
In this blog post I will demonstrate how this can be done quite easily by introducing an intermediate Prometheus instance within the Docker swarm and combining a couple of Prometheus features (mainly dns_sd_configs and cross service federation) to collect and fetch the required metrics data.
Within a Docker swarm cluster an application runs as a service. To the outer world (everything outside the swarm cluster) the service looks like one instance that can be accessed via a published port. Inside the swarm, there are usually multiple instances (a.k.a. replicas) of this service running. The overlaying Docker network routes requests to the published service port to one of the running replicas. As a caller you don’t notice that your request was routed to a service instance and especially not to which of them.
If you want to have a Prometheus server, running outside of the Docker swarm, to scrape the metrics of your service, the easiest way is to just let it call the metrics endpoint of the published service and everything is fine, right? Well, if your service runs in replicated mode with multiple instances, you won’t get the values you expect. A call to the service actually ends up in the Docker network load balancer, which forwards the scrape request to one (!) of the running instances. So, the data you get are the metrics of one of the service instances (and you don’t know which one). As Prometheus scrapes the service metrics periodically, and every scrape request is routed independently from the previous ones, chances are that the next scrape request is routed to and answered by a different service instance returning the metrics of this instance, and so on. So, worst case is that Prometheus gets a different set of metrics on every scrape request. The resulting data does not give you any coherent picture of your service.
If Prometheus would know about the multiple service instances and could scrape them individually, it would add an instance label to the metrics and by this store distinct time series for every metric and instance. Unfortunately, Docker swarm is quite good in hiding those details from Prometheus, at least to the outside of the swarm. Hence, if you run Prometheus itself as a service within the Docker swarm, you can use its dns_sd_configs feature together with the Docker swarm DNS service discovery to scrape all instances individually. In combination with Prometheus' cross service federation feature you can then scrape those service instance metrics from a Prometheus server outside of the swarm.
In this blog post I will setup a local Docker swarm cluster running a sample service to demonstrate how this looks like.
Setting up a Docker swarm with a sample service
First, I init swarm mode for my local Docker instance (can be deactivated again with docker swarm leave --force)
docker swarm initI’m running Docker Desktop for Mac, so I don’t need any additional options here. See the docker swarm tutorial for details on how to setup a local swarm in other environments.
One important detail (which unfortunately seems to be not described in the Docker swarm documentation) is, that the Docker swarm DNS service discovery does not work with the default ingress overlay network (it took me quite a while to figure this out until I found this answer in the Docker forum). So I will create a custom overlay network first.
docker network create \
--driver overlay \
--attachable \
custom-overlay-networkAs a sample service I use a Docker image containing a very basic Spring Boot application with the Actuator and Micrometer Prometheus plugins enabled.
docker service create \
--name sample-service \
--replicas 3 \
--network custom-overlay-network \
-p 8080:8080 \
sample-app:latestListing all the Docker services running in my swarm I can see my sample-service running with three instances.
docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
kgjaw3vx1tnh sample-service replicated 3/3 sample-app:latest *:8080->8080/tcpThe port 8080 of my Spring Boot application is published, so I can also access the actuator metrics endpoint
curl localhost:8080/actuator/prometheus
# HELP jvm_gc_live_data_size_bytes Size of old generation memory pool after a full GC
# TYPE jvm_gc_live_data_size_bytes gauge
jvm_gc_live_data_size_bytes 0.0
# HELP jvm_classes_loaded_classes The number of classes that are currently loaded in the Java virtual machine
# TYPE jvm_classes_loaded_classes gauge
jvm_classes_loaded_classes 7469.0
...As my Docker swarm only consists of a single manager node (my local machine), I can see the running Docker containers of all three replicas
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bc26b66080f7 sample-app:latest "java -Djava.securit…" 6 minutes ago Up 6 minutes sample-service.3.hp0xkndw8mx9yoph24rhh60pl
b4cb0a313b82 sample-app:latest "java -Djava.securit…" 6 minutes ago Up 6 minutes sample-service.2.iwbagkwjpx4m6exm4w7bsj5pd
7621dd38374a sample-app:latest "java -Djava.securit…" 6 minutes ago Up 6 minutes sample-service.1.1a208aiqnu5lttkg93j4dptbeTo see the DNS service discovery at work I connect to one of the containers running inside the Docker swarm. I have to install the dnsutils package to be able to use nslookup.
