
Some time ago I was working on a quite complex microservice architecture. The separate services belonged to several DDD subdomains and bounded contexts. The communication between those services was based on a rather large number of domain events.
I recognized that all of this was way too complex to remember in necessary detail, when I had to look up the same things over and over again:
- which services belong to a bounded context
- which domain events exist overall
- which service emits a certain domain event
- which service(s) consume(s) that domain event
I was looking for some simple, lightweight tool to document all of this and some more aspects of our system, allowing me to easily find the answers to my questions.
I had a look at UML which I used in some previous projects. I liked the idea of defining a central model and having the possibility to use different views on it to highlight specific aspects for specific questions. On the other hand, UML comes with a very complex and generic meta-model. When I used it in the past I usually ended up with models where almost everything was a component, maybe categorized by some stereotypes. In addition, the tools to create and maintain an UML model are usually not very simple and lightweight (obviously because of the complexity of UML itself).
Another thing I investigated was the C4 model and the structurizr for Java library. In these I liked the model-as-code approach. Having the model maintained and regularily build along with the services itself will probably help to keep it up to date and consistent. But, the C4 model provides a very small and fix set of very technical model elements: contexts, containers, components and code. The things I wanted to model (subdomains, bounded contexts, domain events) are not really covered by this meta-model.
I already knew PlantUML and liked the very lightweight approach to draw simple UML diagrams. But that’s exactly what PlantUML is, a DSL to code diagrams. There’s no real model that can be evaluated.
After investigating all those options I had to conclude:
There's nothing that fits my requirements or expectations. It looks like I have to build it myself. It will be fun!
That way the code-your-model project was born.
Idea
Starting off I didn’t have a very detailed understanding of where I wanted to go. I knew that I wanted to build some kind of DSL that allows me to code my project-specific model in a formalized and validated way. Then, I wanted to read that model definition and use it to generate some small diagrams (using PlantUML) or some markdown snippets to be included in an overall documentation (e.g. DocToolchain).
I’ve had never implemented a DSL before and therefore wanted to keep my very first approach as simple as possible. I already knew the groovy programming language, which claims to be a good choice for writing DSLs. I especially like the geb browser automation framework, which comes with quite a nice groovy DSL. So I decided to use it and started reading everything I found about building an internal DSL in groovy.
After a couple of trials and errors I finally achieved a better understanding of what I wanted to implement:
- a project-specific meta-model, defining which types of elements (e.g subdomains, bounded contexts, domain events) I want to model and how they can be related to each other
- a DSL based on that meta-model that allows me to code my concrete model in a simple and concise way
- some reader or repository which reads that concrete model and allows to query it
Digging deeper and deeper into the subject I also noticed that it should have to be possible to define the model in a modularized way. In my project context I wanted to have all service-specific aspects (e.g. service belongs to bounded context ‘a’, service emits domain event ‘b’, service consumes domain event ‘c’) documented along with the service itself (in the same source code repository). In the end I want to collect all those model definitions and aggregate them into one overall model that can be navigated and queried.
After a while, I figured out that being able to generate some diagrams and markdown snippets is a nice feature, but the main benefit is having the aggregated model of a modularized system. While you’re usually not interested in all details at once, having all the information available and being able to navigate the relationships and query for different aspects is quite powerful. To enhance this capability I decided to use a neo4j graph database to store the model, because it allows to individually query it and comes with a browser console which displays the selected elements in a very nice graphical representation.
Today, a good 15 months after the initial idea, I’m happy to publish the current state of the project to GitHub and maven central and write this blog post to introduce it to you. So, let’s have a look at an example that describes how code-your-model works.
The complete example project containing all the code snippets that follow can be found on github as well.
