

Wir haben eine Reihe von Gründen identifiziert, die diese Problematik erklären:
Grund 1: ML Model Deployment ist ein komplexer Prozess. Generell handelt es sich um das Management der drei Pipelines: Data Engineering, Model Engineering und Software Engineering.
Grund 2: Es gibt keine standardisierten Prozesse um ein ML Modell in die Produktionsumgebung zu bringen. Machine Learning Model Operation Management (MLOps) ist immer noch in der Anfangsphase.
Grund 3: Den richtigen Infrastruktur Stack zu definieren um Machine Learning Deployments zu automatisieren erfordert momentan ein “trial & error”-Prozess. Darüber hinaus, sind viele Tools und Systeme für Machine Learning Serving in einer aktiven Entwicklungsphase.
In diesem Artikel erklären wir, wie Continuous Delivery für Machine Learning Modelle funktioniert. Vor allem aber, wie man Data Engineering, Model Engineering und Software Engineering Pipelines in einer CI/CD Pipeline unterbringt. Darüber hinaus möchten wir zeigen, wie man den manuellen Prozess des Deployments von ML Modellen mit DevOps Praktiken automatisiert.
MLOps Lebenszyklus
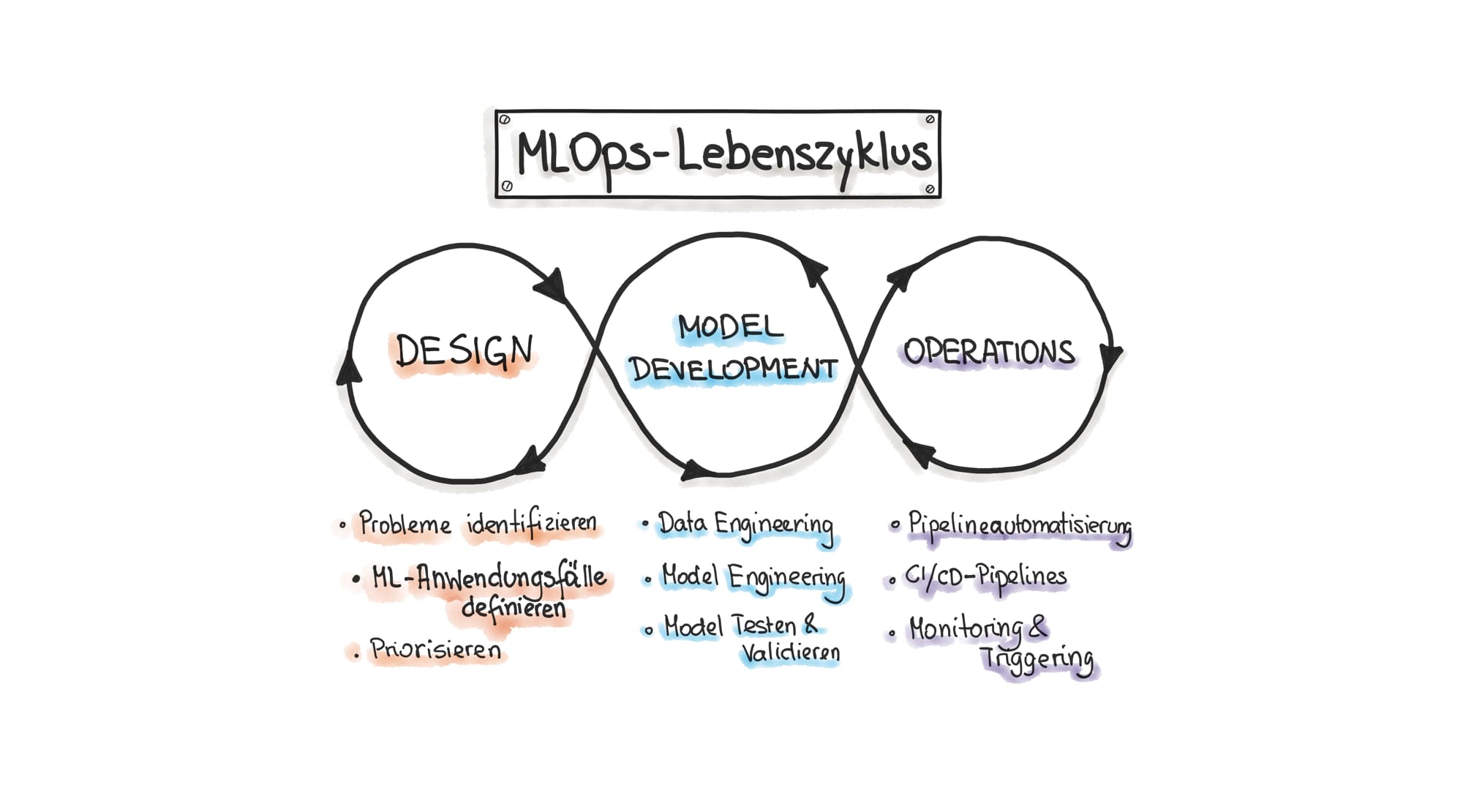
Grundsätzlich erfolgt die Implementierung von Machine Learning in Software Systemen in drei Phasen (siehe auch Abbildung 1):
Design (Problem Definition)
Selbst die beste ML Lösung wird scheitern, wenn sie nicht der Lösung von Benutzungs- oder Business-Problemen dient. Daher versuchen wir in dieser ersten Phase herauszufinden wer die User unserer Software sind. Welche Probleme haben sie? Welche von diesen Problemen sind am besten mit ML lösbar? Und vor allem, können wir eine nicht-deterministische Lösung durch ML hinnehmen? Nehmen wir als Beispiel eine Software zur Abrechnung von beruflichen Reisekosten. Diese Software könnte einige Metadatenfelder, wie beispielsweise die Kategorie eines Belegs automatisch erkennen und somit den Prozess der Reisekostenabrechnung erleichtern.
