
I previously wrote about simplicity and how it helps to understand software code. In that post I already mentioned the usage of concepts like set theory. I’d like to expand on this and show how to boost readability of code.
Despite what people might think, our main purpose as developers is not writing software, but solving problems. Code is just a means, not the goal. Nobody demands software just for the sake of it from a developer. Applications need to solve whatever problems our customers need to have solved. This point of view on why we are here also changes what software is. It ceases to be a merely different formulation of a solution that is specified somewhere, it is the solution. But this requires us to think differently about what it is we are doing, and how we’re doing it.
Code is the ultimate truth, as they say. After all, this is what is executed in production, not some written specification, diagrams, JIRA tickets, or the ideas we’re keeping in our heads. The problem is, that if the code is the solution, then there are a few groups of people that need to understand it. The first one is developers, after all we’re closest to it, we’re writing it, it’s our bread and butter, our life. The second group is the stakeholders or customers, who are defining how the systems should behave. Maybe some other groups, like operations, are also interested to understand how the system will behave, or with what other systems it interacts.
Let’s do a small experiment. Below is a piece of code. Please take a look at this and try to name the algorithm that is implemented here.
int n = arr.length;
int temp = 0;
for (int i = 0; i < n; i++) {
for (int j = 1; j < (n - i); j++) {
if (arr[j - 1] > arr[j]) {
temp = arr[j - 1];
arr[j - 1] = arr[j];
arr[j] = temp;
}
}
}It’s bubble sort, but it probably took you a few seconds to find out. If I just wrote bubbleSort(arr), you’d know immediately what it does, how it’s done, and a few other properties of the algorithm, like it’s terrible performance for bigger arrays. The only trick I used was to name this piece of code, and this name refers to something you already know. If you don’t, it’s very easy to find out.
My point is, that by using known concepts we can make the code shorter and more understandable. This piece of code is 11 lines long, merely calling a function takes just one line. Of course, those 11 lines need to be written somewhere, but we can hide them deeper in our code, outside of the part where the “business logic” lives.
Those concepts can be anything. I mentioned a pretty obvious one, making elements of a collection ordered in some way, it’s called sorting, everybody knows it. Another example could be set theory with such operations like intersection, set difference or cartesian product. After all, our applications are about data processing, and it’s never about one “data”. Yet another example of such concept could be design patterns, which are re-usable solutions to well understood problems. Once a developer hears about, for instance, a decorator pattern, he or she should immediately understand what to expect.
There’s a really nice tweet from Mario Fusco: 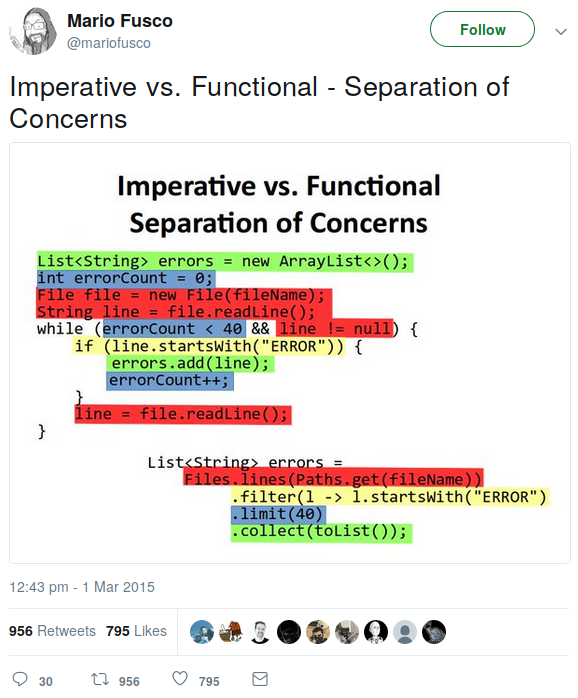
Although it’s a bit biased towards the functional way, and imperative code can definitely be improved (see discussion below the tweet), it clearly shows some benefits of using pre-existing ideas, monadic function composition in this case. Knowledge of such a technique, coming from the functional world and now being more and more adopted in OOP world, enables not only a better separation of concerns, but also more descriptive code. I’d argue, that the functional code says more what it does, imperative code is more about how to achieve it. Because of that, the functional code is more readable and understandable; it conveys intention. And it’s just an example, I’m not trying to say, that functional programming is always or usually better than object oriented or procedural approach. But because in functional world certain mathematical abstracts are much more present or natural, also the code can be far easier expressed in terms of those abstractions.