docker exec -ti bc26b66080f7 /bin/sh
apt-get update && apt-get install dnsutils -yLooking up the service name itself I get one single virtual IP address
nslookup sample-service
Server: 127.0.0.11
Address: 127.0.0.11#53
Non-authoritative answer:
Name: sample-service
Address: 10.0.1.2To resolve the virtual IP addresses of all service replicas running in my Docker swarm I have to lookup the tasks.<service name> domain name (see Docker overlay network documentation)
nslookup tasks.sample-service
Server: 127.0.0.11
Address: 127.0.0.11#53
Non-authoritative answer:
Name: tasks.sample-service
Address: 10.0.1.4
Name: tasks.sample-service
Address: 10.0.1.3
Name: tasks.sample-service
Address: 10.0.1.5This DNS service discovery feature is exactly what can be used by a Prometheus instance running within the Docker swarm to scrape all those service instances (I will refer to this instance as swarm-prometheus in the remaining text).
Scraping the service instances within the swarm
To setup the swarm-prometheus service I build a Docker image based on the latest official Prometheus image and add my own configuration file.
FROM prom/prometheus:latest
ADD prometheus.yml /etc/prometheus/The interesting part of the configuration file is the swarm-service scrape job I added. I use a dns_sd_config (see documentation for details) to lookup the scrape targets by executing a DNS query. I need to execute a type A DNS query and as the query only returns the IP addresses of the service instance I have to tell Prometheus the port the instances are listening on along with the path to the metrics endpoint.
scrape_configs:
...
- job_name: 'swarm-service'
dns_sd_configs:
- names:
- 'tasks.sample-service'
type: 'A'
port: 8080
metrics_path: '/actuator/prometheus'After building the image I create the swarm-prometheus service
docker build -t swarm-prometheus .
docker service create \
--replicas 1 \
--name swarm-prometheus \
--network custom-overlay-network \
-p 9090:9090 \
swarm-prometheus:latestWhen I open the Prometheus web UI and navigate to “Status -> Targets” I can see that my configuration works as expected
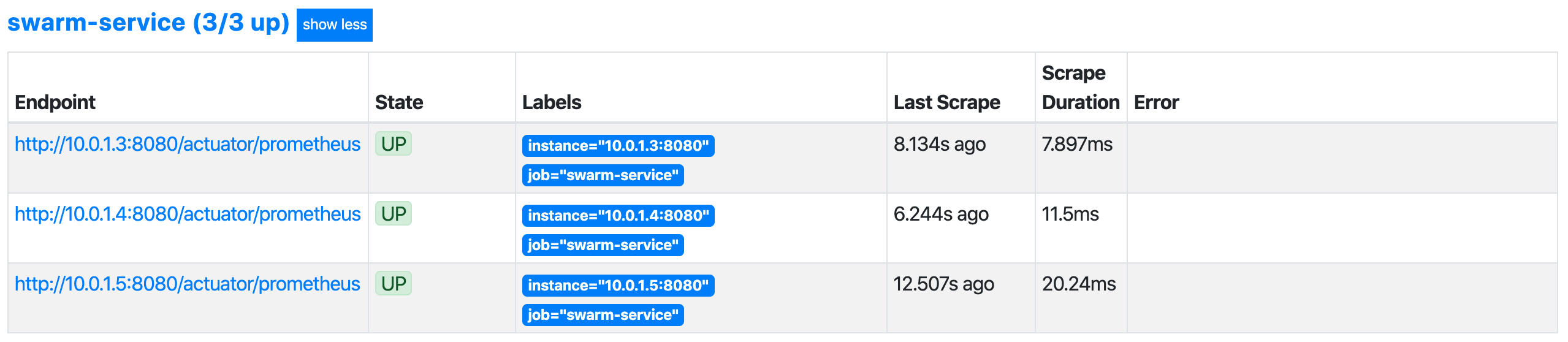
Executing a basic query for one of the metrics written by the sample application I get three resulting time series, one for each of my instances. The instance label, that was added by the prometheus scrape job, contains the IP and port of the according service instance.
