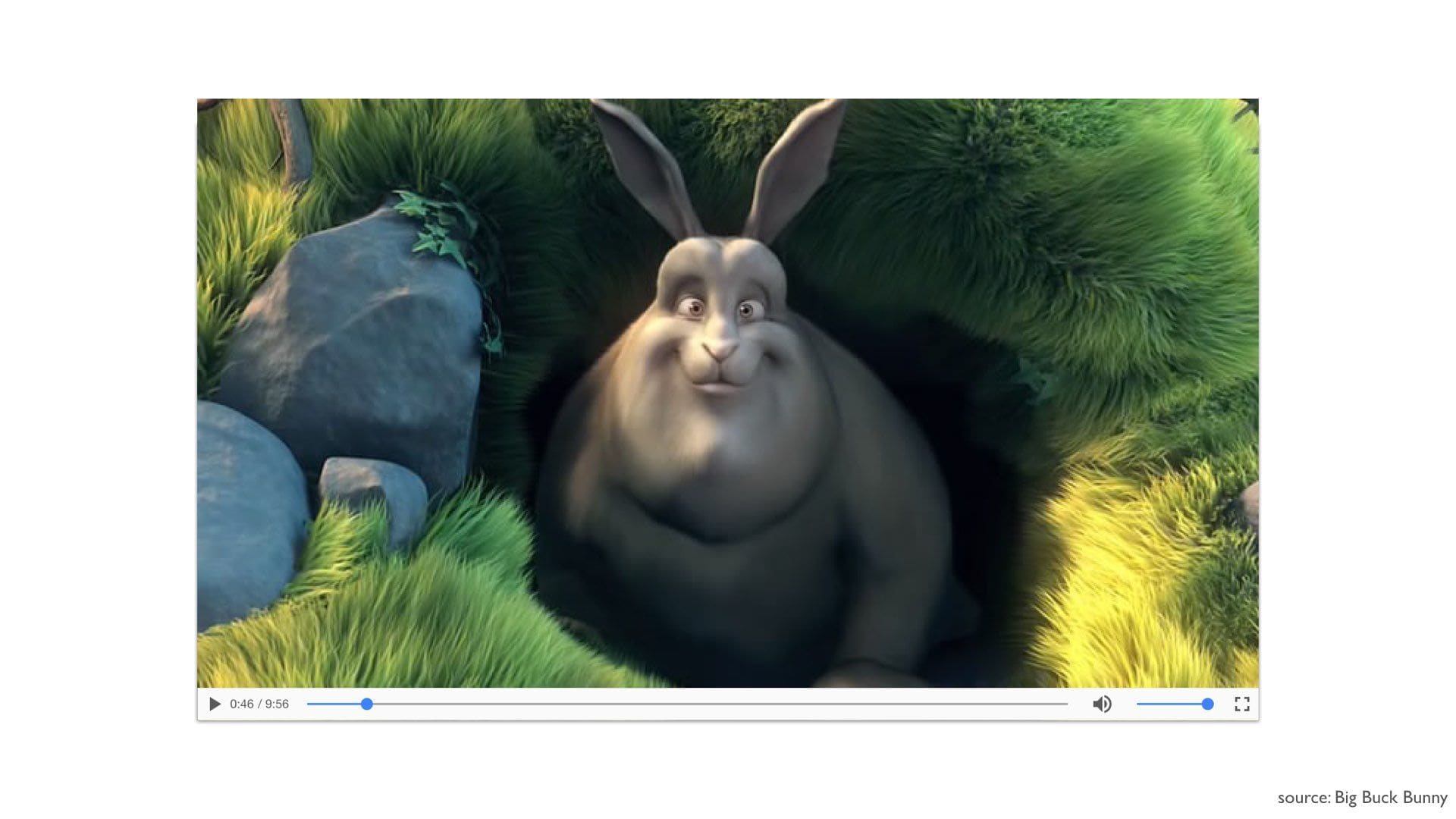
This results in a nicely encapsulated widget — essentially a tiny application within your page.
As an author, you just drop that bit of HTML in there without having to worry about any internals.

