

Niemand hatte Josef K. verleumdet, allerdings hatte er in dieser Woche wieder Bereitschaftsdienst. Und das bedeutete meistens viel Ärger. Er war Software-Entwickler beim Reisedienstleister „30 Days of Happiness” und Teil des Teams, welches das Flugbuchungssystem „Always Available” entwickelt hatte. Dieses System ermöglichte es den firmeneigenen Reisebüros, über ein einheitliches Benutzerinterface Flugbuchungen bei allen Flugesellschaften des Landes zu tätigen. Die Systeme der einzelnen Airlines waren über sehr unterschiedliche Technologien mit „Always Availabe” verbunden und leider waren sie nicht immer zuverlässig.
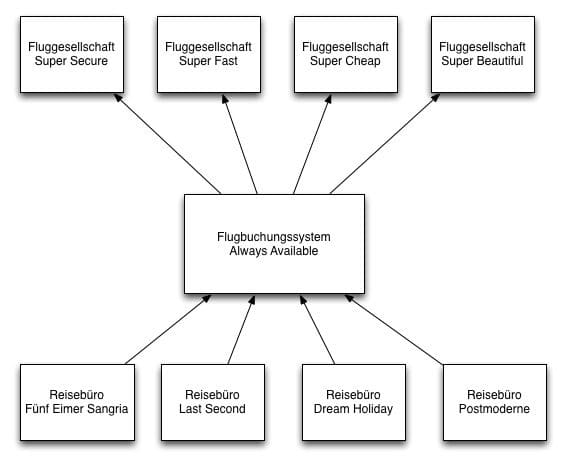
Um mit den aktuellsten Informationen zu arbeiten, wurde immer in Echtzeit mit den Airline-Systemen kommuniziert. Wenn zum Beispiel ein Kunde im Reisebüro „Dream Holiday” einen Flug von Köln nach Barcelona suchte, wurde über das System des Reisebüros eine Anfrage zu „Always Available” geschickt. Dieses schickte dann der Reihe nach Requests zu den einzelnen Airline-Systemen, um nach einem geeigneten Flug im gewünschten Zeitraum zu suchen. Es war schon oft vorgekommen, dass ein einzelnes Airline-System das ganze Flugbuchungssystem zum Stillstand brachte, weil es nur noch Threads gab, die auf das nicht funktionierende Airline-System warteten.
Und so war es auch dieses Mal. Alles stand still und das Telefon klingelte ununterbrochen. Man konnte das Flugbuchungssystem zwar über Konfigurations-Files von einzelnen Airline-Systemen abkoppeln. Das erforderte aber einen Neustart der gesamten Anwendung. Und wie immer wusste er nicht, welches der Airline-Systeme dieses Mal für die Probleme verantwortlich war.
Stabilitätspatterns zur Rettung
Offensichtlich hatte man bei der Entwicklung von „Allways Available” einige der grundlegenden Stabilitätspatterns für verteilte Anwendungen missachtet. Diese werden von Michael Nygard in seinem immer noch sehr empfehlenswerten Buch „Release It!” [1] ausführlich beschrieben und sollen hier kurz zusammengefasst werden.
Timeout
Netzwerke sind niemals zu 100% zuverlässig, deshalb sollten alle externen Ressourcen-Zugriffe, die Threads blockieren können, über Timeouts verfügen. Erhält die eigene Anwendung nach einer definierten Zeitspanne keine Antwort der externen Ressource, dann wird die Aktion abgebrochen, um den weiteren Betrieb der eigenen Anwendung nicht zu gefährden.
Circuit Breaker
Circuit Breaker (deutsch: Sicherung) funktionieren ähnlich wie Sicherungen im Haushalt, die Stromnetze vor Überlastung schützen. Übertragen auf den Bereich der Software-Entwicklung bedeutet das, dass für einen bestimmten Zeitraum alle weiteren Aufrufe zu einem externen System unterbunden werden, wenn festgestellt wird, dass es überlastet ist bzw. zur Zeit nicht zur Verfügung steht. Das erspart überflüssiges Warten und das Blockieren von Threadpools.
