
While designing a system architecture we try to keep the production system in mind. That is the only thing that counts in the end. For this environment we determine how many physical and virtual machines we will deploy, how the software will be distributed on them, and how the network infrastructure, complete with load balancing and firewalls, will look.
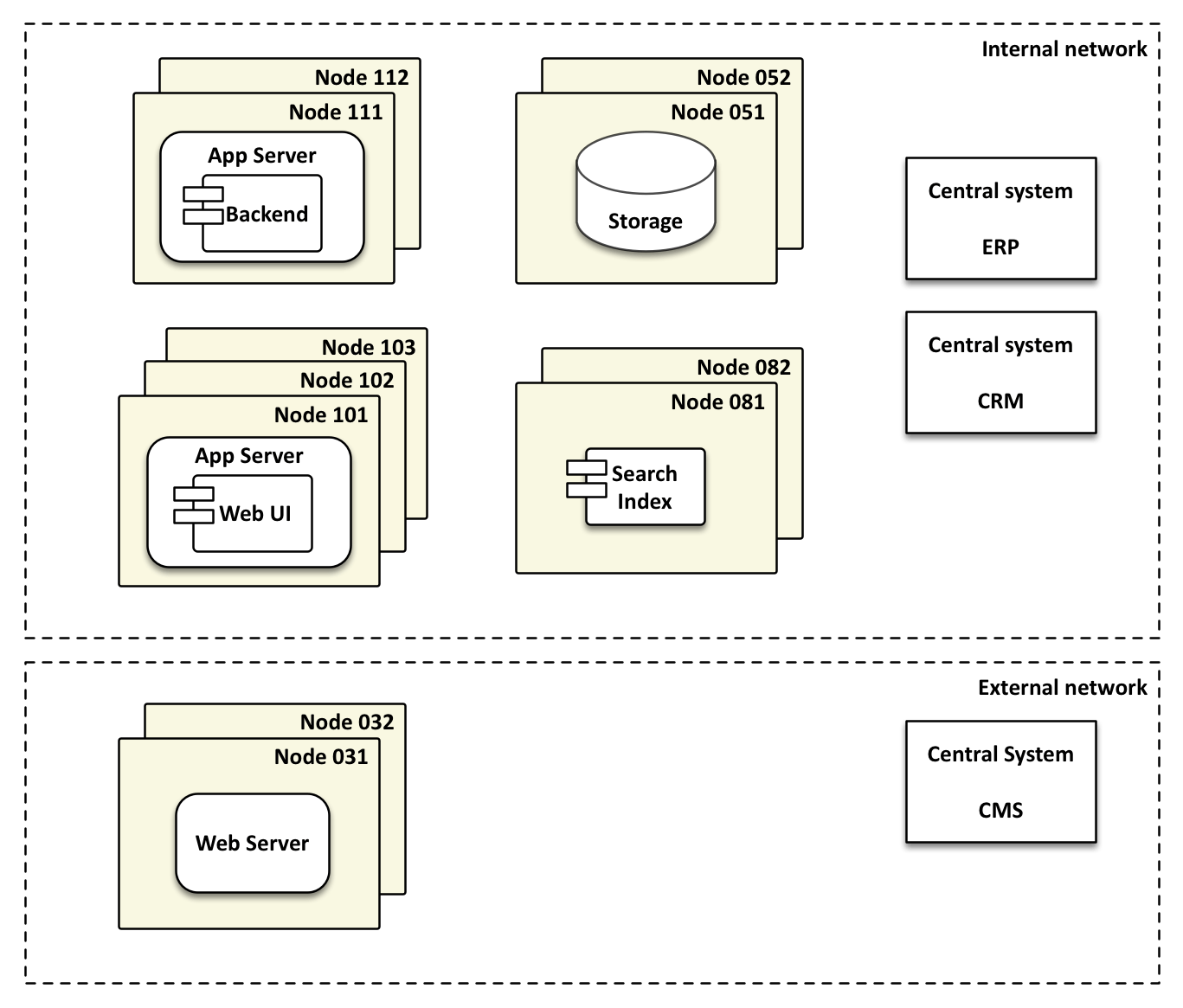
Before operations can install software in a production environment it must undergo a series of tests in different environments. Normally these include a wide range of test areas in which various aspects are probed: general runtime behaviour, business logic, integration in the system landscape, interfaces, performance, and behavior under load. Experience has shown that the number of test areas increases with the lifetime of the system.