Set up a code-your-model project
To use code-your-model I setup a groovy project which will contain the project-specific meta-model and the scripts to read and use the overall model. I use maven to do this, but it should also work with other build tools like gradle. I create a new maven project using the following POM.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.innoq</groupId>
<artifactId>code-your-model-example-project</artifactId>
<version>0.1-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.gmavenplus</groupId>
<artifactId>gmavenplus-plugin</artifactId>
<version>1.8.1</version>
<executions>
<execution>
<goals>
<goal>addSources</goal>
<goal>compile</goal>
<goal>addTestSources</goal>
<goal>compileTests</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.innoq</groupId>
<artifactId>code-your-model</artifactId>
<version>0.1</version>
</dependency>
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>
</project>The gmavenplus-plugin is used to have maven read and compile the groovy meta-model files. Besides the dependency to code-your-model itself I need to define the optional dependency to the neo4j-java-driver to be able to store the model in a neo4j database.
With this project setup done, I’m ready to start creating my project-specific meta-model.
Define a project-specific meta-model
For all types of elements I want to use in my model I have to create a groovy class that extends the base Element class from the code-your-model project.
I stick to the example described above and create the appropriate element types, starting with the Domain Event (For better readability I will write all domain-specific terms in italic and code fragments in fixed width font):
class DomainEvent extends Element {
}As you can see, the DomainEvent is defined as an empty class extending Element. That’s the simplest form an element type can have. Each Element contains a name attribute by default. If you just need some named elements of a specific type in your model, that would already do it.
The Subdomain element type is slightly more complex:
class Subdomain extends Element {
Type type
enum Type {
Core, Supporting, Generic
}
}I want to model the type of the Subdomain as well (according to DDD a subdomain can be core, supporting and generic, indicating how important the subdomain is within the overall domain, see Domain-driven Design Distilled by Vaughn Vernon for more details on that topic), so I add a field named type. I could have used a plain String field (also other primitive types like int or boolean will work), but I wanted to specify the possible values, so I used an enum type in this case.
The next element type I create is the BoundedContext:
class BoundedContext extends Element {
static relationshipDefinitions = {
belongsTo(Subdomain)
}
}The BoundedContext has no further attributes (besides the inherited name), but a relationship to the Subdomain. Possible relationships of an Element are specified within a static relationshipDefinitions closure. The name of the relationship (here belongsTo) can be choosen individually.
The last element type I need is the Service:
class Service extends Element {
static relationshipDefinitions = {
belongsTo(BoundedContext) { attributes(description: String) }
consumes(DomainEvent) {
reverse("consumedBy")
attributes(description: String)
}
emits(DomainEvent) {
reverse("emittedBy")
attributes(description: String)
}
}
}The Service has a couple of possible relationships. First, it belongs to a BoundedContext. In this case, I want to be able to add a description of type String to the relationship, so I define it as an attribute of this relationship. As there is no groovy class that represents the concrete relationship, the syntax for adding attributes unfortunately differs from the one for elements. Maybe I will be able to improve this in a future version.
The other two relationship definitions specify that a Service can consume and emit Domain Events. The reverse(<String>) statement defines the name of a reverse relationship, that is automatically added between two related elements. So, whenever I define that Service A consumes Domain Event B, the reverse relationship Domain Event B is consumed by Service A will automatically be added to the model.
Having all necessary element types created I can progress to the next step.
Define a concrete model
The model is defined in one or more groovy scripts. Normally, the scripts - especially the service-specific ones - would be located in the different service projects. To keep things simple I store them all together in my model project.
I start with the subdomains.groovy script:
import static com.innoq.codeyourmodel.example.model.meta.Subdomain.Type.*
Subdomain("Payment") {
type = Core
}
Subdomain("Risk Management") {
type = Core
}
Subdomain("Fulfillment") {
type = Supporting
}The statement Subdomain("Payment") creates a new element of type Subdomain named ‘Payment’. The closure that follows this statement specifies more details of that element. In the current example, the type of the Subdomain. I define two other Subdomains named ‘Risk Management’ and ‘Fulfillment’.