So the browser already provides a perfectly cromulent API. There’s really no need to abstract that away, most of the time.
That is why the Polymer folks have adopted this motto, the idea being that you wanna be close to the metal and leverage what’s already there.
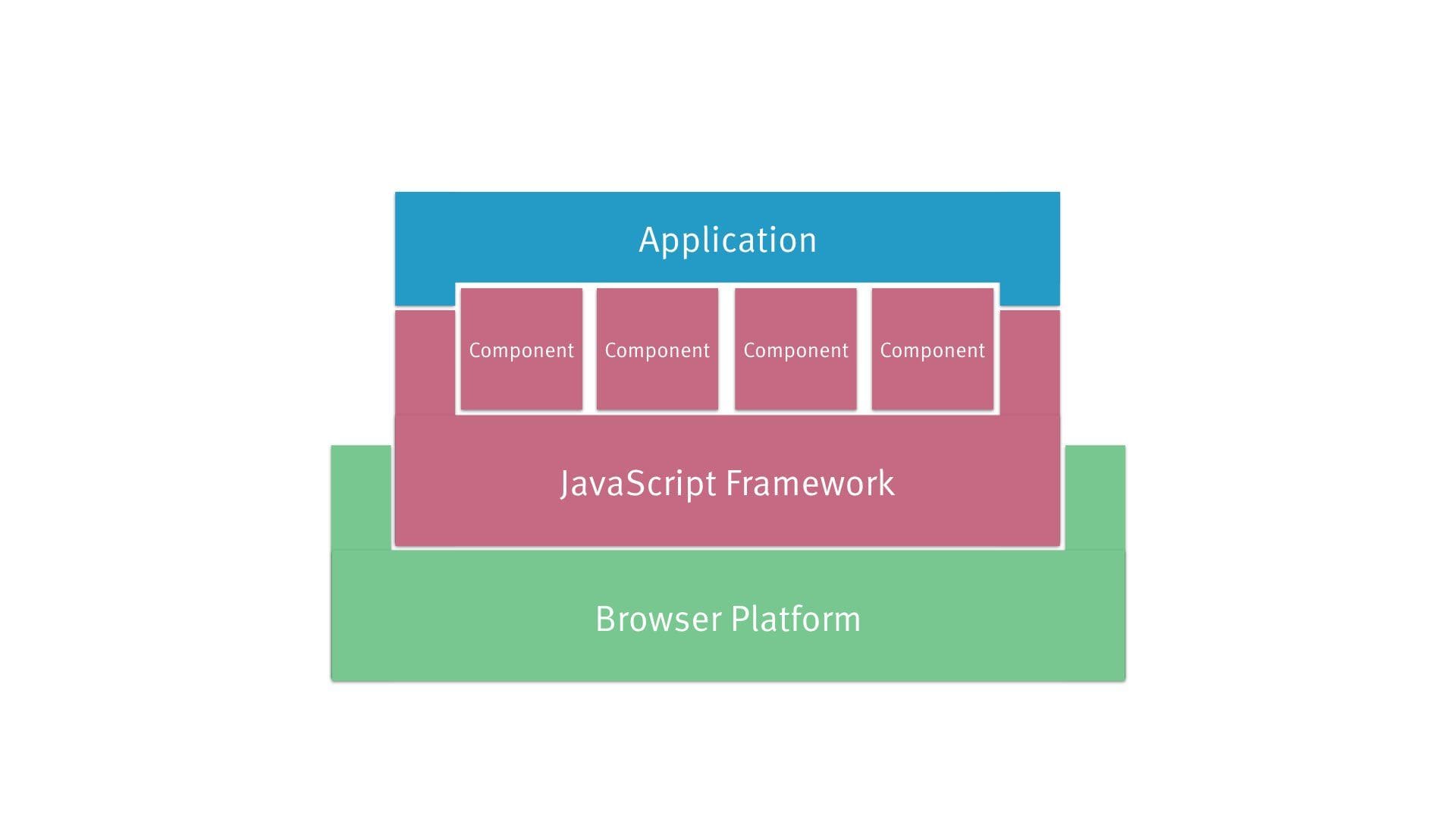
This was our picture from before.
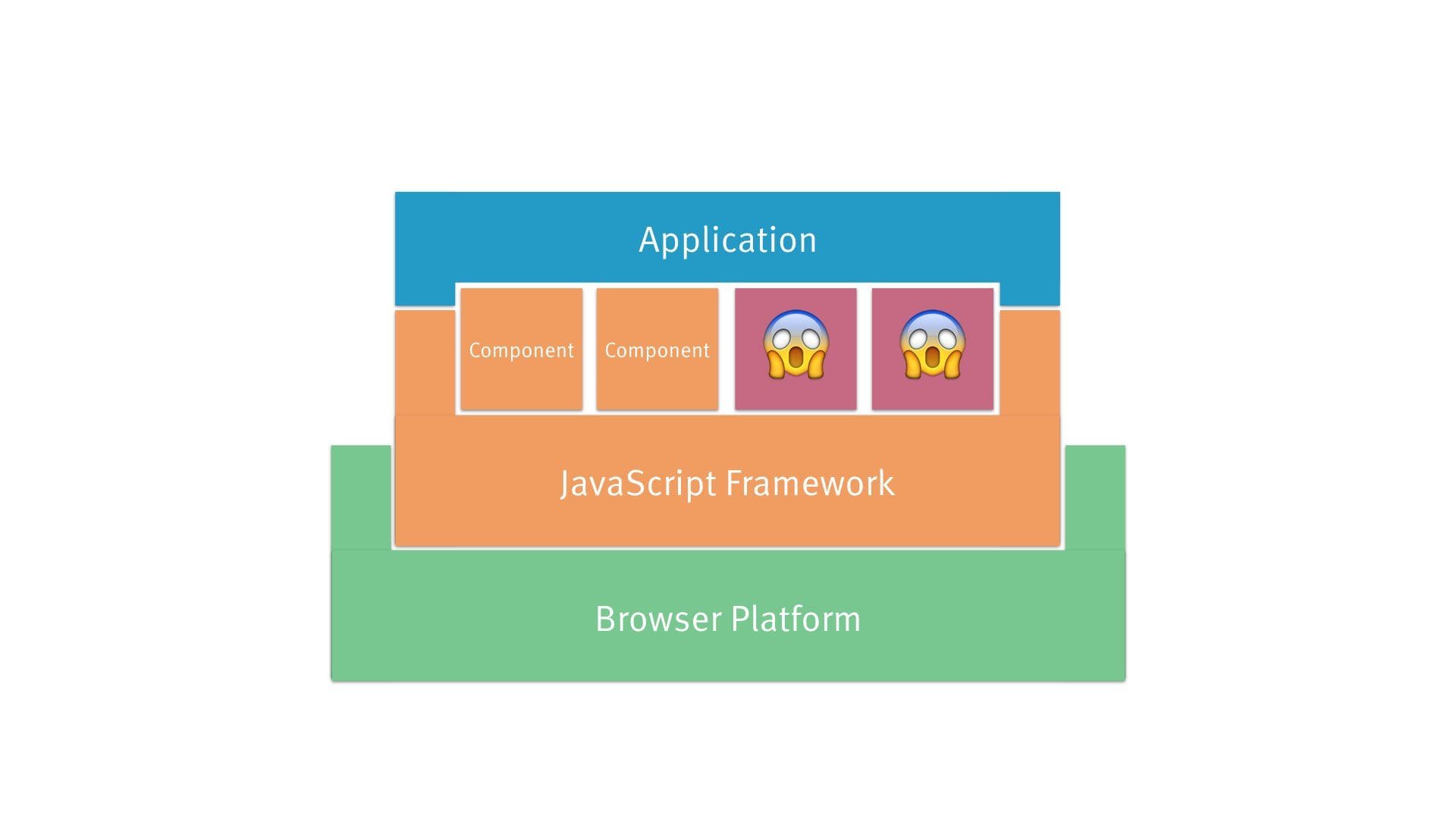
Now, if for some reason, you decide to switch to another framework — e.g. starting a new project — those components you had before are left out in the cold.
That’s because we’re dealing with mutually incompatible, proprietary APIs. Even the fact that these frameworks are usually open source doesn’t save you there.
So why not eliminate the middleman? Let’s just rely on the platform as the native interoperability layer.
Individual components may still opt to use some framework internally. Of course you wanna be careful there, because we’re still operating in a shared environment, so we have to be aware of resource contention. In other words, going native doesn’t absolve you of the responsibility to do quality control.