Bulkheads
Ursprünglich sind Bulkheads die Schotten eines Schiffes, die den Rumpf in mehrere voneinander abtrennbare Bereiche untergliedern. Schlägt das Schiff leck, kann der betroffene Bereich durch ein Schott isoliert werden und das Wasser kann sich nicht mehr ungehindert im Rumpf ausbreiten. Ähnlich verhält es sich bei der Entwicklung von verteilten Anwendungen. Die Ressourcen, die ein System zum Überleben benötigt, werden in unterschiedliche Gruppen unterteilt, die voneinander völlig unabhängig sind. Bei diesen Ressourcen kann es sich beispielsweise um Threadpools oder Instanzen einer Anwendung handeln. Bulkheads verhindern, dass Fehler kaskadieren, indem sie ihre Auswirkungen lokal begrenzen.
Steady State
Jede Anwendung sollte mit den von ihr benötigten Ressourcen nachhaltig umgehen, indem sie langfristig mindestens so viele Ressourcen wieder freigibt, wie sie verbraucht. Ziel muss es sein, dass ein einmal deploytes System sich über seine gesamte Lebenszeit in einem stabilen Zustand(„steady state”) befindet.
Fail Fast
Anfragen, die nicht erfolgreich bearbeitet werden können, sollten so schnell wie möglich vom Server unterbrochen und mit einer aussagekräftigen Fehlerbeschreibung beantwortet werden. Dieses Vorgehen schont sowohl die Ressourcen des eigenen Systems als auch die aller abhängigen Systeme.
Handshaking
Bevor ein Client einen Server mit Anfragen flutet, sollte er sich vom Server bestätigen lassen, dass dieser auch wirklich bereit ist, die folgenden Anfragen zu verarbeiten.
Test Harness
Remote Zugriffe bringen eine Reihe von Unwägbarkeiten mit sich. Unkalkulierbare Randbedingungen treten aber oft nur in der Produktions- und nicht in kontrollierbaren Integrationtestumgebungen auf. Um seine eigene Anwendung gegen Grenzfälle abzuhärten, sollte man explizit auch solche Szenarien in Tests berücksichtigen und Grenzsituation gezielt herbeiführen.
Decoupling Middleware
Um Systeme voneinander zu entkoppeln, können z.B. Messaging Systeme eingesetzt werden. Durch die persistente Ablage der Messages kann ein zwischenzeitlicher Ausfall eines Teilsystems kompensiert werden.
Vorhang auf für Hystrix
Die Stabilität eines Systems sollte natürlich von Anfang an als wichtige nicht-funktionale Anforderung bei der Entwicklung der Systemarchitektur Berücksichtigung finden. Die dargestellten Patterns können dabei als hilfreiche Richtschnur dienen, auf deren Basis sinnvolle Entwurfsentscheidungen getroffen werden können. Diese Erkenntnis kommt für Herrn K. leider zu spät. Das System ist bereits produktiv und wir wissen alle, wie schwierig es ist, die Architektur eines Systems nachträglich zu verändern. Aber vielleicht sollte er sich einmal Hystrix [2] anschauen.
Hystrix wurde vom Video-On-Demand-Anbieter Netflix entwickelt und wird der Entwicklergemeinde unter der Apache Licence zur Verfügung gestellt. Die Bibliothek unterstützt den Programmierer bei der Entwicklung von robusten, verteilten Anwendungen, indem Interaktionen mit externen Systemen, Services oder Bibliotheken gekapselt und vom eigenen System isoliert werden. Dieses wird dadurch in die Lage versetzt, auch dann weiter robust funktionieren zu können, wenn eine der Abhängigkeiten temporär ausfällt.