I decided to specify the Bounded Contexts in a separate bounded-contexts.groovy script:
BoundedContext("Invoicing") {
belongsTo Subdomain("Payment")
}
BoundedContext("Payment") {
belongsTo Subdomain("Payment")
}
BoundedContext("Risk Assessment") {
belongsTo Subdomain("Risk Management")
}
BoundedContext("Fulfillment") {
belongsTo Subdomain("Fulfillment")
}The creation of new elements of type BoundedContext is done the same way as for the Subdomain elements, before. In the details closure, I refer to the relationship definitions I defined in the meta-model. The belongsTo Subdomain("Payment") statement creates a relationship named ‘belongsTo’ from the given BoundedContext (e.g. ‘Invoicing’) to the Subdomain named ‘Payment’, that was described in the previous script.
In this case Subdomain("Payment") is mainly used as a reference to the element that was already specified. Although, even if that element would not have been specified before, it’s still allowed to reference it. Whenever a model element is referenced for the first time, it is created and added to the model. If there is a definition with some details of the same element in an upcoming model script, it will update the existing element.
At this point, with those two model definition scripts in place, the resulting model would contain the three Subdomains and the four Bounded Contexts as well as the relationships of those Bounded Contexts to the appropriate Subdomains.
Let’s add some Services to make it more complex. As I wrote before, the service-specific scripts would normally be added to the appropriate service source code, so I create a separate script for each Service, starting with service-order-audit.groovy:
Service("Order Audit") {
belongsTo BoundedContext("Risk Assessment"), {
description = """verifies all incoming orders, tries to approve them
automatically, provides the order details for manual
approval/rejection"""
}
consumes DomainEvent("Order created")
emits DomainEvent("Order rejected")
emits DomainEvent("Order accepted")
}We already saw most of the statements in this script in the examples before. A new Service named ‘order audit’ is created which belongs to the Bounded Context ‘Risk Assessment’, consumes a Domain Event named ‘order created’, and emits two Domain Events named ‘order rejected’ and ‘order accepted’.
The only new thing is the closure that is added after the belongsTo BoundedContext("Risk Assessment") statement (notice the comma between the statement and the closure, which is necessary to indicate that the closure is the second parameter of the belongsTo relationship definition and not of the BoundedContext("...") statement). It defines the details of the relationship, in the current example the value of the description attribute I have defined for that relationship in the meta-model.
Notice that I did not define the Domain Events I refer to in any previous script, nor will I do this in any later step. They don’t have any other details, so it’s fine to just reference them here.
Let’s have some more Services with similar definitions to complete the example model.
service-logistics-status.groovy:
Service("Logistics Status") {
belongsTo BoundedContext("Fulfillment"), {
description = """receives, processes and provides status updates
from the logistics like cancellations, shipments,
and returns"""
}
consumes DomainEvent("Order created")
consumes DomainEvent("Order accepted")
consumes DomainEvent("Order rejected")
emits DomainEvent("Order cancelled")
emits DomainEvent("Positions shipped")
emits DomainEvent("Positions returned")
}service-invoicing.groovy:
Service("Invoicing") {
belongsTo BoundedContext("Invoicing"), {
description = """calculates the debit/credit amounts for shipments
and returns, creates invoices for the customer"""
}
consumes DomainEvent("Positions shipped")
consumes DomainEvent("Positions returned")
emits DomainEvent("Debit calculated")
emits DomainEvent("Credit calculated")
emits DomainEvent("Invoice created")
}service-payment.groovy:
Service("Payment") {
belongsTo BoundedContext("Payment"), {
description = """handles the payment transactions
(authorization/capture/refund)"""
}
consumes DomainEvent("Order accepted")
consumes DomainEvent("Order cancelled")
consumes DomainEvent("Debit calculated")
consumes DomainEvent("Credit calculated")
emits DomainEvent("Order authorized")
emits DomainEvent("Debit captured")
emits DomainEvent("Credit refunded")
}That’s it, the example model is ready to be loaded and used.