Diese Phase ist entscheidend für den Erfolg eines ML Projektes. Es kann aber auch dauern bis das richtige Problem gefunden wurde.
Model Development (Data Science Research)
Nachdem wir die Workflows in der Softwarenutzung analysiert haben und für ML geeignete Use-Cases (Tasks) identifiziert haben, können wir diese Use-Cases in ML Projekte umwandeln. Man startet dann die sogenannte “Data Science Research Phase”. In dieser zweiten Phase durchläuft man eine Reihe von Prozessen iterativ:
- Die Abbildung des User Problems auf die ML Algorithmen. Man analysiert und identifiziert welcher ML Algorithmus für die Lösung des Problems am besten geeignet ist. In unserem Beispiel haben wir uns für unsupervised ML entschieden, weil die Kategorieerkennung eine Klassifikationsaufgabe ist.
- Data Engineering, wobei man erst analysiert ob die notwendigen Daten vorhanden sind bzw. welchen Aufwand wir betreiben müssen um die Daten zu beschaffen und diese mit Labels (zum Trainieren von Algorithmen) zu versehen. Zusätzlich, kann Data Engineering weitere Schritte beinhalten wie Data Integration, Preparation, Cleaning und Validation.
- Model Engineering, wobei man unterschiedliche Klassifikationsalgorithmen auf den Daten trainiert und dadurch verschiedene ML Modelle produziert. Durch die Evaluation der Performance, wird entschieden welches ML Modell für unser Problem am besten geeignet ist
Operationalisierung von Machine Learning
Das Training der ML Modelle, kann viel Zeit in Anspruch nehmen und herausfordernd sein, aber die eigentliche Herausforderung ist die Integration eines ML Systems in die Produktionsumgebung, d.h. in das Softwareprodukt das mit Usern interagiert. Ein ML System besteht aus drei Hauptelementen wie Trainingsdaten, ML Modell und Code zum Modell Training. Wir nutzen die DevOps-Prinzipien für ML Systeme (MLOps) um die ML Entwicklung (Development) und den ML Betrieb (Operations) zu kombinieren. Als Erweiterung von DevOps, widmet sich MLOps der Automatisierung und Überwachung in allen Schritten der Integration von ML Systemen in Softwareprojekten.
Jupyter Notebooks - Der heilige Gral?
Wir überspringen die Design Phase und gehen davon aus, dass wir bereits die richtige Problemstellung gefunden haben. Nun beginnt die zweite Phase: Data Science Research. Normalerweise nutzen wir für die Experimentierphase Rapid Application Development (RAD) Tools. Der Hauptfokus von RAD Tools liegt auf dem Erstellen von ML-Prototypen und funktionalen Anforderungen. Sehr populär sind z.B. Jupyther Notebooks oder Cloud-basierte Umgebungen wie Colab von Google. Es gibt eine Reihe von Vorteilen und Nachteilen für die Nutzung von RAD Tools. Zu den Vorteilen zählen folgende Aspekte:
- RAD Tools werden vor allem für die Analyse und Visualisierung von Datensätzen, sowie für die explorative Programmierung und Modellierung verwendet.
- RAD Tools sind für die Ausführung von Experimenten und Skripts mit verschiedenen ML Modellen optimiert.
Zu den Nachteilen der RAD Tools zählen folgende Eigenschaften:
- Nicht-funktionale Requirements können nicht berücksichtigt werden, wie z.B. die Performance des Systems in Produktion.
- Die Softwarearchitektur des Systems kann nicht berücksichtigt werden.
- RAD Tools sind eher auf manuelle Ausführung von Code ausgerichtet.
Anfangs soll der Data Science Prozess manuelle Schritte, wie die Vorbereitung von Daten oder ML Model Prototyping, enthalten. Auf diese manuelle Weise, verstehen wir jeden Schritt der Data Science Research Phase besser. Allerdings ist dieser manuelle Prozess für die produktive Anwendung von ML in Software Systemen absolut ungeeignet.