You can also do composition via nesting; using components within components — the usual matryoshka thing most of IT is built around.
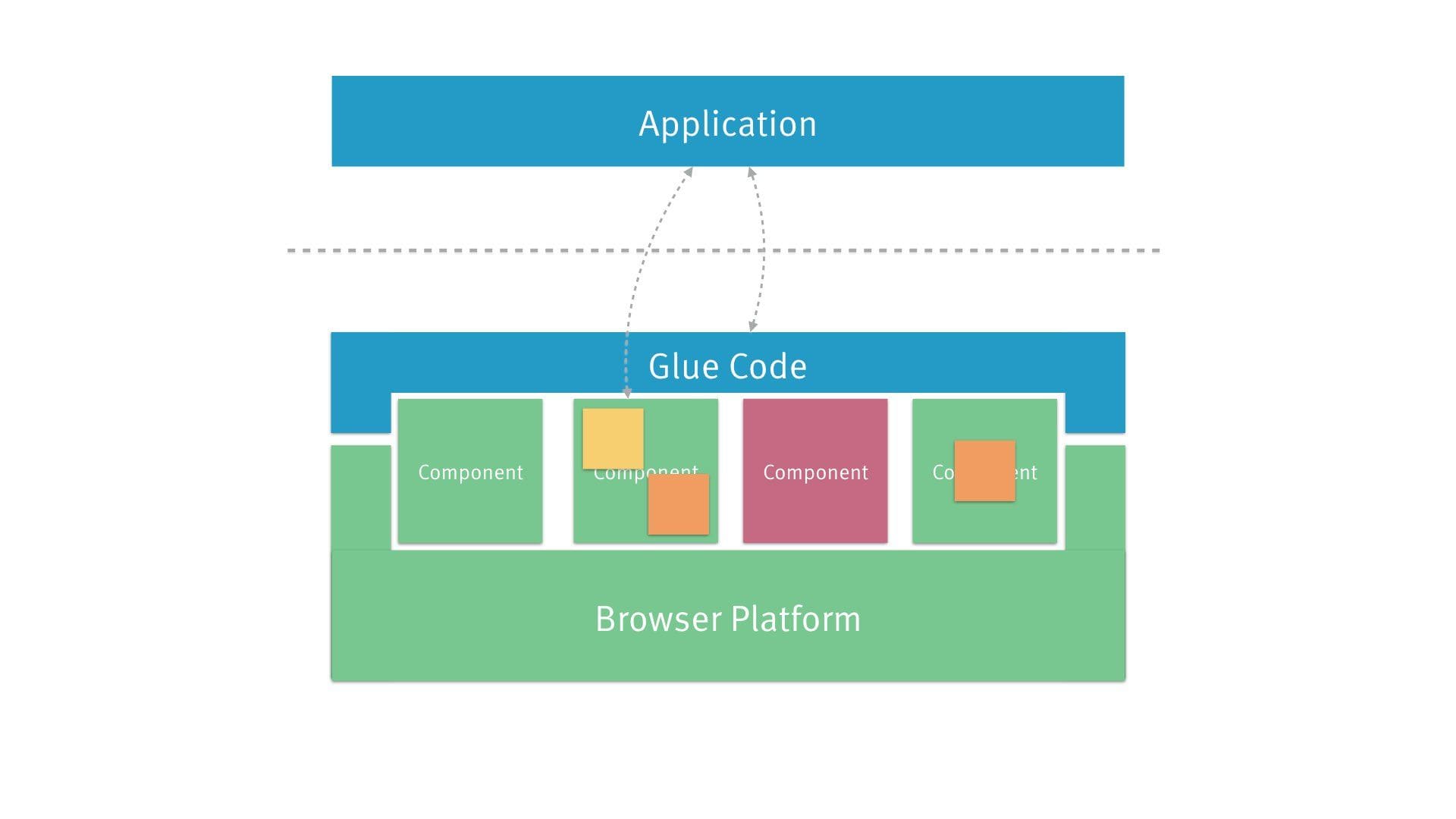
And if you have (more or less) atomic building blocks, you can also share them across components.
In this case, we have a media control bar which internally consists of various
buttons and sliders. That same component is used by the <video> widget we’ve
seen before.
However, we still have a fairly big chunk of application logic at the top.
We can actually reduce the complexity there — simply by offloading it to the server. (It almost seems like a revolutionary idea these days.)
That way, we use the server as our state machine — which effectively means doing hypermedia. And HTML just happens to be an excellent format for that.
Of course none of this is new; we’ve been doing it for like a decade.