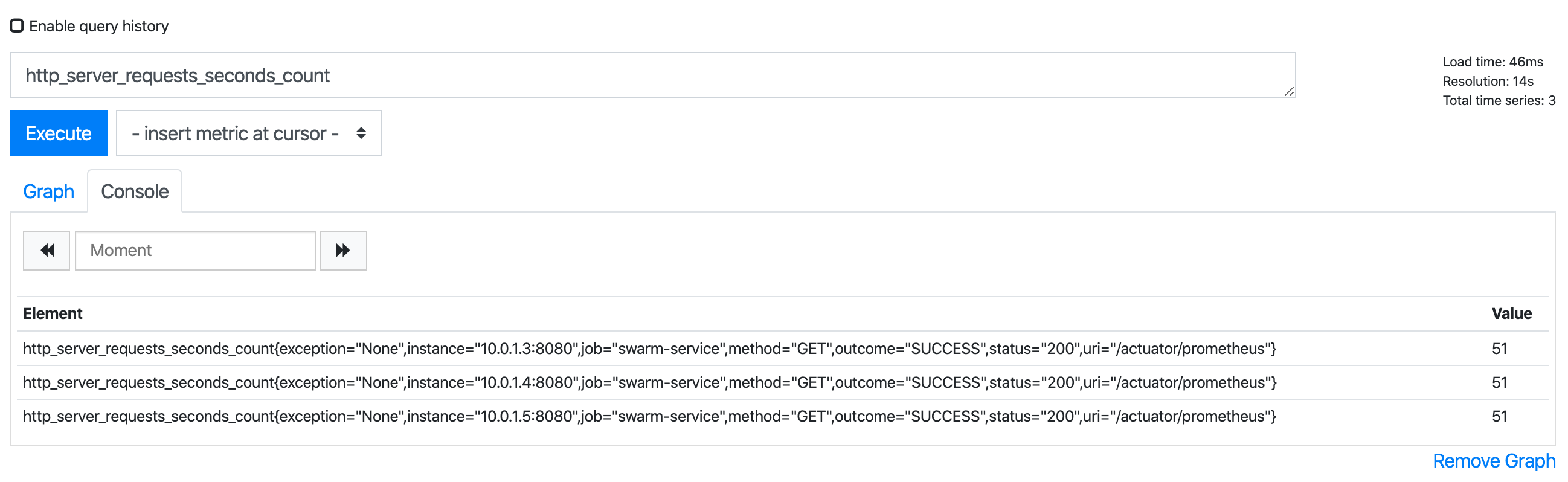
At this point, I have the metrics of all of my service instances gathered in the swarm-prometheus. As a next step I want to get them into a Prometheus server running outside of the swarm (which I will refer to as host-prometheus from here on).
Using federate to scrape the metrics from another Prometheus
Prometheus provides a /federate endpoint that can be used to scrape selected sets of time series from another Prometheus instance (see documentation for details). The endpoint expects one or more instant vector selectors to specify the requested time series.
I want to call the /federate endpoint of the swarm-prometheus and query for all time series that are collected by my swarm-service scrape job (I use curl with -G and --data-urlencode options to be able to use the unencoded parameter values)
curl -G "http://localhost:9090/federate" --data-urlencode 'match[]={job="swarm-service"}'
# TYPE jvm_buffer_count_buffers untyped
jvm_buffer_count_buffers{id="direct",instance="10.0.1.3:8080",job="swarm-service"} 10 1586866971856
jvm_buffer_count_buffers{id="direct",instance="10.0.1.4:8080",job="swarm-service"} 10 1586866975100
jvm_buffer_count_buffers{id="direct",instance="10.0.1.5:8080",job="swarm-service"} 10 1586866976176
jvm_buffer_count_buffers{id="mapped",instance="10.0.1.3:8080",job="swarm-service"} 0 1586866971856
jvm_buffer_count_buffers{id="mapped",instance="10.0.1.5:8080",job="swarm-service"} 0 1586866976176
jvm_buffer_count_buffers{id="mapped",instance="10.0.1.4:8080",job="swarm-service"} 0 1586866975100
...The only thing I have to do to get all this metrics into my host-prometheus is to add an appropriate scrape job that requests that /federate endpoint.
scrape_configs:
...