Many challenges and questions often arise at this point. For example, how can new environments be efficiently and cost-effectively deployed while the existing environments are maintained and operated? And how do we ensure that the behavior of our software while testing reflects the actual performance in a production environment?
Clearly, it is costly if every machine and every application must be manually installed and configured, or if individual routing and firewall rules must be defined for each environment. An often practical, though indirect, approach is to forgo many details in the test environment which make life difficult in practice. So for tests there is no firewall, no pre-loaded web server, no certificate, and no encryption. Also sometimes only one instance will be deployed from each application server in order to save the extra work involved in clustering and replication.
When making these shortcuts it can unfortunately never be ensured that a successful system test in the testing environment will also guarantee a successful launch in production. Even a small discrepancy in the configuration of the application server or the omission of a single firewall rule can disrupt the rollout.
Automation of the rollout
An effective and promising solution to this problem is the automation of server configuration and software installation. This is sometimes described as “infrastructure as code.” This method of automating the rollout is principally performed via a set of scripts on the operating system level. For good reasons special tools have been developed for configuration and server automation for this task. Puppet [1] and Chef [2] are examples of such tools. Tools such as these enable the “programming of infrastructure” using a specialized syntax designed expressly for this purpose (see also the inset “Puppet, Chef, and Vagrant”).
The source code for such software – be it batch scripts, Chef recipes, or Puppet modules – should be maintained under version control in the same manner as the source code for the software. The infrastructure code is just as fundamental a part of each release as the software artifacts of the application itself. Looking at the version control system we should find the following infrastructure elements alongside the application source code:
- System users and groups
- System services (i.e. cron, syslog, sendmail)
- Network and load balancer
- Local firewall (iptables), certificates and keystores
- Logging and monitoring
- Web server (apache, nginx) and web caches (squid)
- Application server
- Database configuration and migration tools
A proven approach to using Puppet and Chef is the combination of the individual configuration elements into larger units. These units can be labeled with meaningful names. For example, we can combine a module called “AppServer” from an operating system user’s data, some installation packets, and a set of configurations files. The entire module can then be transferred together to a target node, which can be either a virtual or physical machine. As soon as our friendly testing colleagues have provided us with a newly deployed server we can have our system or a part of our distributed system installed within minutes. Provided a job exists in the central build server, the entire process runs literally “at the push of a button.” At this point I don’t want to underplay the investments needed for an extensive IT automation. Writing (and more importantly testing) programs that reliably install and configure a service is normally not trivial and can be many times more complicated than configuring the service manually. New technologies and methods must be developed and the responsibilities and interfaces between development and operations must be organized and defined.
Each company must decide for itself when the investment will pay off. It is not guaranteed that this will already be the case with the first project.
Too big to scale
In order to develop a software system flexible enough to distribute over different hardware environments there must first be something to distribute. Those responsible for the design of the system and software architecture should therefore avoid the development of large, monolithic blocks that can only be deployed and operated on the server as complete units. Such code can only be scaled in its entirety, even if only a single module in the entire application is under high load. If the system is split into multiple installable elements then each deployment can be individually administered to run a custom number of instances and share system resources intelligently. Of course, the system architecture gets more complicated with such small applications, but through the automation of the configuration and deployment this complexity can be kept under control.
The flexibility and therefore the scalability of the system is further influenced by the distribution architecture that is used. A classic example in the area of Java application servers is the operation of a cluster in which the components are distributed and data and status information are replicated. The strain put on the system by this replication limits the number of nodes in the cluster while simultaneously prohibiting operation of the server in a distant location.
We can instead design a shared nothing architecture [3] where no status information is shared with our application server and our nodes run completely independently of each other. In this case we can deploy as many additional instances as necessary to fulfill our needs. The only things the operators of the computing center have to deal with are the load balancer and the firewalls. In the Java world in particular many state sensitive web frameworks have difficulties. Stateless web frameworks, like Rails or Django for example, make it easier to deploy many instances of a web application.
Minimize deviations
By versioning infrastructure code and avoiding any manual steps in the system configuration a fundamental uncertainty in the computing system can be avoided: unknown differences between the test environment and production.
Automation ensures that clearly defined versions of operating systems, system services, Java runtime environments, and web and application servers are installed in all environments. Of course there must be certain differences between the various environments, even trivial differences such as IP addresses, hostnames, or SSL certificates. Also, differences in the number and dimensioning of the machines should be supported by the automation of the server configuration.