<input type="text" class="date">$("input.date").datepicker();We start out with some “base markup” as our foundation, then augment it with JavaScript. (In this case: jQuery UI — which might be a bit dated and not very exciting, but is actually still a fairly decent set of components.)

<div class="tabs">
<ul>
<li> <a href="#about">About</a>
…
<li> <a href="#comments">Discussion</a>
</ul>
<p id="about">lorem ipsum dolor sit amet</p>
…
<ol id="comments"> … </ol>
</div>$(".tabs").tabs();This is actually my favorite example, because it elegantly builds upon existing mechanisms: The navigation items on top just reference other sections within the page.
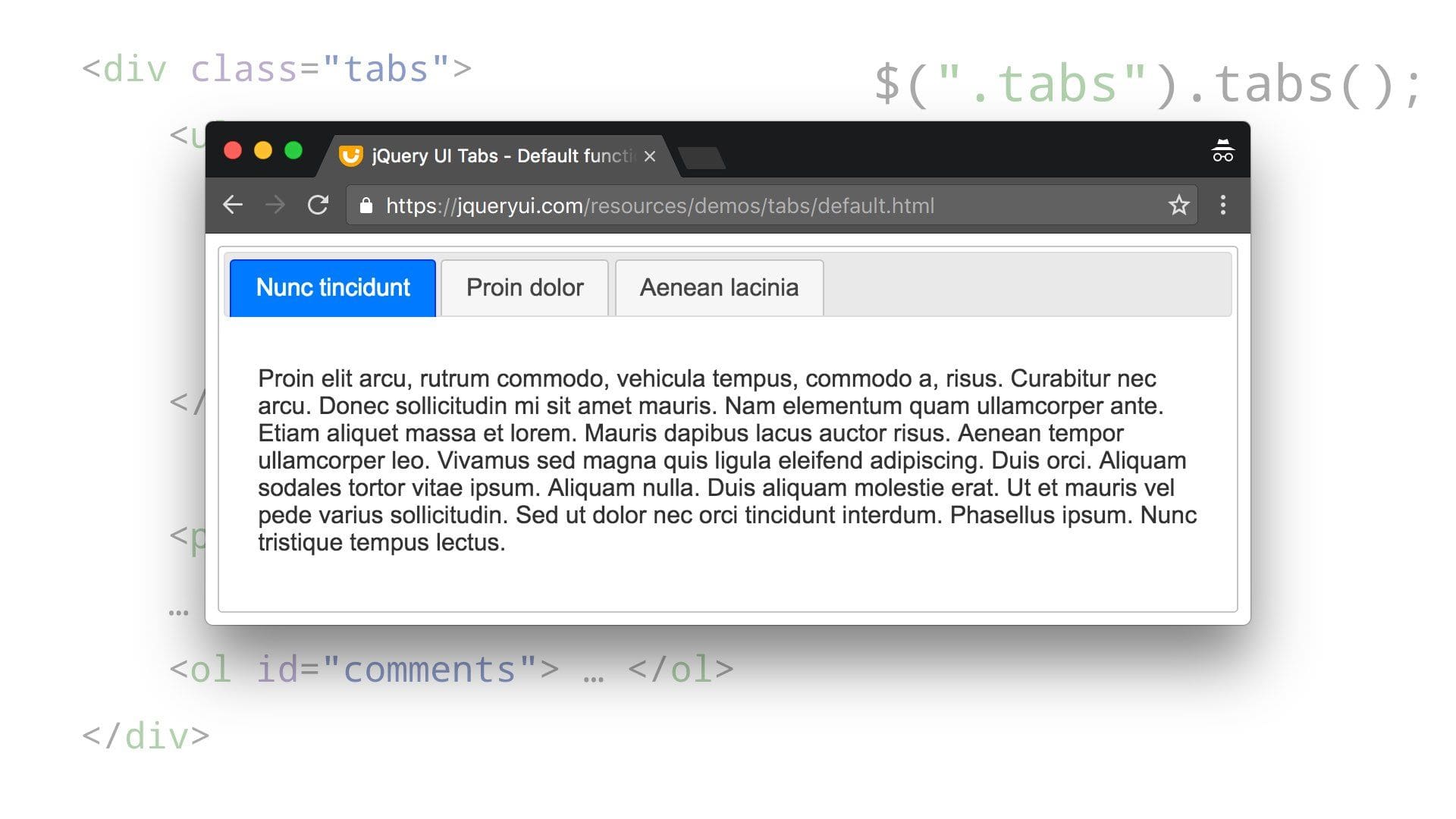