Laut diversen Studien, werden ca 80% der entwickelten ML Modellen nie in einem Softwareprodukt eingebunden - sie bleiben für immer in Jupyter Notebooks. Es gibt ein grundlegender Unterschied zwischen dem Trainieren eines ML Modells und dem Experimentieren innerhalb einer RAD Umgebung und der Integration eines ML Modells in einem Produktionssystem, das ein Benutzungsproblem löst. Gleichzeitig, gibt es einen Grund warum sich die Entwicklung der ML Anwendungen grundlegend von traditioneller Software unterscheidet. Der Hauptbestandteil der ML Software ist das ML Modell, das aus zwei Komponenten gebildet wird: Daten und ML Algorithmen.

Das bedeutet, dass jedes mal wenn sich entweder die Daten, die ML Algorithmen, die Modell Pipelines oder eine Kombination dieser Komponenten ändert, müssen wir das Re-Training von dem ML Modell triggern. In anderen Worten, die gesamte Entwicklungspipeline umfasst drei Trigger: Daten, ML Modell (ML Algorithmus) und Code (Modell Pipelines) (siehe auch Abbildung 2).
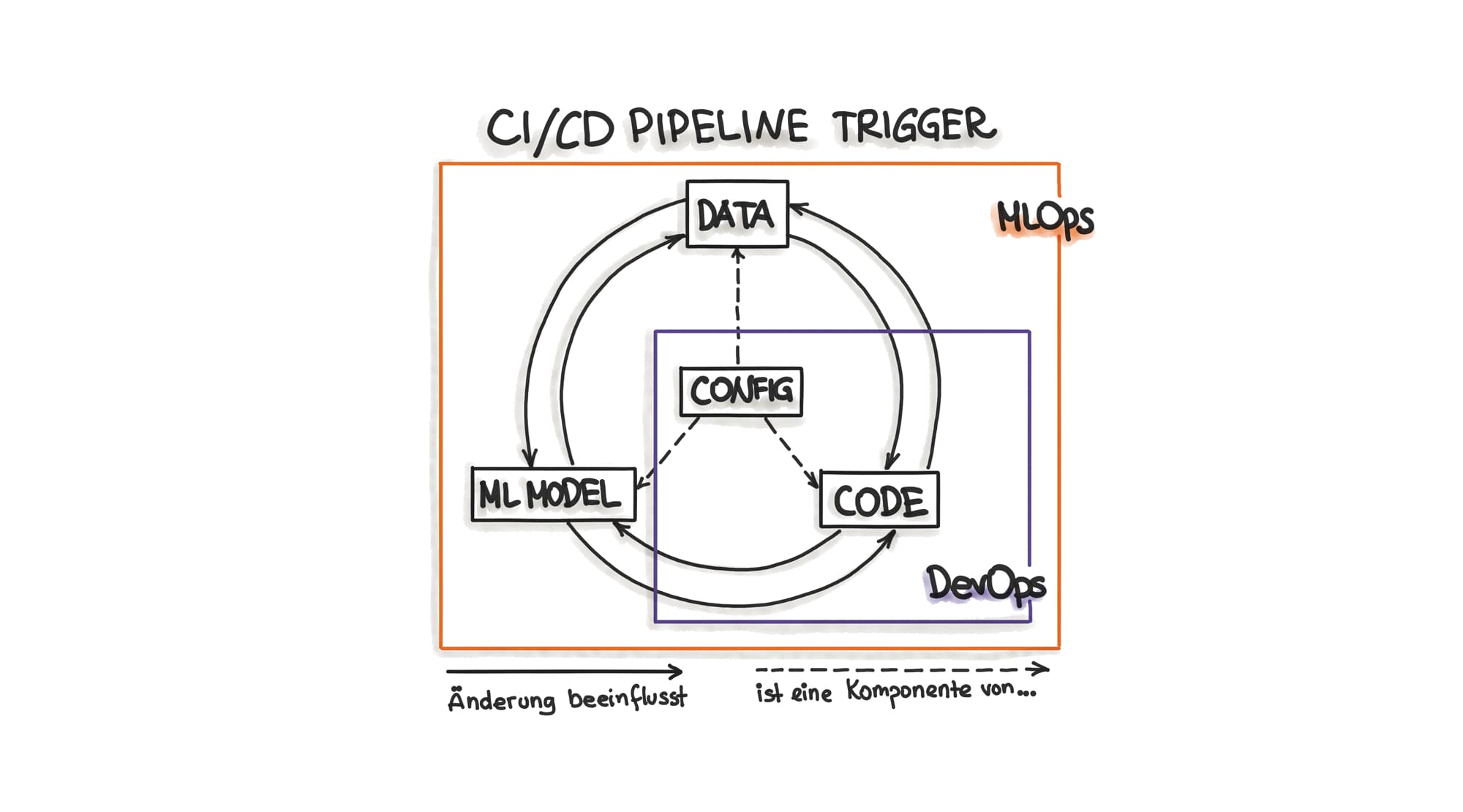
Darüber hinaus muss das ML Modell, sobald es in Produktion geht, regelmäßig neu trainiert werden. Der Grund dafür ist das sogenannte Model Decay Phänomen, bei dem das Modell schlechtere Ergebnisse liefert, wenn es noch nie gesehene Daten erhält. Daher werden ständig neue Daten gesammelt und mit Labels versehen und dadurch die ursprünglichen Trainingsdaten ergänzt. Auf diese Weise erzeugte neue Daten, triggern das Re-Training des ML Modells.