It is therefore important that all differences are known and actively managed. For every environment there must be a set of parameters for the infrastructure code. In a Java environment this includes the definition of options for the application server, which can define, for example, the following properties:
- Memory management
- Garbage collection
- Thread and connection pools
- Settings for logging and monitoring
- Exception handling and timeouts
Ideally this parameterization can also define individually for each system component environment the number of processes or threads that can be used. The challenge here is to identify the important options and to define sensible default values.
Flexibility through configurability
The direct advantages of server automation mentioned above already reduce much of the manual work, debugging, and worry before the rollout for developers and operations. On top of that this adds another advantage: flexibility in the structuring of our environments.
By programming the infrastructure we can very quickly change the assignment of components and services to destination nodes. In a production environment there will probably be enough machines to distribute the system such that each component is at least redundant on different physical machines. This is done for both load sharing and reliability.
Assuming that a specialized test environment will only have a few virtual servers available, several components must be bundled in one machine (see Figure 2).
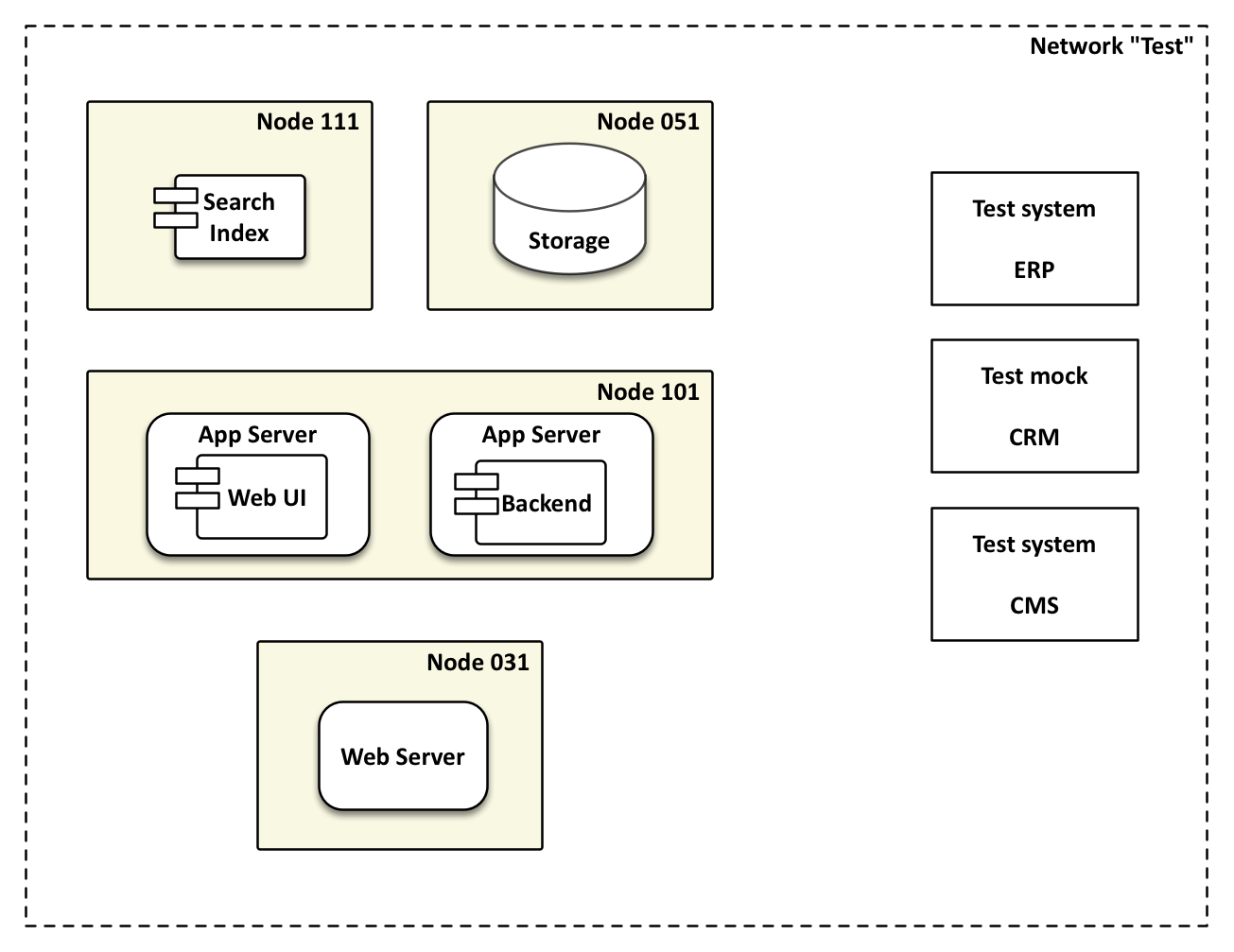
When operations notices that a single component is under especially high load, they can make an extra server available just for this component. With just a few lines of code in the configuration file they can then configure the settings of this server. As computing centers continue to adopt virtualization to be able to very quickly and flexibly provide new servers, the investment costs for automation of server configuration begin to pay off very quickly.