Hystrix und die Patterns
Hystrix ermöglicht es, einen Teil der beschriebenen Stabilitätspatterns auf einfache Weise in das eigene System zu integrieren. Die Integration gelingt, indem potentiell stabilitätsgefährdende Aktionen innerhalb eines Hystrix-Commands gekapselt und ausgeführt werden. Jedes Command kann dabei neben der eigentlichen Aktion auch eine Fallback-Aktion definieren, die aufgerufen wird, wenn die eigentliche Aktion nicht erfolgreich durchgeführt werden konnte.
Jedes Hystrix-Command wird durch einen Circuit-Breaker überwacht. Dieser protokolliert den Erfolg jedes Aufrufes und prüft, ob ein definierter Schwellwert für fehlerhafte Aufrufe überschritten wurde. In diesem Fall öffnet sich die Sicherung und weitere Aufrufe werden blockiert. Bei geöffnetem Circuit-Breaker wird immer direkt die implementierte Fallback-Aktion durchgeführt. Um festzustellen, ob das andere System wieder zur Verfügung steht, wird in regelmäßigen Abständen ein geringer Anteil von Aufrufen dieses Hystrix-Commands regulär ausgeführt. Wenn dieses wiederholt zum Erfolg führt, dann wird die Sicherung erneut geschlossen und das fremde Systeme kann wie gewohnt aufgerufen werden.
Um die Abhängigkeiten zu anderen Systemen auch untereinander zu isolieren, verwendet Hystrix Bulkheads. Standardmäßig wird jedes Hystrix-Command in einem eigenständigen Thread ausgeführt. Dabei wird jedem abhängigen System ein eigener unabhängiger Threadpool zugeordnet, so dass andere Systeme weiterhin aufgerufen werden können, wenn der Threadpool für ein einzelnes fremdes System bereits blockiert ist.
Für jedes Hystrix-Command lassen sich Timeouts festgelegen. Dabei ist allerdings Vorsicht geboten. Das Hystrix-Timeout legt nur die Zeitspanne fest, nach der Hystrix die Kontrolle wieder an den eigentlichen Applikationsthread zurückgibt. Der Thread des jeweiligen Clients läuft weiter und kann nur dann wieder freigegeben werden, wenn dieser selbst ein Timeout implementiert hat oder sich irgendwann mit einer normalen Antwort oder einem Fehler zurückmeldet. Der Hystrix-Timeout verhindert also nicht, dass der entsprechende Threadpool volläuft, er verhindert nur das der jeweilige Applikationsthread darauf wartet.
„Always Available” wird immer erreichbar
Aber genug der grauen Theorie. Das Flugbuchungssystem von Herrn K. ist ein idealer Kandidat, um Hystrix in der freien Wildbahn zu erleben. Im aktuellen und sehr fragilen Zustand sind die Fluginformationssysteme der einzelnen Airlines über Remote-Aufrufe angebunden. Listing 1 zeigt die stark vereinfachte bisherige Implementierung eines Aufrufes.
// Ungesicherter Aufruf eines Airline-Systems zur Abfrage von Flugdaten
public List<FlightOffer> findFlightOffers(String destination, DateTime departure) {
ClientResponse clientResponse = Client.create()
.resource("http://super-cheap/flights/")
.queryParam("departure", departure.toString())
.queryParam("destination", destination.toString())
.get(ClientResponse.class);
return toFlightOffers(clientResponse);
}Dieses recht harmlos aussehende Stück Code ist eine der Ursachen für Herrn K’s nächtliche Ruhestörungen. Der verwendete Jersey Client setzt im Default keinen Timeout und der gesamte Aufruf erfolgt mittels des allgemeinen Threadpools des Webservers. Antwortet das Airline-Systeme nicht oder zu langsam, werden nach und nach alle Threads der Anwendung blockiert. Das klassische Beispiel eines kaskadierenden Fehlers. Die Ausfallwahrscheinlichkeit steigt dabei mit jedem angeschlossenen externen Airline-System.