Ein gängiges Anti-Pattern ist das manuelle Trainieren durch Data Scientists, die das fertige Modell, ohne Integrationstests an Operations übergeben. Der manuelle Prozess ist fehleranfällig, da die ML Entwicklung ein iterativer Prozess ist und eine mehrstufige Pipeline umfasst. Bei manueller Ausführung können wir beispielsweise folgende Fehler begehen:
- Es wird die falsche Version von Daten genommen
- Wichtige Datentransformation wird auslassen
- Irgendein Schritt in der Pipeline wird vergessen
- Die Parameter und Hyperparameter für das Modeltraining können falsch gesetzt werden
- Eine falsche Labelling Methode wird verwendet
- Es werden keine Tests ausgeführt
Oft wissen wir nicht, welche Faktoren für die Modell Accuracy entscheidend sein können. Wenn wir versuchen die Leistung des Modells zu verbessern würden wir an verschiedenen Stellen experimentieren wie dem ML Algorithmus, den Features, den Trainingsdaten, oder mit einer Kombination aus allen. Auch wenn wir Experimente manuell mit verschiedenen Konfigurationen durchführen, verlangsamt die manuelle Arbeit den gesamten Prozess.
Machine Learning Pipelines Automatisieren
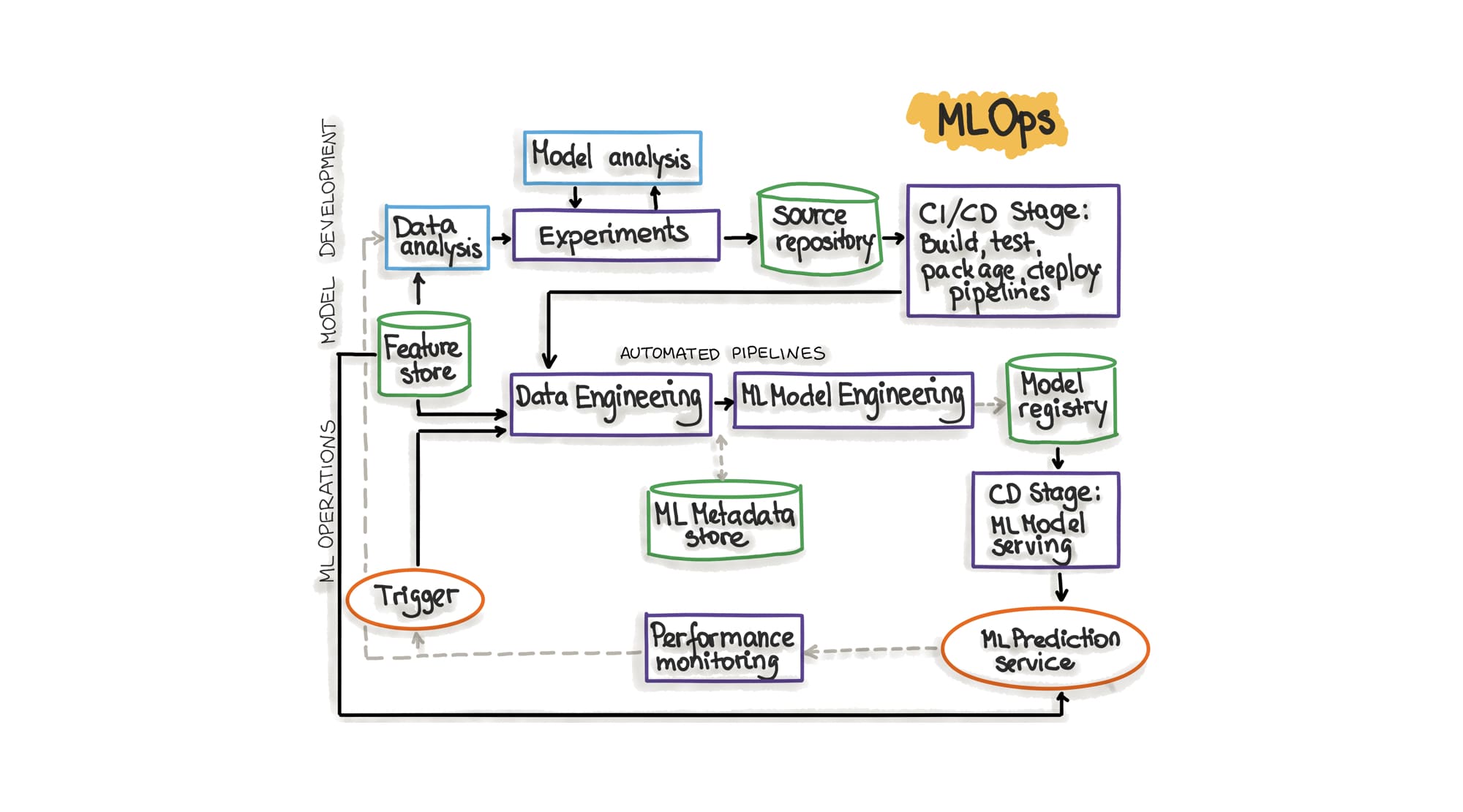
Eine ML Trainings-Pipeline ist Software und sollte demnach auch von den aktuellen technischen Praktiken rund um Continuous Integration und Continuous Delivery profitieren. Allerdings gibt es Arbeitsschritte auf dem Weg zu einem Prediction Service, die noch nicht automatisierbar sind. Dazu zählen die Datenanalyse, um geeignete Features für das Trainings auszuwählen, und die Modellanalyse, um einen geeigneten Machine Learning Algorithmus (Modell) zu identifizieren. Alle restlichen Schritte der Trainings-Pipeline sollten automatisiert durchgeführt werden, wobei es während der Experimentierphase bei der Entwicklung eines ML Modells durchaus vertretbar ist die Trainings-Pipeline lokal auszuführen, wenn die benötigten Rechenkapazitäten vorliegen.