- job_name: 'swarm-prometheus'
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="swarm-service"}'
static_configs:
- targets:
- 'swarm-prometheus:9090'As I will run the host-prometheus in Docker, connected to the same network as my swarm, I can just use the swarm-prometheus service name as a host name. In a real-world environment I would probably have to find another way to access the swarm-prometheus service, e.g. using the IP address of one of the docker swarm nodes together with the published port.
The activated honor_labels flag ensures that Prometheus keeps the job and instance labels that are already included in the scraped metrics and does not overwrite them with its own values (see scrape_config documentation for details).
After building and running the host-prometheus I can check the targets status page again to see if the scrape job runs successfully
docker build -t host-prometheus .
docker run -d \
--network custom-overlay-network \
-p 9999:9090 \
host-prometheus:latest
Now I can executed the same Prometheus query as before in my host-prometheus web UI and I get the three resulting time series.
So, that was already it. Just by setting up an intermediate Prometheus instance within the docker swarm and combining a couple of existing features, it’s quite easy to get the metrics of all swarm service instances into a Prometheus server, even if it has to run outside the swarm.
Some fine tuning
After implementing the above setup in my current project I came up with some improvements that I think are worth sharing, too.
If you run several different Spring Boot services in your docker swarm, all listening on the default port 8080, setting up a dedicated swarm-prometheus scrape job for each service is quite redundant. The only thing that would have to be changed for each service is the requested domain name (tasks.<service name>). And, as you might have noticed, it’s possible to provide a list with multiple domain names in the dns_sd_configs. So we can configure one scrape job that covers all existing services
scrape_configs:
...
- job_name: 'swarm-services'
metrics_path: '/actuator/prometheus'
dns_sd_configs:
- names:
- 'tasks.sample-service-1'
- 'tasks.sample-service-2'
- ...
type: 'A'
port: 8080But, doing this we might run into another problem. With the old configuration, with one scrape job per service, we were able to name the scrape jobs accordingly and use the job label to identify/filter the metrics of the different services. Now, with one generic scrape job, we have to find another solution for that.
Fortunately, Micrometer, the library that we use in our Spring Boot application to provide the Prometheus metrics endpoint, can easily be configured to add custom labels to all written metrics. By adding the following line to the configuration file (e.g. application.properties) of each of our Spring Boot services a label named service with a static value containing the service name (here sample-service-1) is added to all metrics written by our service.
management.metrics.tags.service=sample-service-1Finally, if you use Grafana on top of Prometheus, the values of the instance label, containing the IP address and port of the service instances (e.g. 10.0.1.3:8080), will turn out to be problematic. If you want to use them as dashboard variables (e.g. to repeat panels for all instances or filter data for one concrete instance) this will not work because of the dots and colons in the values (those values will break the data requests to the underlying Prometheus because they are not URL encoded by Grafana). We have to convert them into a less problematic format to use them in this way. We can do this by adding a metric_relabel_configs to the swarm-prometheus scrape job config
scrape_configs:
...
- job_name: 'swarm-services'
metrics_path: '/actuator/prometheus'
dns_sd_configs:
- names:
- 'tasks.sample-service-1'
- 'tasks.sample-service-2'
- ...
type: 'A'
port: 8080
metric_relabel_configs:
- source_labels: [ instance ]
regex: '^([0-9]+)\.([0-9]+)\.([0-9]+)\.([0-9]+)\:([0-9]+)$'
replacement: '${1}_${2}_${3}_${4}'
target_label: instanceThis configuration takes all values of the source_labels (here instance), applies the given regex to each value, replaces the value with the given replacement expression (using the group variables ${1}, ${2}, … defined by the regex), and writes the replaced value as the target_label (here also instance, so overwriting the original value) into the metrics. So, the old value 10.0.1.3:8080 will be converted into 10_0_1_3 which is less problematic for Grafana.
Update: Since Prometheus 2.20 there’s also a Docker Swarm service discovery available that might be used instead of the DNS service discovery described in this post. Thanks to Julien Pivotto for updating me about the new feature.
Header Photo by Jordan Harrison on Unsplash