
Nachdem wir verschiedene Microservice Frameworks ausprobiert hatten, entschieden wir uns letztlich für Spring Boot. Durch seine „Opinionated Presets” bietet dieses Framework eine konstant hohe Entwicklungsgeschwindigkeit. So waren wir relativ schnell in der Lage die Anforderungen des Kunden in drei Microservices umzusetzen, die jeweils eine kleine REST API anboten.
Schließlich bekamen wir von unseren Kollegen im Operations Team die Nachricht, dass sie für unsere Services eine Continuous Delivery Pipeline einrichten wollen. Dazu müssten wir uns aber entscheiden, wie denn die Services deployed werden sollen. Da wir bereits zwei unserer drei Innovation Tokens [1] für den Microservice-Ansatz und Spring Boot verbraucht hatten, haben wir die Vor- und Nachteile eines Docker-basierten Deployments nicht evaluiert.
Bei der Idee hinter “Innovation Tokens” geht es darum, dass man nicht zu viele Innovationen auf einmal einführt. Einerseits ist bei neuen Technologien nicht sicher, wie stabil sie bereits sind, bzw. unter welchen Szenarien sie sich nicht wie spezifiziert verhalten und man zusätzliche Zeit in ihre Stabilisierung investieren muss. Andererseits bringen sie immer Unbekannte mit sich, weil das Team noch keine Erfahrung mit ihnen gesammelt hat und hierfür Zeit aufbringen muss. Die Theorie ist, wenn man zu viele Innovationen auf einmal einführt, überfordert dies die Menschen im Projekt, weil man die Anzahl der beweglichen/ unbekannten Teile soweit erhöht, dass sie den Überblick verlieren. Durch diese Überforderung kommt Unzufriedenheit und zusätzliche Instabilität ins Projekt, was die Produktivität senkt. Stattdessen limitiert man die Anzahl der mit einem Projekt einführbaren Innovationen auf ein Maß, welches das Team tragen kann. Deshalb entschieden wir, uns als Deployment-Artefakt durch das Spring Boot Maven-Plugin ein self-executable JAR erstellen zu lassen. Für dessen Aufruf schrieben wir dann ein Shellskript, welches wir auf den Linux VMs, die als Zielsysteme geplant waren, zum Starten und Stoppen unserer Services verwenden konnten. Dies funktionierte so gut, dass wir uns mit dem Operations Team daran machten, den Deployment-Prozess zu automatisieren.
Konfigurationsmanagement
Hier unterstützte uns Spring Boot auf unvorhergesehene Weise, als es um die instanz-spezifische Konfiguration unserer Microservices ging: Konfigurationswerte (auch Properties) werden mit Spring Boot in einer application.properties oder application.yaml-Datei abgelegt, die entweder im JAR, im Dateisystem oder remote via HTTP verfügbar sein müssen. Diese Dateien bieten einerseits eine Unterstützung für Profile. Wenn man bspw. die Anwendung mit dem Profil „test” startet, werden alle Properties aus der application.yaml geladen und anschließend durch die Werte der gleichnamigen Properties überschrieben, die in der Datei application-test.yaml definiert wurden. So kann man bspw. Umgebungs-spezifische Werte in eigenen Dateien verwalten.
Andererseits gibt es auch die Möglichkeit, bestimmte Properties beim Start der Anwendung zu überschreiben. Dies kann entweder dadurch erfolgen, dass man die Property als Aufrufparameter mitgibt, oder eine Umgebungsvariable mit dem gleichen Namen definiert. Nutzern des Typesafe Stacks mögen diese Fähigkeiten bekannt vorkommen, denn Typesafe Configuration bietet sehr Ähnliches.
Zunächst probierten wir die Variante mit Umgebungsvariablen aus, da sie auch nach Rücksprache mit dem Operations Team sehr intuitiv zu sein schien. In der Realität führte sie aber zu Missverständnissen und Konfigurationsfehlern, denn es wurden eben keine Parameter explizit übergeben, sondern implizit die Variablen verwendet. Man musste also beim Starten der Applikation prüfen, ob alle notwendigen Variablen gesetzt sind. Was als “notwendig” angesehen wurde, hing hierbei allerdings von der Umgebung ab. Zu allem Überfluss war das Überprüfen der Variablen auch nicht intuitiv, denn während die Parameter dem Properties-Namensmuster wie server.port folgten, mussten die Umgebungsvariablen in Großbuchstaben und mit Unterstrichen statt Punkten - in unserem Fall SERVER_PORT - gesetzt werden.