Laut Uber, half die Automatisierung ihres ML Workflows bei der Erhöhung der Iterationsgeschwindigkeit. Bei Anpassungen der Abhängigkeiten, beim Finden von Fehlern und der parallelen Entwicklung von ML Komponenten stieg die Produktivität der Entwickler an.
Eine Erhöhung der Produktivität schlägt sich zwangsläufig in einer kürzeren Time-to-Market nieder, wobei der Aufbau der Infrastruktur anfänglich Zeit- und Ressourcenintensiv sein kann.
Unterschiede zu traditionellem CI/CD
Weshalb sollte man überhaupt einen Unterschied machen, wenn es um ML Software Deployments geht? Nun, der Prozess der ML Modell Entwicklung zeichnet sich vor allem durch seinen experimentellen Charakter aus. Es wird viele Versuche geben ML Trainingscode und die verwendeten Daten so lange zu optimieren, bis ein besseres Ergebnis erzielt wird. Diese Herangehensweise erfordert exzessives tracken von Versionen.
Das zeigt also, dass es eben nicht darum geht lediglich ein fertiges ML Model unter Code Versionsverwaltung zu stellen und mittels einer CI/CD Pipeline die Integration in einen Prediction Service durchzuführen. Ein ML Modell ist ein Artefakt und damit das Produkt einer ML Trainings-Pipeline. Aus diesem Grund muss die Trainings-Pipeline selbst versioniert und getestet werden.
Es liegt nahe die Trainings-Pipeline mit einer CI/CD Pipeline zu vergleichen, dessen Code ja heutzutage idealerweise deklarativ vorliegt. Auch das Produkt einer CI/CD Pipeline ist mitunter ein deploybares Artefakt, wie z.B. ein Container Image. Doch statten wir unsere CI/CD Pipelines, wie jede andere Software, normalerweise mit Unit Tests aus? ML Trainings-Pipelines müssen unbedingt Softwarequalität erreichen und daher getestet werden, wie es für traditionelle CI/CD Pipelines noch nicht selbstverständlich ist
Continuous Integration für ML
Die ML Trainings-Pipeline besteht aus verschiedenen, sequenziell ausgeführten Schritten: Datenvorbereitung, ML Modell Training, ML Modell Evaluierung. Die Pipeline sollte modular aufgebaut sein, um somit jeden Schritt separat testfähig zu machen. Die Schritte einer ML Trainings-Pipeline werden auch “Komponenten” genannt. Für jede Komponente sollten Unit Tests gepflegt werden um eine korrekte Funktionalität zu gewährleisten. Ebenso ist die Integrationsfähigkeit der Komponenten durch Tests zu gewährleisten. Die Komponenten der ML Pipeline könnten sogar als Microservices implementiert werden, wie beispielsweise Uber dies getan hat. Somit ergibt sich die Möglichkeit verschiedene ML Trainings-Pipelines nach den Bedürfnissen des betreffenden Modells zu orchestrieren. Die resultierenden separaten APIs erleichtern dadurch natürlich das Testen der Pipeline-Komponenten.
Continuous Delivery und Deployment für ML
In erster Linie wird in diesem Schritt die Trainings-Pipeline ausgeführt, was zur Auslieferung des ML Modell Artefakts in eine Model Registry führt. Auch das ML Modell wird dabei auf Performance und Integrationsfähigkeit mit dem Gesamtsystem getestet. Ist die Performance, also die Vorhersagequalität, des Modells zufriedenstellend wird die Bereitstellung für den Prediction Service durchgeführt. Der Prediction Service, der im Grunde das ML Modell mit einer im Web verfügbaren API ausstattet, muss dabei ebenfalls Integrations- und, Load-Tests ausführen um die Stabilität zu gewährleisten.
Continuous Training (CT)
Dieser Schritt in der ML Deployment Pipeline wird auch Continual Learning genannt und ist einzig den ML Systemen vorbehalten [1]. Man könnte die ML Deployment Pipeline also CI/CD/CT Pipeline nennen.