Load and use the model
I want to load the model into a neo4j graph database, so I need a running database instance. The easiest way to start one on my local machine is to use the official docker image. I run it within the model project folder using the following statement (in the example project on github there’s a run-local-neo4j.sh script that runs this docker image in a slightly more professional way):
docker run -p7474:7474 -p7687:7687 -d --env NEO4J_AUTH=neo4j/test neo4j:3.5.14Next, I use the following import-model.groovy script to import all the model files into the running database:
@Grab("com.innoq:code-your-model:0.1")
@Grab("org.neo4j.driver:neo4j-java-driver:1.7.5")
import com.innoq.codeyourmodel.core.ModelReader
import com.innoq.codeyourmodel.example.model.meta.*
import com.innoq.codeyourmodel.neo4j.Neo4JModelRepository
def modelFiles = new File("./src/model/groovy").listFiles()
new Neo4JModelRepository("bolt://localhost:7687", "neo4j", "test").withCloseable {
it.clear()
new ModelReader(it)
.registerElementType(Subdomain)
.registerElementType(BoundedContext)
.registerElementType(Service)
.registerElementType(DomainEvent)
.read(modelFiles)
}I use the Neo4JModelRepository to connect to the neo4j database running in the docker container (there’s also a InMemoryModelRepository that can be used).
Before I actually import the model files I call the clear() method of the ModelRepository to remove any existing data. This way I can just reload and update the model whenever something has changed.
The ModelReader is used to read and parse all model files and add all elements and relationships to the given ModelRepository. Before I call the read(...) method I have to register all element types that are used in the model (again something that might be improved in a future release).
To execute the groovy script, the meta-model classes I defined before have to be in the classpath. In the root folder of the model project I execute the following shell command to run the script:
groovy -cp ./src/main/groovy ./scripts/import-model.groovyNow I can open the neo4j browser console (http://localhost:7474/browser/) and have a look at my model by executing the following Cypher query:
MATCH(n) RETURN n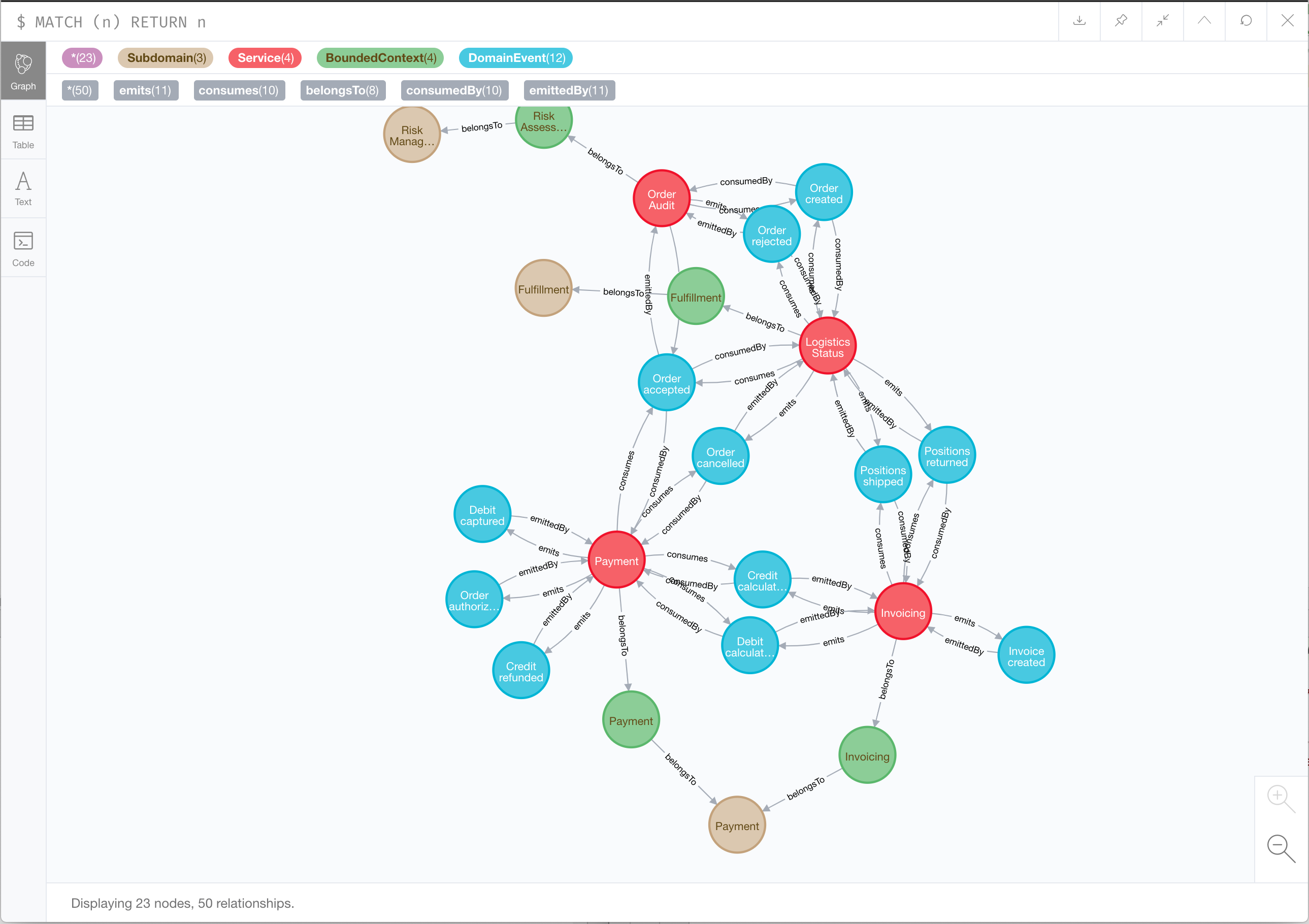
My example model is quite simple so the full model fits in one screen. Real project models will probably be much bigger and more complex. But you can use Cypher to select the interesting parts, e.g.
All Services that belong to a certain Bounded Context:
MATCH (s:Service) -- (b:BoundedContext{name:"Payment"}) RETURN s, bOr all Services that emit or consume a certain Domain Event:
MATCH (s:Service) -- (e:DomainEvent{name:"Order accepted"}) RETURN s, eBut you do not necessarily have to use neo4j to load and query the model. You can also use the ModelRepository (especially the InMemoryModelRepository) to do some basic queries. The following use-model.groovy script gives a simple example. It lists all Domain Events with their emitting and consuming Services:
@Grab("com.innoq:code-your-model:0.1")
@Grab("org.neo4j.driver:neo4j-java-driver:1.7.5")
import com.innoq.codeyourmodel.example.model.meta.*
import com.innoq.codeyourmodel.neo4j.Neo4JModelRepository
new Neo4JModelRepository("bolt://localhost:7687", "neo4j", "test").withCloseable { modelRepository ->
println "All Domain Events with their emitting and consuming Services"
println "-----"
modelRepository.findAll(DomainEvent)
.sort { a, b -> a.name <=> b.name }
.each {
println "* ${it.class.simpleName} '${it.name}'"
def emittedBy = modelRepository.findAllRelated(it, "emittedBy").collect {
"${it.class.simpleName} '${it.name}'"
}.join(", ")
println " emitted by: $emittedBy"
def consumedBy = modelRepository.findAllRelated(it, "consumedBy").collect {
"${it.class.simpleName} '${it.name}'"
}.join(", ")
println " consumed by: $consumedBy"
}
}That’s it for the moment.
The current version 0.1 is still a beta release and for sure contains some bugs and misses some features. It should be able to provide some benefit in keeping an overview of your project though, as I hope I’ve been able to show in this blog post.
As I mentioned before I already have a list of further improvements that I want to do in upcoming releases. Besides improving syntax, documentation, and log output (especially in case of errors) one of the main ideas is to introduce a web UI to browse the model without needing to know neo4j and the Cypher query language.
In addition to this I’m looking forward to any feedback I get from you when you use it. I’m pretty sure I missed some interesting features and there are more ideas how code-your-model can be improved or extended. So, feel free to try it out and send me your feedback, either as a comment below this blog post or via Twitter. Of course you can also create an issue or a pull request in the GitHub project.
Last but not least I want to thank INNOQ for allowing me to spend some of my time on stuff like this, and all my colleagues who listened to my (sometimes weird) ideas, gave me a lot of useful feedback and helped me getting this project published.