Hystrix kann hier, wie beschrieben, Abhilfe schaffen, indem der unsichere Aufruf in der run-Methode eines Hystrix-Command gekapselt wird (s. Listing 2).
// Der gleiche Aufruf gekapselt in einem HystrixCommand und
// damit durch einen Circuit Breaker abgesichert.
public class SuperCheapFlightOffers extends HystrixCommand<List<FlightOffer>> {
private final String destination;
private final DateTime departure;
protected SuperCheapFlightOffers(String destination, DateTime departure) {
super(HystrixCommandGroupKey.Factory.asKey("SuperCheap"));
this.destination = destination;
this.departure = departure;
}
@Override
protected List<FlightOffer> run() throws Exception {
// potentiell unsicherer Aufruf
return findFlightOffers(destination, departure);
}
}Hystrix setzt einen Timeout und verlagert die Ausführung in einen separaten Threadpool, welcher durch das Setzen des Group-Keys (hier „SuperCheap”) bestimmt wird. Damit ist die Gefahr von blockierten Threads im Threadpool der Anwendung gebannt. Wie beschrieben macht es trotzdem Sinn auch noch den Jersey-Timeout zu setzen, um eine Blockade des jeweiligen Hystrix-Threads zu verhindern.
Auf der Ebene der Ressourcen ist „Always Available” nun entkoppelt. Aktuell würde allerdings im Falle eines Timeouts, eines Fehlers oder eines offenen Circuit-Breakers eine HystrixRuntimeException ausgelöst, die von jedem Aufrufer behandelt werden müsste. Das macht dann Sinn, wenn die durchgeführte Aktion als gescheitert anzusehen ist und kein sinnvoller Fallback möglich ist. In den Nygardschen Stabilitätspatterns findet sich dieser Ansatz als Fail-Fast-Pattern wieder.
Für „Allways Available” lässt sich aber durch Überschreiben der getFallback-Methode ein sinnvoller fachlicher Fallback hinzufügen (Listing 3).
public class SuperCheapFlightOffers extends HystrixCommand<List<FlightOffer>> {
private final String destination;
private final DateTime departure;
protected SuperCheapFlightOffers(String destination, DateTime departure) {
// ...
}
@Override
protected List<FlightOffer> run() throws Exception {
// ...
}
@Override
protected List<FlightOffer> getFallback() {
// Fail silent
return Collections.emptyList();
}Im Fehlerfall wird einfach eine leere Liste zurückgegeben, da das jeweilige System schließlich momentan keine Angebote liefern konnte. Es wird ein sinnvolles Ergebnis zurückgeliefert und die Suche kann fortgesetzt werden. Eine Fail-Silent-Strategie ist hier fachlich eine saubere Lösung.
Ausgefeiltere Fallback-Strategien sind ebenfalls denkbar. Statt einer leeren Liste könnten wir die zuletzt gecachten Daten zurückgeben oder ein Backup System aufrufen. Dieser Aufruf könnte erneut in einem Hystrix-Command erfolgen, da auch die Schachtelung von Commands möglich ist.
Hystrix-Commands können auf unterschiedliche Weise ausgeführt werden. Die einfachste Art ist die synchrone Ausführung mittels execute (Listing 4).
public List<FlightOffer> search(String dest, DateTime depa) {
List<FlightOffer> ofs1 = new SuperCheapFlightOffers(dest, depa).execute();
List<FlightOffer> ofs2 = new SuperBeautifulFlightOffers(dest, depa).execute();
List<FlightOffer> ofs3 = new SuperFastFlightOffers(dest, depa).execute();
List<FlightOffer> ofs4 = new SuperSecureFlightOffers(dest, depa).execute();
return collectAll(ofs1, ofs2, ofs3, ofs4);
}Die Abfrage der einzelnen Airline-Systeme erfolgt damit serialisiert. Es entsteht dabei viel Leerlauf durch unnötige Wartezeiten auf Prozesse, die
eigentlich parallel ablaufen könnten. Die parallele Verarbeitung wird durch die Methode queue ermöglicht. Als Ergebnis werden Futures
zurückgegeben, die erst dann ausgewertet werden müssen, wenn die Ergebnisse zusammenführt werden sollen (Listing 5).