Wie bereits erwähnt, entsteht ein ML Modell aus dem ML Algorithmus und den Daten mit denen es trainiert wurde. Nun ist es so, dass ML Modelle mit der Zeit schlechter werden (Model Decay) und regelmäßig mit neuen Daten neu trainiert werden müssen. Um den Zeitpunkt zu finden, an dem ein ML Modell wieder neu trainiert werden sollte, wird das Performance Monitoring angewendet und damit die Qualität der Vorhersagen des Prediction Services bestimmt. Fällt z.B. die Accuracy Metrik unter ein bestimmbares Level, wird das Re-Training angestoßen. Neben diesem Ansatz, gibt es aber auch die Praxis, ein Modell in festgelegten regelmäßigen Abständen pauschal neu zu trainieren. Regelmäßiges Re-Training, kann die Zeit reduzieren bis ein Bug durch fehlerhafte Daten behoben wird.
Bei beiden Herangehensweisen muss für das neu trainieren des ML Modells die selbe Trainings-Pipeline genutzt werden mit der das Modell initial generiert wurde. Für das Re-Training werden üblicherweise alle neuen Daten seit des letzten Trainings zusätzlich zu den historischen Daten für das Re-Training verwendet. Nachdem dieser Prozess abgeschlossen wurde, wird der Prediction Service in das Produktivsystem deployt und das neue Modell wurde mit der ursprünglichen Version der Trainings-Pipeline erzeugt aber mit einer neuen Datenversion. Ebenfalls das Modell selbst hat sich durch das neue Training verändert und erhielt demnach eine neue Versionsnummer.
Wie kann also erreicht werden, dass das ML Modell im Falle eines Model Decays mit exakt der Trainings-Pipeline neu trainiert wird mit der es entstanden ist? Genau für diesen Zweck wird die ML Trainings-Pipeline versioniert und mit der ersten Ausführung für zukünftige Re-Trainings bereitgestellt.
Metadata Store
Daten, die Trainings-Pipeline-Ausführungen beschreiben, werden in einem sogenannten “Metadata Store” gespeichert. Die resultierende ML Modell-Qualität (Accuracy, Precision, Recall und F-1) wird dadurch nachvollziehbar, vergleichbar und reproduzierbar. Desweiteren wird das Finden und Beheben von Fehlern und Anomalien erleichtert und die Herkunft von Daten und Artefakten wird beschrieben. Außerdem sind die Parameter, Hyperparameter und der verwendete Algorithmus der Trainingsausführung entscheidend für das Endprodukt und müssen dokumentiert werden. Data Engineers können von diesem Metadata Store profitieren, da die Einflüsse neuer Daten oder die Nutzung neuer Technologien beim Trainieren besser nachvollziehbar werden.
Praktische Umsetzung
Grundsätzlich ist MLOPs, wie auch DevOps, Sprachen-, Framework- und Infrastrukturunabhängig. Allerdings existiert bereits eine weite Landschaft von diversen open-source Tools für die ML Entwicklung und den Betrieb. LF AI Foundation Interactive Landscape bietet eine Übersicht über diese Tools gruppiert nach den Verwendungsbereichen.
ML Software Architektur
Die Implementierung von ML Software lässt sich mit verschiedenen architektonischen Lösungen umsetzen. Die Grundlage für die Wahl des Architekturmusters hängt von zwei Aspekten ab: Erstens, wie das Modell trainiert wurde und zweitens, wie die Prediction stattfindet. Insgesamt sind vier Architekturmuster üblich: Forecast, Web Service, Online Learning und AutoML. Bei der Entscheidung welches Muster herangezogen wird müssen folgende Fragen beantwortet werden:
- Mit welchen Daten wird das ML Modell trainiert?
- Wann soll die Prediction stattfinden?
In unserem Fall der Reisekostenabrechnung, haben wir historischen Daten und nutzen diese für das Trainieren des ML Modells. Die Prediction findet jedes mal statt wenn Nutzer Dokumente hochladen, d.h. die Nutzer rufen die Prediction on-demand ab. Dementsprechend implementieren wir einen Web Service für das Serving des ML Modells.
Serving Patterns
Die nächste Frage die wir noch beantworten sollten ist: “Wie wird ein ML Modell in ein Softwaresystem integriert?”
Hier wird zwischen fünf Pattern unterschieden: Model-as-Service, Model-as-Dependency, Precompute, Model-on-Demand, und Hybrid-Serving.
- Model-as-Service Pattern - Das ML Modell wird als eine eigenständige Komponente als ein Web Service deployt.
- Model-as-Dependency Pattern - Das ML Modell wird als eine Bibliothek eingebunden.
- Precompute Pattern - Die Prediction Ergebnisse werden im voraus berechnet und in einer Datenbank abgespeichert.
- Model-on-Demand Pattern - Dieses ist vergleichbar mit dem Model-as-Service Pattern, nur mit asynchroner Kommunikation über eine Message Queue.