Why is it so important to go for known things? Because they tend to “disappear” from the sight and leave more space for other, usually more important matters. Once we can refer to some external knowledge, our brains don’t need to worry about that part any more. If I know what “intersection” from set theory means, then understanding a.intersect(b); is trivial. I don’t even see the dot, the semicolon and the brackets any more. If I wrote a.commonElements(b);, I’d probably force myself and others to think about or find out in the code what is meant by commonElements. It would be one more thing to keep in my head, in my working memory.
This memory is however very small. It can keep approximately 7 “things” at the same time. Once we exceed our own limit, we’re loosing the whole picture, we cannot comprehend the whole problem as one any more (by the way, this is also the moment where bugs start to creep into our code). If we refer to something we already know, then those concepts don’t need to “take up space” in our working memory, so it’s easier and faster to reason about the code.
A different aspect of understanding has to do with the language we’re using. The software we’re writing is a type of a mental model. Those models try to reflect real life as much as possible or necessary. They can also have theories built around them helping us deal with real life or decide what to do. Those models and our software should be as close as possible to real life models to reduce friction between them. Any differences are bug breeding grounds, and very time consuming to work with. Every time we see parts of the code, that show inconsistencies, we need to think about whether the code indeed reflects reality, or whether it looks like it looks, because we were unable to express reality in a better way.
This whole idea plays very well with ubiquitous language, an integral part of Domain Driven Design. It states, that there should be only one common language used to talk about the problem we’re trying to solve, no matter who’s talking to whom, developers, testers, business people, and also in the code. It makes sense; why would we want to “translate” between code, documentation and spoken language, after all, we’re talking about the same things. In such translations we’d be loosing important details, and it also takes time and effort.
If such a language doesn’t exist yet, we should create it. Or rather, like agile or extreme programming proposes, use metaphors. That way, although there’s no language specific to the kind of problem we’re trying to solve, there is a similar concept from which we then can borrow. This will also help in communication between people; instead of describing terms every time we need to, or giving them some artificial names, we can use terms from this other domain. Their power is, that they already have a meaning in the context we’re interested in. It will also greatly speed up bringing new people to the project or talking about the project outside.
Code written using ubiquitous language or metaphors will also reveal its intent much quicker. It’s a very important property of a simple design. Such design leads to quicker software development and only implementing what is actually needed. If we can split our big problem into smaller ones and properly separate the concerns, we have higher chances of being able to use ubiquitous language directly in the code, thus making it more understandable. Our code should be talking more about the actual problem it’s trying to solve, than any technical solution it uses, like libraries, frameworks or databases.
This also might have the additional benefit of not having to write code at all. Chances are, that for any problem that is not core and unique to our business, someone already solved it, and there is a library available. If we use this library, we’ll save ourselves the time writing and maintaining it, and we’ll be able to focus more on important matters. It will, again, make the code more understandable, because there will be less code to understand. We should also remember, that our task is to solve problems, not to write code, and we should only work on something that differentiates our companies from the competition. This is where profit is generated, commodity code has already been written, all companies can get it, so there’s no real advantage here.
As you can clearly see by the sheer amount of topics and concepts I mentioned in this post, it’s not so easy to keep our code understandable. And I didn’t even mention all of them. It also means, that we can make our code difficult to read in so many ways. But I believe, that it is in our common goal to make our code more readable and understandable. This not only makes working with such code easier, but helps us to deliver value faster.
Happy coding!