public Iterable<FlightOffer> search(String dest, DateTime dep) {
Future<List<FlightOffer>> future1 = new SuperCheapFlightOffers(dest, dep).queue();
Future<List<FlightOffer>> future2 = new SuperBeautifulFlightOffers(dest, dep).queue();
...
try {
List<FlightOffer> offers1 = future1.get();
List<FlightOffer> offers2 = future2.get();
...
return CollectionUtils.union(offers1, offers2,...);
} catch (InterruptedException | ExecutionException e) {
logger.error("unexpected exception", e);
return Collections.emptyList();
}
}In dieser Version werden zunächst alle Requests der Reihe nach ausgelöst, ohne auf ein Ergebnis zu warten, so dass sie parallel von den einzelnen Systemen abgearbeitet werden können. Danach werden die Ergebnisse der Reihe nach eingesammelt. Die get-Methode der Futures blockiert zwar den Applikationsthread, solange ein Ergebnis noch nicht vorliegt, das ist aber unproblematisch, da in der Zwischenzeit die anderen Futures weiter befüllt werden können.
Man kann das Ganze aber noch eleganter lösen. Durch den Aufruf der observe Methode lässt sich Hystrix reaktiv ausführen. Das ist kein Zufall,
da RxJava [3] ebenfalls aus dem Hause Netflix stammt. Mit JavaRX lassen sich asynchrone Operationen elegant im Code miteinander verknüpfen. Damit
lässt sich der vorherige Aufruf deutlich kompakter und weniger fehlerträchtig implementieren (Listing 8).
public Iterable<FlightOffer> search(String dest, DateTime dep) {
Observable<List<FlightOffer>> obs1 = new SuperCheapFlightOffers(dest, dep).observe();
Observable<List<FlightOffer>> obs2 = new SuperBeautifulFlightOffers(dest, dep).observe();
// Parallele Abfrage aller System mit einem kombinierten Ergebnis
Collection<FlightOffer> combinedResult = Observable
.combineLatest(obs1, obs2, CollectionUtils::union)
.toBlockingObservable()
.first();
return combinedResult;
}Alle Abfragen werden weiterhin, durch Hystrix abgesichert, parallel ausgeführt. Und man erhält auf einfacherem Weg die Menge aller Ergebnisse. An dieser Stelle können wir uns leider nicht im Detail mit RxJava auseinandersetzen. Wir möchten Sie an dieser Stelle aber dazu ermutigen, einmal einen Blick in die sehr gute RxJava-Dokumentation zu werfen, um sich von den vielfältigen Einsatzmöglichkeiten überzeugen zu lassen. Es wäre mit RxJava zum Beispiel auch sehr einfach, nur das am schnellsten antwortende System oder nur die ersten 20 Fluganbote zu berücksichtigen.
Iterativ zur perfekten Konfiguration
Die Default-Einstellungen von Hystrix beruhen auf dem Praxiseinsatz bei Netflix und sind deshalb meist gut gewählt, passen aber nicht auf jedes Einsatzszenario. Zur Optimierung von Performance und Stabilität müssen individuelle Werte für die einzelnen Commands und Pools gefunden werden. Dafür werden zwingend Metriken aus dem produktiven Betrieb benötigt, die Aufschluss über das wirkliche Verhalten eines Systems geben.