Nach einigen Gesprächen mit anderen Teams entschieden wir uns dann, die application.yaml-Dateien im JAR zu belassen und einige Werte via Aufruf-Parameter zu überschreiben. Diese Variante die umgebungsspezifischen Konfigurationswerte als Aufruf-Parameter zu übergeben, wurde dann als favorisierte Variante von allen Teams als Makroarchitektur-Entscheidung festgehalten.
Kleine Experimente
Es zeigte sich relativ schnell, dass die Feedback Loops, also die Zeit vom ‘git push’ des Developers über den Jenkins-Build bis zur Rückmeldung, ob die Änderung erfolgreich deployed wurde und durch die automatisierten Cucumber-Akzeptanz-Tests gelaufen ist, deutlich kürzer waren als bei unseren anderen, größeren Systemen. Eine Änderung an einem Microservice brauchte nur noch ca. 6 Minuten bis sie zum manuellen Abnahmetest in die Produktion bereit stand. Durch dieses schnelle Feedback kam es immer häufiger zu Situationen, die wir „kleine Experimente” nannten: wir konnten Änderungen am Verhalten des Systems schnell ausprobieren, ohne zu lange über die Auswirkungen spekulieren zu müssen, denn wir konnten sie auch in kürzester Zeit wieder ausbauen.
Auch die Einstellung unseres Management-Teams wurde durch diese Beschleunigung verändert: Sie bemerkten, dass diese kleinen Änderungen deutlich weniger Risiko bedeuteten als die bisherigen großen Releases mit vielen Änderungen. Also entschieden sie, dass wir noch häufiger möglichst kleine Änderungen vornehmen sollten. Einige davon durften dann sogar ohne manuellen Abnahmetest in Produktion gehen, denn man wusste ja, dass man Änderungen, die zu Fehler führten, binnen Minuten entweder zurückdrehen oder durch eine weitere Auslieferung beheben konnte.
Integration
Trotz dieser Erfolgserlebnisse hatten wir immer noch das Zitat eines Kollegen aus dem Operations Team in den Ohren, der seinerzeit bei der Vorstellung unseres Microservice-Migrations-Projektes meinte, “Microservices sind auch nicht besser als das, was wir heute machen. Entwickler ignorieren, dass die Komplexität nicht verschwindet, sondern auf die Integrationsphase der Services verschoben wird. Denn darum müssen sich eben nicht mehr die Entwickler, sondern die Betriebsabteilung kümmern!”.
Wir wollten nun einerseits beweisen, dass Microservices auch im Betrieb viele Vorteile bringen, andererseits interessierte uns, welche Probleme hier wohl auf uns warten würden. Deshalb beschlossen wir, die Integrationsphase bereits während der Feature-Entwicklung zu starten. Konkret stellten wir direkt nach dem Aufsetzen der Deployment Pipeline die Konnektivität zwischen den deployten Service-Instanzen her. Und in der Tat tauchten hier viele Fragen auf, die wir so nicht vorhergesehen hatten:
- Da unsere Services APIs anderer Services anbinden, wie können wir sog. Deployment-Monolithen verhindern? Deployment-Monolithen sind eine Ansammlung kleiner Services, deren Kohäsion was APIs und Daten angeht aber so hoch ist, dass sie nur gemeinsam in Produktion gebracht werden können. Unsere Lösung hierfür waren einerseits abwärtskompatible APIs und Datenstrukturen für unsere eigenen Services und andererseits sog. „Consumer-Driven Contracts” für die APIs anderer Services. Letzteres waren aufgezeichnete Requests an die APIs der anderen Systeme. Diese gaben wir dann den anderen Teams, welche sie in die Deployment Pipeline ihrer Services einbinden konnten. Hierdurch bekam das andere Team direktes Feedback, wenn eine ihrer Änderungen die Abwärtskompatibilität brach, auf die sich einer unserer Services verließ.
- Der Service macht SSL-Offloading, wie kommen die entsprechenden SSL-Zertifikate auf die Instanzen, die durch das AWS Autoscaling beliebig erstellt und zerstört werden können?
- Die Instanzen unserer Services sind auf zwei AWS Availability Zones (vergleichbar mit zwei Rechenzentren) verteilt, um Ausfallsicherheit zu gewährleisten. Wie können wir gewährleisten, dass unsere Microservices, die andere Services aufrufen, diejenigen Instanzen bevorzugen, die in der gleichen Availability Zone deployed sind um die Latenz gering zu halten? Diesem Problem begegneten wir mit einem entsprechenden Konzept zur ServiceDiscovery. Clients verwendeten in ihren Anfragen an die ServiceRegistry entsprechende Attribute wie bspw. die Availability Zone. Die ServiceRegistry sortierte dann die Liste der zurückzugebenden Service-Instanzen nach diesen Attributen. In unserem Fall nutzten wir hierfür Netflix Eureka [2], gleiches ist aber auch mit Hashicorps Consul [3] realisierbar.