Improve configurability
In the automation of servers and software distribution we can observe an effect that many users of test driven development (TDD) have also experienced: completely independently of the cost-benefit ratio of the tests themselves, TDD usually leads to better structuring of the software. In order to test each class isolated from its context, the developers have to pay special attention to a clean separation of class responsibilities. With the introduction of infrastructure as code we can do something similar: in order to distribute the components of a system on differently dimensioned target machines we inevitably have to keep a flexible parameterization of the components in mind. Once we can define via a set of parameters for each target system how many instances of a component with which runtime configuration should be installed on which target node, we have the tools we need to flexibly scale our production system both horizontally and vertically as the need arises. This is done either by adding RAM and CPUs or by parallelizing over more machines. IT automation works best with a scalable architecture. On the other hand the automation works naturally to make the architecture more scalable.
Virtualization of local development environments
Now we have thought a lot about the automation and more effective use of the development and test environments. But what about the laptop mentioned in the title?
The integration of the system components should not be left to a build server in a central environment. It would be much better if the developers could already test on their laptops (or desktops) if a modified system component can still communicate with the others.
In principle, the developers can check out the automation scripts and run them locally in order to install and properly configure the services and infrastructure components. For simple scenarios this is a plausible method. But when a developer is involved in many projects he might not want to risk destroying his local environment with possibly incompatible system configurations. This is particularly laborious if the target system is running UNIX or Linux and the developer’s computer is running Windows and he has to run and configure cron, iptables, and syslog.
In this case it makes sense to configure a virtual machine for each project with the proper operating system and the set up the environment automatically.
The exact same system components and network configuration that are deployed in the central system environment with our configuration tools can also be installed on the development machine. Complex environment management systems, such as ERP and CRM, would either be run in a central development environment and called over the network or locally simulated with minimal mock applications.
If Chef or Puppet are used for the provisioning of the system this forces the use of a tool like Vagrant [4] on the development machine. Vagrant makes it possible to create virtual machines (VirtualBox or VMware) with the command line and configure them using Chef or Puppet. All developers of a project can set up a local development and test environment quickly and easily using the automated configuration of virtual machines. It is even more important that they are testing the software locally with the exact same infrastructure configuration that will later be used in the central environment.