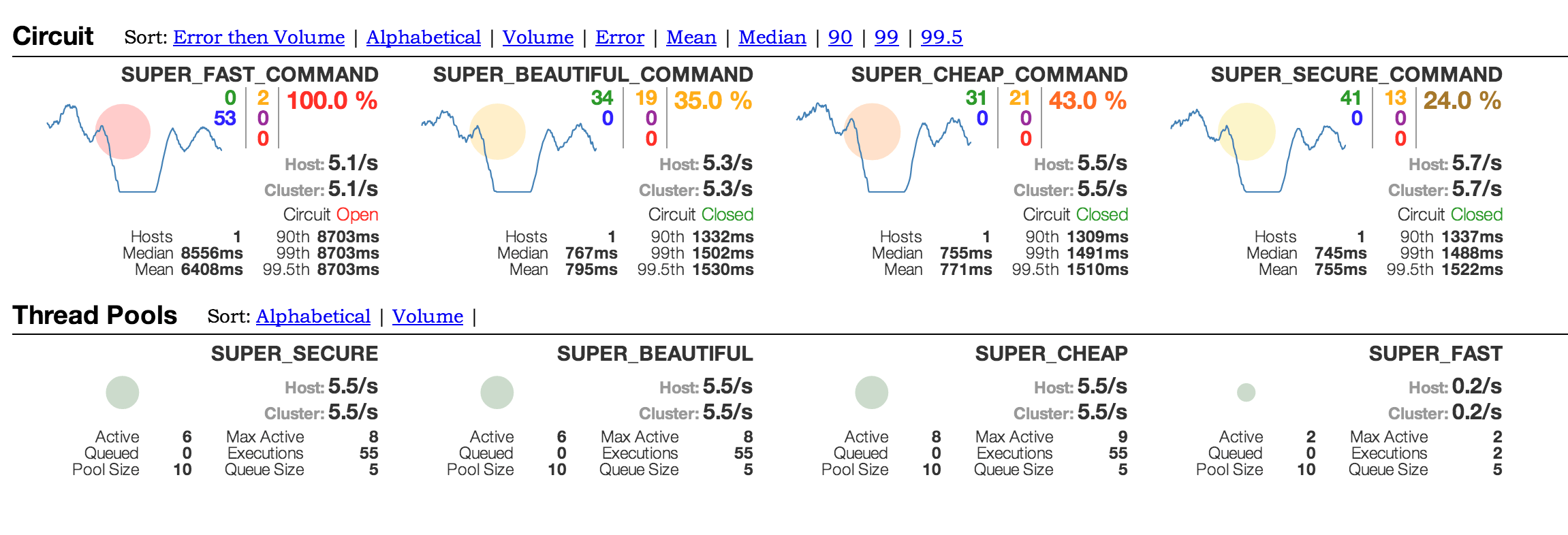
Hier kommt ein weiteres Feature von Hystrix ins Spiel. Jede Hystrix-Entität, wie z.B. Commands, Curcuit Breaker oder Thread-Pools, veröffentlicht sowohl eingetretene Events als auch ihren aktuellen Zustand über einen kontinuierlichen Aktivitätsstream. Dieser kann in unterschiedlichen Formaten ausgegeben und auf unterschiedlichen Wegen visuell aufbereitet werden. Out of the Box bietet Netflix für diesen Zweck das so genannte Hystrix-Dashboard [4] an, welches den aktuellen Zustand jedes Commands der Anwendung übersichtlich darstellt (Dashboard). Wenn es mehrere Instanzen der Anwendung gibt, lassen sich die Aktivitätsströme mittels Turbine [5] bündeln, um sie dann ebenfalls mittels des Dashboards darzustellen. Weiterhin unterstützt werden Metriken von Bibliotheken wie Metrics [6] oder Servo [7], die sich dann z.B. mittels Graphite [8] individuell visualisieren lassen.