- Hybrid-Serving Pattern - Hier besteht das ML Modell aus zwei Komponenten: Basismodell und User-Modell. Das Basismodell wird auf dem Server und das User-Modell wird auf dem Endgerät trainiert. Dieses Pattern wird meistens im Mobile Bereich angewendet.
Eine ausführliche Beschreibung von allen Pattern findet man unter ml-ops.org. Durch die Entscheidung für das Web Service Architekturmuster für die Implementierung der ML Software, wird unser ML Modell unabhängig vom System sein. Daher nutzen wir das Model-as-Service Serving Pattern um Predictions für unsere Anfragen zu berechnen. Demzufolge erreichen wir die Funktionalität des ML Modells über eine REST API.
Eine wichtige Komponente für beides, Training und Serving, ist die Feature Extraction. Diese kann z.B. als Service oder eingebundene Bibliothek vorliegen, um Code Duplication für die Feature Transformation zu vermeiden.
Trainingsausführung
Manchmal wird die benötigte Rechenkapazität unterschätzt, die das Trainieren von ML Modellen erfordert. Eine skalierbare Lösung stellt hierbei die Nutzung von Cloud Computing Ressourcen da, die je nach Bedarf für die Zeit des Trainings leistungsstarke Rechenkapazität bieten (on-demand). Über eine CI/CD Pipeline kann das Training mit diesen on-demand Ressourcen dann angestoßen werden.
Trainings-Pipelines die aber nur wenig Rechenkapazitäten benötigen können auch mit einem beliebigen CI/CD System-Runner selbst ausgeführt werden. So wäre es möglich den gesamten Bereitstellungszyklus des ML Systems (CI/CD/CT) mit einem üblichen CI/CD System abzubilden. Wichtig ist vor allem auf die Bedürfnisse des ML Entwicklungsprozesses und das Skalierungspotenzial zu achten.
Versionierung und Dokumentation
Für die Versionierung von ML Assets und Artefakten kommt man an dem DVC (Data Version Control) System nicht vorbei. DVC dient der Entwicklung und Ausführung von Trainings-Pipelines. Außerdem, können Datensätze, Artefakte und Metriken mit einem git-Überbau getrackt und in einen Objektspeicher, wie z.B. S3 und Google Cloud Storage, abgelegt werden. Somit agiert DVC neben der Versionierung aller Komponenten ebenso als Model Registry, Data- und Metadata Store.
Besonders interessant ist es, wie DVC mit Metadaten umgeht, denn diese können beliebig festgelegt werden und liegen als Dokument vor. Beispielsweise, um das Filtern nach Metriken zu erleichtern sollten die Metadaten zumindest im JSON Format vorliegen. Da es aber in DVC kein einheitliches Metadata-Schema und keine eingebaute Validierung gibt, kann es sinnvoll sein eine Datenbank für die Dokumentation der Metadaten zu nutzen. Solch eine Datenbank ist z.B. ML Metadata (MLMD) welches eine Komponente von TensorFlow Extended (TFX) ist, aber unabhängig von TFX genutzt werden kann. Doch so frei die Aufzeichnung von Metadaten in DVC ist, so starr ist das TFX-Korsett von MLMD. Ein Metadata Store der goldenen Mitte ist ArangoML, welches Daten je nach Kontext als JSON-Dokument, in Graphen und als Schlüssel-Wert Paare speichert.
Die Praktiken der Besten
Laut “Accelerate”, einer der größten Studie über DevOps Praktiken, stellt die Befolgung von DevOps Prinzipien ein Hauptunterschied zwischen leistungsstarken und leistungsschwachen Unternehmen dar.
Um Wettbewerbsfähigkeit dauerhaft zu sichern, müssen Unternehmen schneller Software und Services ausliefern. Um das erreichen zu können, müssen sie die Software sicher, resilient und schnell bereitstellen. DevOps beinhaltet eine Reihe von Praktiken um genau hierbei zu helfen. Die Integration von ML Modellen erfordert eine Erweiterung von DevOps um genau zwei weitere Komponenten, nämlich Daten und ML Modelle.
Die “Accelerate”-Studie hat demnach bewiesen, dass die Performance der Softwarebereitstellung eine direkte Auswirkung auf die Unternehmensperformance hat und einen klaren Wettbewerbsvorteil sichert.
Häufige Releases lassen schnelleres Nutzerfeedback erwarten. Das entspricht dem Konzept “Winning by Shipping” indem das ML Produkt in die Hände der Nutzer gebracht wird um die ML Modelle bzw. Ideen zu validieren. Dadurch können ML Modelle mit neuen Daten arbeiten, was für den Erfolg der Einführung von Prediction Services ausschlaggebend ist. Durch die Automatisierung von Deployments, sind schnellere Modellverbesserungen und somit die Validierung des Gesamtsystems möglich.
Continuous Delivery ist ein technischer Prozess (siehe auch Abbildung 3), um Änderungen in Software sicher, schnell und nachhaltig in die Produktionsumgebung oder zu den Nutzern zu bringen. Zu den o.g. Änderungen in ML-Software gehören Komponenten wie Datensätze, ML Modelle, Features, Konfigurationen, Fehlerbehebungen und Experimente.