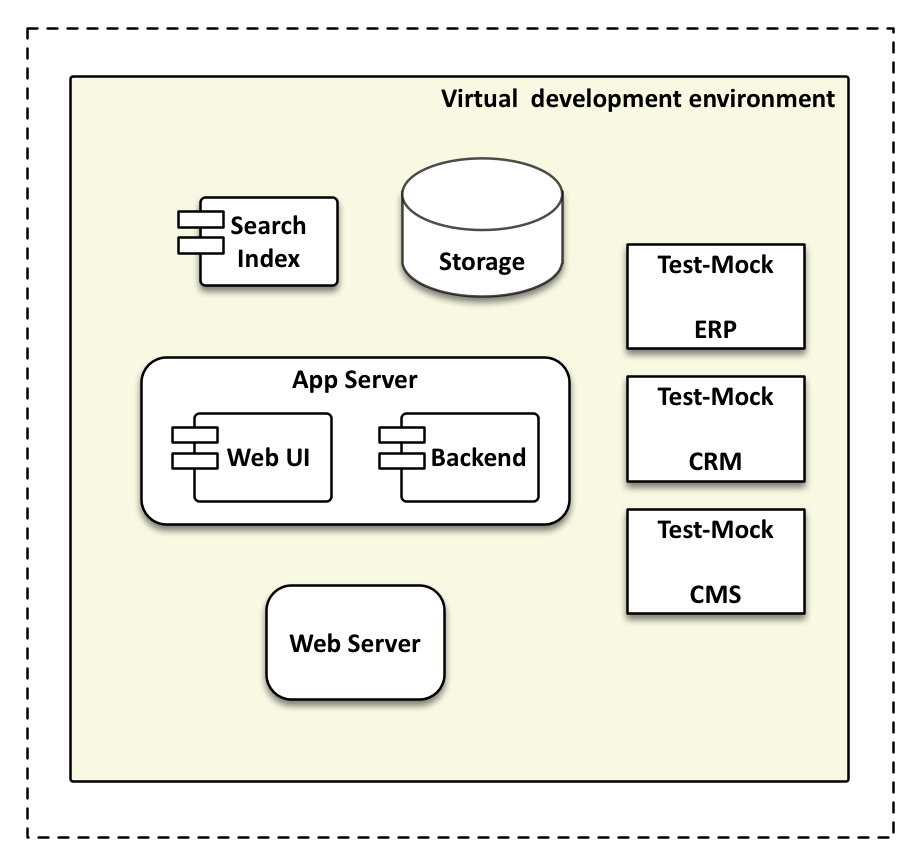
Finally integration can happen continuously. That is, developers can test if the system works with their changes before they commit those changes. The feedback loop once again gets shorter compared to before, when developers would only be notified on an issue via an email from the build server half an hour later.
Summary
In conclusion once more a summary of the most important aspects to consider in order to flexibly scale a distributed system, if possible down to a laptop, in production and testing environments:
- Instead of fewer large elements there should be many independent and separate components.
- Server configuration and installation should be programmed, not administered.
- The infrastructure code should be under version control and is a part of every release.
- The assignment of system components to target nodes and application servers should be flexibly configurable for every environment.
- The individual components must be parameterized for each environment. In Java EE systems, for example, memory management and thread pools.
- Fast configurations of servers and distribution of software is possible by deploying IT automation and virtualization.
- The increased complexity of the distribution architecture must be kept under control by reproducible and testable automation of the rollout.
Of course, it remains a challenge to operate a complex, distributed application system on a laptop. But with a skillful combination of virtualization, configuration management, and server and rollout automation it is possible to realistically operate and test system components and their communication locally.
Puppet, Chef and Vagrant
“A Puppet, a Chef and a Vagrant take a trip to the computing center…” These three might as well be the protagonists of a bar joke, but Puppet, Chef and Vagrant are three tools that can be used to “program” and test infrastructure. They help with the installation of distributed systems on environments of varied dimensions, for instance on a developer’s machine.
Puppet and Chef are open source Ruby-based configuration management tools that either operate with a client-server-model, or directly on a single machine. They are similar in functionality, but differ in approach, concepts and terms as well as syntax. Both tools provide a declarative way to express the desired configuration. As such, you define the expected outcome rather than the indiviudal steps. For example, you would declare that a user exists, that a package is installed, or a configuration file is available.
Puppet offers classes and modules, whereas with Chef, indiviual resources are encapsulated in so-called recipes, which are then bundled up in cookbooks. The most obvious difference between both tools is the language. Puppet uses a custom syntax, whereas Chef recipes are developed in an internal Ruby DSL (Domain Specific Language - a programming language for a very specific domain). Therefore, the whole Ruby language is available for Chef. This might be the reason why developers generally prefer Chef and system administrators tend to prefer Puppet.
Vagrant can be used to make and configure virtual development environments. Both VirtualBox and VMware are supported and others are in planning, e.g. KVM, but are still in the early stages of development. Puppet and Chef can be used for configuration management, amongst other tools. The usage of Vagrant helps to deploy project-specific development environments quickly and easily on development machines – independend of the host OS and close to the production system. Instead of installing an Apache Web Server and a JBoss Application Server locally on a Windows machine, for instance, you could configure a Vagrant Box with a suitable Linux distribution and provision the current state of the configuration from version control.
Links and Resources
Martin Fowler on Continious Integration, http://www.martinfowler.com/articles/continuousIntegration.html
Jez Humble, David Farley: “Continuous Delivery”, Addison-Wesley, 2010
References
-
Michael Stonebraker, “The Case for Shared Nothing Architecture”, 1986 ↩︎