Once augmented with JavaScript, you get a different way to interact with that same content.
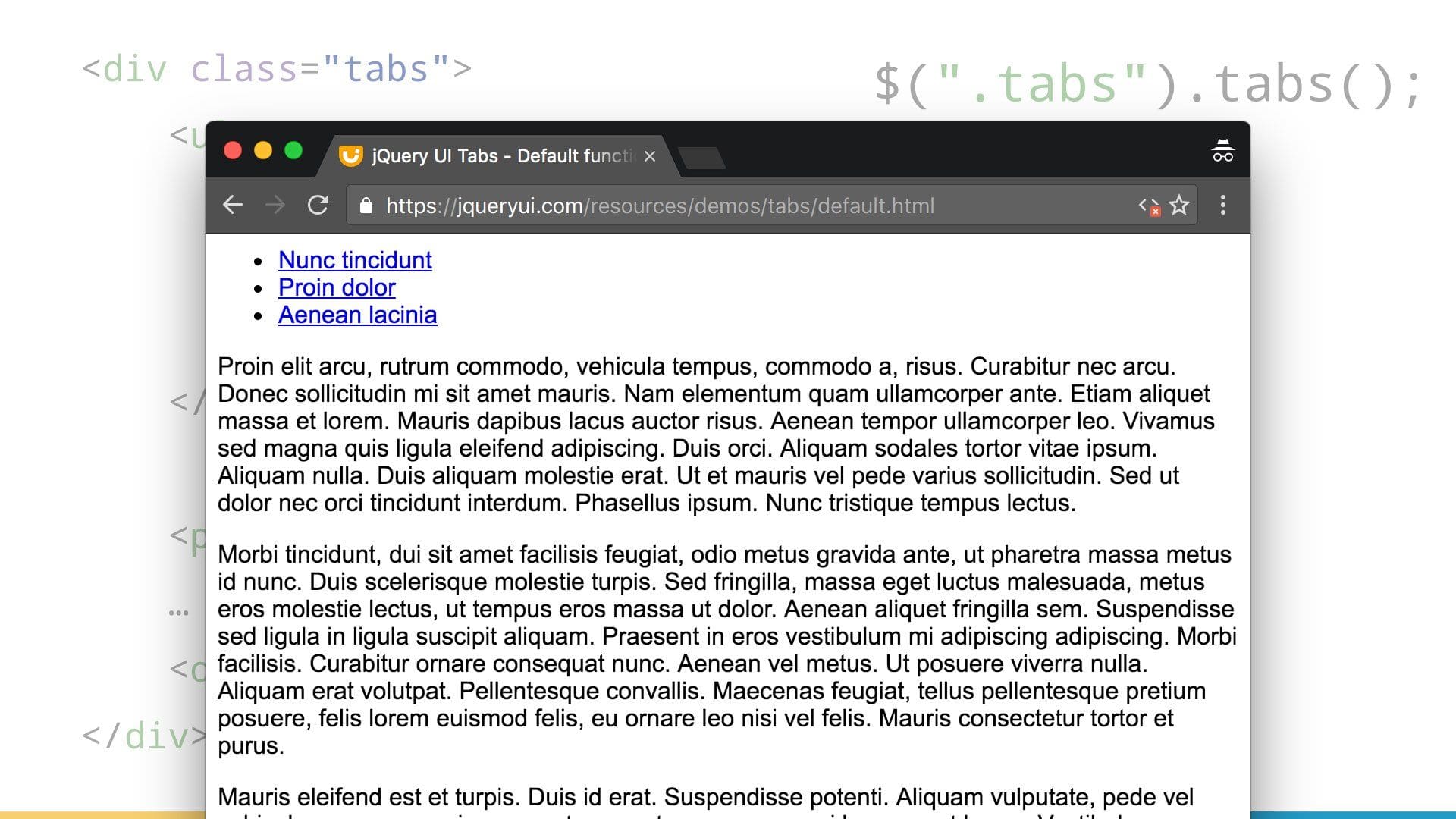
But if, for some reason, that component could not be initialized, we can still get at that content — which is what users really care about.
And we get this for free, by building upon a reliable foundation.
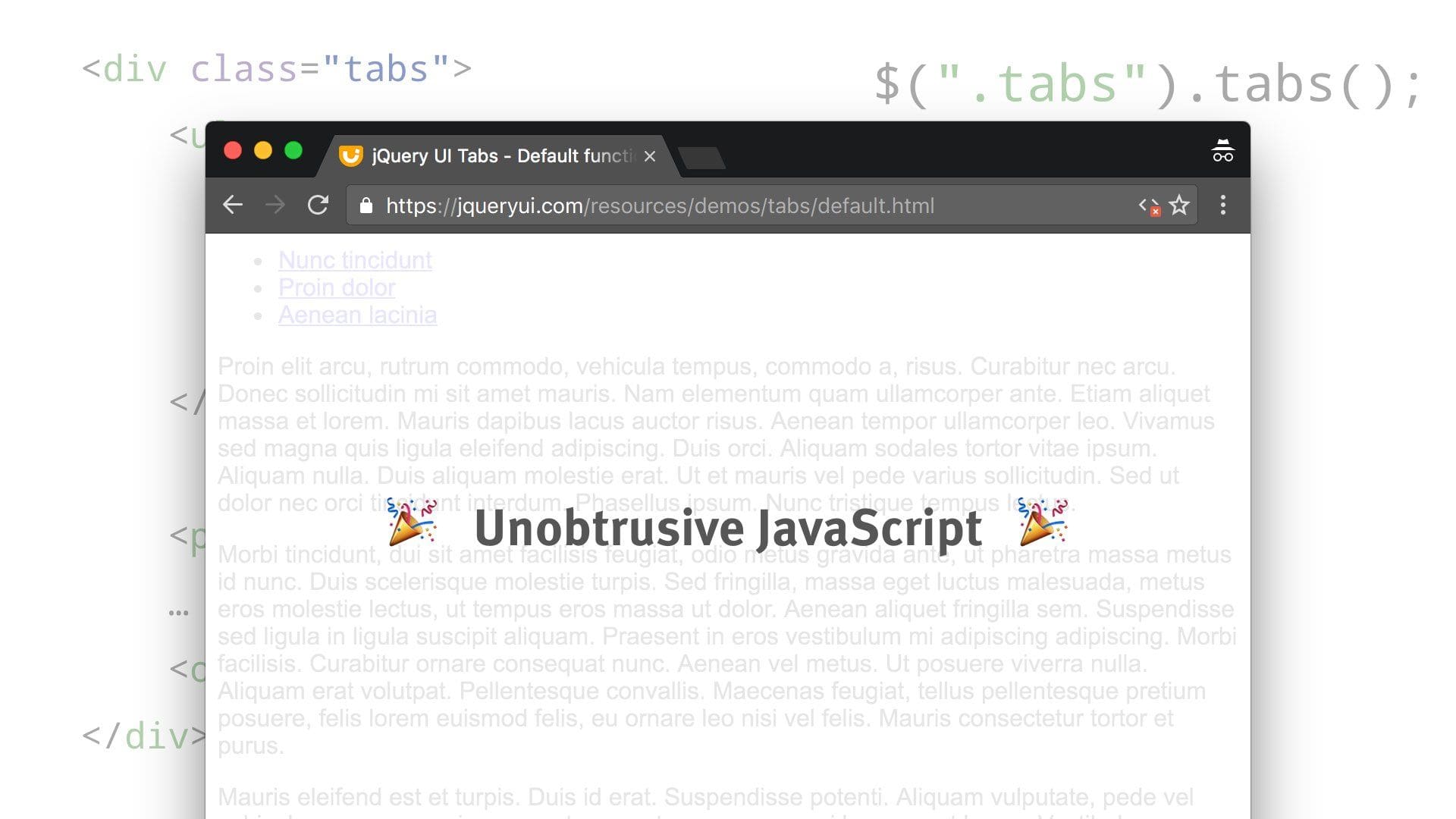
That’s the principle behind unobtrusive JavaScript: It provides improvements if possible, but it doesn’t get in the way.
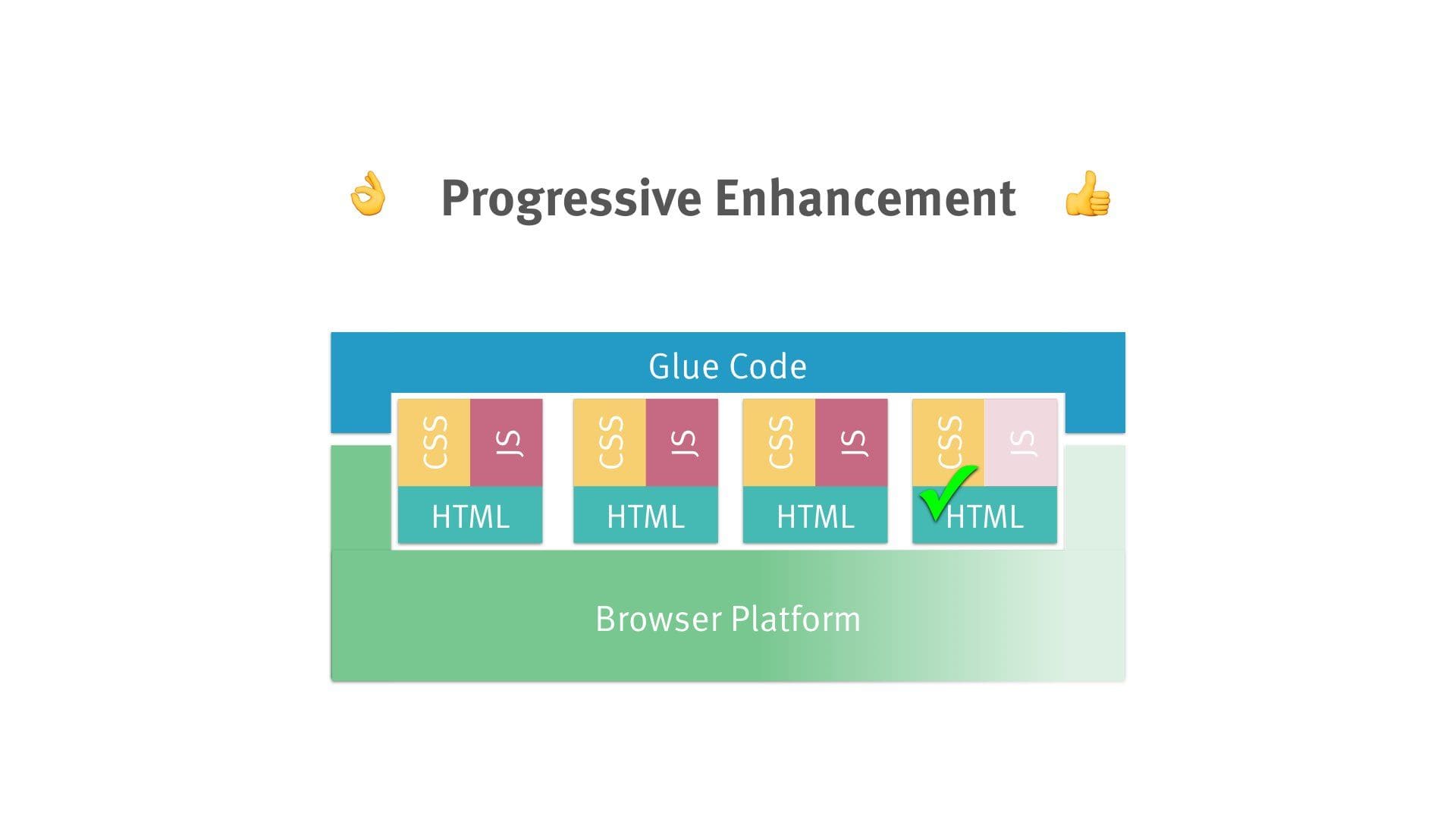
So there are three aspects to each component: HTML, CSS and JavaScript — which constitute the pillars of the web (along with HTTP).
A component is only activated — i.e. augmented with JavaScript — if the prerequisites are met. Note that this is a local decision at the granular level of individual components.
For example, you might have some autocomplete component which uses the new fetch API for doing AJAX. If that’s unavailable, the underlying form still works, you just get the results on a separate page instead of inline.
That’s no accident: It’s one of the core design principles of the web (in particular, look up the Rule of Least Power).
Progressive enhancement is not about dealing with old browsers, it’s about dealing with new browsers.
Jeremy Keith
So the point here isn’t to avoid JavaScript. On the contrary: Because we have this resilient foundation, we can go wild with all the latest features.