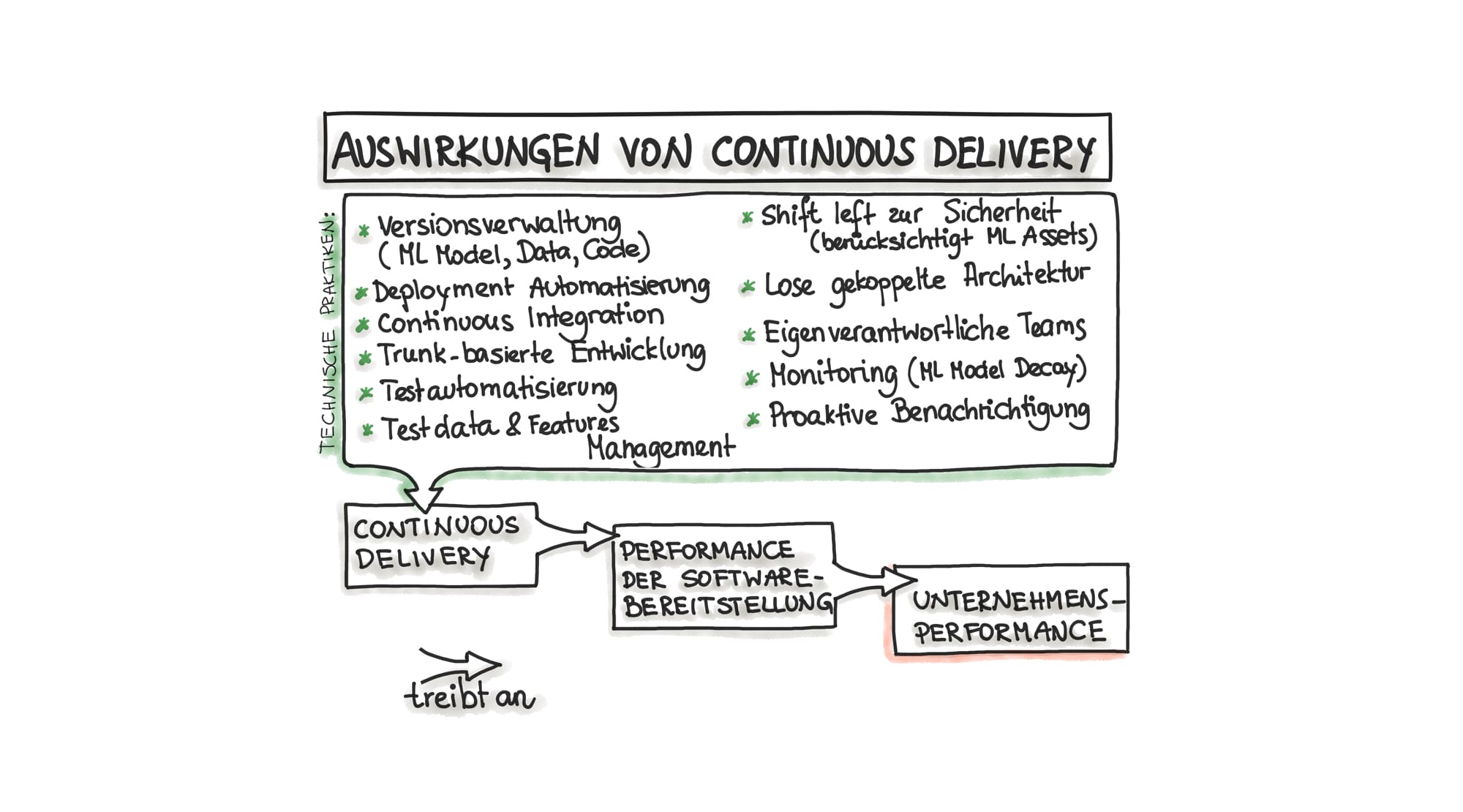
Traditionell, erzeugt Continuous Delivery viele Feedback-Schleifen damit die Nutzer qualitativ hochwertige Software bekommen und zwar in häufigeren und zuverlässigen Zyklen. Wenn die Implementierung steht, muss der Prozess der Softwareauslieferung eine leicht wiederholbare Routine sein. Das gleiche gilt für das Training von ML Modellen. Sobald ein ML Modell die Phase des Experimentierens verlassen hat, sollte der Prozess um ein neues ML Modell zu deployen eine routinierte Aktivität sein, die jederzeit automatisiert durchgeführt werden kann.
In anderen Worten, die Einführung von Continuous Delivery für ML Software erfordert zwar eine erhebliche Investition in Test- und Deployment-Automatisierung, verbessert aber die Performance der ML Softwarebereitstellung und dementsprechend die Unternehmensperformance.
Literatur
-
Diethe, Tom, Tom Borchert, Eno Thereska, Borja de Balle Pigem, and Neil Lawrence. 2019. “Continual learning in practice.” arXiv preprint arXiv:1903.05202 ↩