Die gewonnenen Metriken sollen aber nicht nur die Statistiker erfreuen, sondern können dazu genutzt werden, die Konfiguration im laufenden Betrieb anzupassen. Realisiert man beispielsweise, dass ein Threadpool zu knapp bemessen ist, kann man ihn so lange optimieren, bis eine bessere Performance zu beobachten ist. Dieses ist möglich, da Hystrix sowohl die Konfigurationsfiles auf Änderungen überwacht als auch alle Properties mittels JMX veröffentlicht. Hystrix bietet auf diese Weise viele Möglichkeiten, Feintuning zu betrieben, um das Verhalten eines Systems zu beeinflussen. Nur über diese iterative Verbesserung wird man zu einem wiklich stabilen und performanten System kommen.
Hystrix Performance Features
- Semaphore: Anstatt die Zahl von Aufrufen über Thread-Pools zu begrenzen, kann dieses auch über Semaphore geschehen. Dieses sollte nur erfolgen, wenn eine wirklich hohe Last auf dem Command keine Alternative lässt. Timeouts werden in diesem Fall nicht unterstützt.
- Request Collapser: Um die Anzahl von Requests zu reduzieren, können Anfragen zu Paketen zusammengefasst werden, eine gute Optimierung, wenn Netzwerkverbundungen knapp sind bei erhöhter Code Komplexität.
- Caching: Requests können mit einem Cache-Key versehen werden, um gleiche Abfragen direkt aus dem internen Hystrix Cache beantworten zu können.
Ein Fazit
Verteilte Systeme, welche die aufgeführten Stabilitätspatterns nicht durchgängig umsetzen, sind im besten Falle wackelig. Die konsequente Umsetzung aller Patterns geht allerdings mit einem beträchtlichen Aufwand einher und erfordert große Sorgfalt. Der Einsatz einer entsprechenden Bibliothek ist deshalb empfehlenswert und erleichtert die Umsetzung.
Hystrix ist aus unserer Sicht dabei eine gute Wahl. Die Software ist durch seinen Einsatz bei Netflix erprobt und hat sich auch in unseren Projekten bewährt. Dass Hystrix dabei statt Annotationen eine Integration über das Command-Patterns erfordert, gehört für uns zu seinen Vorzügen. Der Code wird ausdrucksstärker und signalisiert dem Entwickler deutlicher, dass ein potentiell unsicherer Aufruf vorliegt. Trotzdem ist auch der nachträgliche Einbau in bereits bestehende Anwendungen ohne Probleme möglich. Wirklich überzeugen kann das eingebaute Monitoring, welches sowohl die Ressourcen des eigenen Systems als auch die externen Abhängigkeiten, vielleicht zum ersten Mal, deutlich sicht- und messbar macht.
Sollte dieser Überblick für Neugier gesorgt haben, können wir die Lektüre der Hystrix Dokumentation empfehlen. Detailiert und umfassend geht sie auf alle Details ein, für die hier kein Platz war.
Aber ob sie sich nun für Hystrix entscheiden oder die Stabilität ihrer Anwendung durch andere Ansätze (wie z.B. kyte-lib [9] oder Akka [10]) erreichen, möchten wir Ihnen überlassen. Herr K. konnte nach dem Einbau von Hystrix jedenfalls endlich wieder ruhig schlafen.
Referenzen
-
Michael T. Nygard, Release It!: Design and Deploy Production-Ready Software, 2007 ↩︎
-
https://github.com/Netflix/Hystrix ↩︎
-
https://github.com/Netflix/RxJava ↩︎
-
https://github.com/Netflix/Hystrix/wiki/Dashboard ↩︎
-
https://github.com/Netflix/Turbine ↩︎
-
http://metrics.codahale.com/ ↩︎
-
https://github.com/Netflix/servo/wiki ↩︎
-
http://graphite.wikidot.com/ ↩︎
-
https://code.google.com/p/kite-lib/ ↩︎
-
http://doc.akka.io/docs/akka/snapshot/common/circuitbreaker.html ↩︎