<div class="tabs">
<ul>
<li> <a href="#about">About</a>
…
<li> <a href="#comments">Discussion</a>
</ul>
<p id="about">lorem ipsum dolor sit amet</p>
…
<ol id="comments"> … </ol>
</div>$(".tabs").tabs();This is our base markup from before. It’s alright, but there’s room for improvement: We’re kind of abusing the class attribute at the top for our JavaScript binding. Plus it’s all just a little implicit.

<tab-nav>
<ul>
<li> <a href="#about">About</a>
…
<li> <a href="#comments">Discussion</a>
</ul>
</tab-nav>
<p id="about">lorem ipsum dolor sit amet</p>
…
<ol id="comments"> … </ol>$(".tabs").tabs();Wouldn’t it be nice to be more explicit, using our own tag name?

<tab-nav>
<ul>
<li> <a href="#about">About</a>
…
<li> <a href="#comments">Discussion</a>
</ul>
</tab-nav>
<tab-contents>
<p id="about">lorem ipsum dolor sit amet</p>
…
<ol id="comments"> … </ol>
</tab-contents>$(".tabs").tabs();Similarly, we might wanna add a wrapper element at the bottom. However, looking closely, that element we just added seems a little redundant; it’s kind of a pointless wrapper.

<ul is="tab-nav">
<li> <a href="#about">About</a>
…
<li> <a href="#comments">Discussion</a>
</ul>
<tab-contents>
<p id="about">lorem ipsum dolor sit amet</p>
…
<ol id="comments"> … </ol>
</tab-contents>$(".tabs").tabs();After all, it’s really just a list, if a particular kind thereof — essentially a subclass. In fact, the manual initialization up there, that seems a little silly too. Why not just let the browser handle that?

Defining elements like that used to be the prerogative of browsers. But with Custom Elements, one of the pillars of the Web Components standards, that power has been extended to us lowly web developers. It’s been in the making for a number of years now, but it’s finally becoming areality. Chrome has shipped v1, Firefox has implemented it, others are soon to follow. There’s also a fairly lightweight polyfill, which means you can safely retrofit this functionality for older browsers. Thus you can start using Custom Elements right away. (AMP actually uses that polyfill, so it’s already proven itself in the real world.)

customElements.define("task-list");This is what it looks like. You start out by registering your tag name — which must be hyphenated.

class TaskList extends HTMLElement {}
customElements.define("task-list", TaskList);Then you provide an implementation by binding the tag to a prototype. That’s pretty much it.

class TaskList extends HTMLElement {
constructor() { // element created or upgraded
super();
…
}
connectedCallback() { // element inserted into the DOM
…
}
disconnectedCallback() { // element removed from the DOM
…
}
}
customElements.define("task-list", TaskList);Now the browser notifies you of any relevant DOM activity, i.e. if such an element is added to or removed from the DOM. These predefined hooks are called “reactions”.
You can use your custom element even before the corresponding JavaScript is
loaded; the browser will just treat it as a generic inline element (i.e. a
<span>). Once your JavaScript becomes available, those elements will be
“upgraded” accordingly.

class TaskList extends HTMLElement {
…
attributeChangedCallback(attrName, oldVal, newVal) {
…
}
static get observedAttributes() {
return ["theme"];
}
}
customElements.define("task-list", TaskList);You can also receive notifications if an attribute changes. In this case, we might want to apply a visual theme if the corresponding attribute is changed.

class TaskList extends HTMLElement {
…
connectedCallback() {
let obs = new MutationObserver(this.onChange);
obs.observe(this, { childList: true, subtree: true });
}
…
onChange() {
…
}
}
customElements.define("task-list", TaskList);You can also respond to child elements being modified. In our example here, you might want to increase a task counter when list elements are added.
The nice thing there is that the outside world doesn’t necessarily need to be aware of your custom element; it can just use generic list manipulation, maintaining loose coupling.

class TaskList extends HTMLElement {
…
connectedCallback() {
let shadowRoot = this.attachShadow({ mode: "open" });
shadowRoot.innerHTML = "<canvas></canvas>";
…
}
…
}Even if we present ourselves as a simple list in the DOM, we might want to
provide a different visualization to the user — say a bitmap with colored
shapes, based on priority. Indeed, that’s exactly what <video> does: You’re
not exposed to the various <div>s it uses for its UI internally, that’s all
encapsulated.

This is possible thanks to Shadow DOM, another pillar of the set of standards that are collectively known as Web Components. A word of caution though: While it’s increasingly well supported in modern browsers, the polyfill is pretty heavyweight and might negatively impact your performance, so you should carefully consider whether it’s worth using at this point.
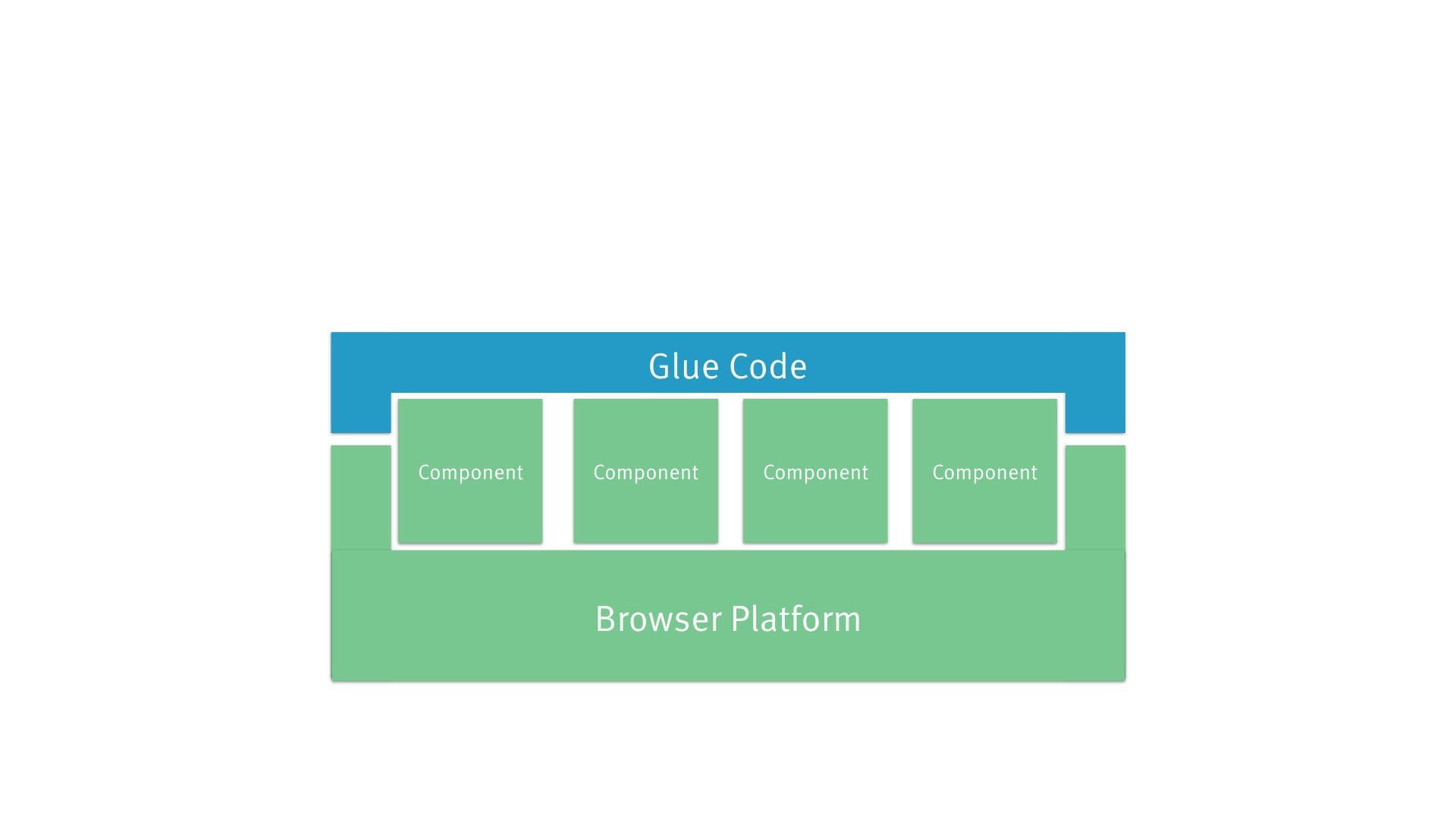
This was our architecture with jQuery-style widgets.
We’ve now further simplified this by pushing life-cycle management into the platform. That architecture might not be very exciting, but avoiding complexity is a Good Thing™!
By relying on the native platform as common denominator, we can remove a whole lot of friction:
For one thing, you can largely avoid the dreaded framework churn. Being familiar with the web’s own APIs means your skills are transferable for the foreseeable future. Indeed, longevity is almost guaranteed: In contrast to proprietary frameworks, web standards are designed to last decades.
You can also build up a set of reusable widgets which remain applicable across projects — both within your organization and across the web.

That landscape is still evolving, but there are promising signs from various libraries — this just might turn out to be the promised land, the culmination of what we’ve been working towards for all these years.
As a final note, Web Components also make for an excellent foundation for living style guides — but that’s a topic for another day.