Aber auch scheinbar trivialere Dinge bereiteten einige Umstände. Als wir beispielsweise die erste Verbindung zwischen den Instanzen zweier Services herstellen wollten, hatten wir zwar den entsprechenden Port in der Firewall freigeschaltet, allerdings kamen die Requests nur bei einer der drei deployten Service-Instanzen an.
Logging
Das Troubleshooting hierzu erwies sich als äußerst mühselig, da wir uns immer per SSH auf den jeweiligen Server verbinden mussten, um dort die Log-Dateien einsehen zu können. Hierbei kam schnell der Wunsch auf, diese Dateien in einem zentralen Logsystem vorhalten und durchsuchen zu können. Da wir aber nicht viel Zeit mit Einrichtung und initialer Konfiguration verlieren wollten, setzten wir auf einem Testsystem kurzerhand einen docker-basierten ELK-Stack [4] auf. In diesem Docker-Image waren ElasticSearch, Logstash und Kibana bereits vorkonfiguriert enthalten. Auf den Hosts unserer Services installierten wir jeweils eine weitere Logstash-Instanz [5], die, mit einer entsprechenden Konfiguration, die Log-Dateien direkt nach ElasticSearch importierte, so dass diese in Kibana durchsuchbar waren. Obwohl wir diesen docker-basierten Stack für die Produktion erstmal ausschlossen, funktionierte er im Testsystem gut und ließ uns so Erfahrung mit diesen Technologien sammeln.
Durch dieses zentralisierte Log-Management waren wir beim Troubleshooting nun wesentlich schneller. Allerdings stellten wir fest, dass sich bestimmte Fehlerszenarien nur nachvollziehen ließen, wenn wir die Anwendung im DEBUG-Level laufen ließen. Generell immer das DEBUG- Level zu aktivieren, würde aber zu viele unnötige Daten erzeugen, welche die Infrastruktur belasteten, denn wir brauchten es ja nur für bestimmte Requests. Um das DEBUG-Level nun ohne Konfigurationsanpassung oder Neustart der Services für diese bestimmten Requests aktivieren zu können, implementierten wir ein Konzept zum "per Request Debugging” [6]. Da wir den Request gerne auch in den Logs der anderen Services verfolgen wollten, handelte es sich hierbei um ein Service-übergreifendes Thema, was damit zur Makroarchitektur gehört. Wir beschrieben das Logging-Konzept deshalb im gemeinsamen Confluence-Space für alle Teams, damit auch andere Services “per Request Debugging” implementieren konnten. Dieses Logging-Konzept wurde später auch um ein gemeinsames Verständnis der Semantik von Log-Leveln und einige andere Punkte erweitert, da sich herausstellte, dass auch andere Teams an den Logs unserer Services interessiert waren, so wie wir die Logs ihrer Services in Kibana zum Troubleshooting benötigten.
Monitoring und Alarming
Die neuen Möglichkeiten schnelles Feedback auf Änderungen zu erhalten, führten wie oben erwähnt dazu, dass das Management mutig wurde und einige Änderungen ohne manuelles Testing in die Produktionsumgebung released wurden. Man stellte uns die Frage, „Woran könnt ihr erkennen, ob das Deployment der letzten Änderung zu Problemen in Produktion führt?“ Diese Frage lässt sich schnell mit einem „Wir schauen aufs Monitoring“ beantworten, allerdings liegt die Herausforderung hier im Detail, was genau für welche Art Änderung überwacht werden muss. Und vor allem wie.
Beim Blick auf unser Monitoring stellten wir fest, dass das Operations Team bisher nur Nagios im Einsatz hatte, um die Hostsysteme zu überwachen. Nagios führte sog. Checks aus um Systemmetriken wie CPU und RAM Auslastung, Network I/O und laufende Prozesse einzusammeln, und konnte Alarme per Email verschicken, wenn diese Systemmetriken vorher definierte Grenzwerte überschritten.
Es gab aber keinerlei Überwachung von Applikations- oder Businessmetriken. Applikationsmetriken wären zum Beispiel die Auslastung eines Tomcat Threadpools und seiner Queue oder die Garbage Collector Statistiken. Businessmetriken können das Verhältnis von Warenkorb-Checkouts zu abgeschlossenen Orders, angefangene zu abgeschlossene Registrierungen, die Anzahl erfolgreicher Logins im Verhältnis zu der Anzahl an Aufrufen der Loginseite oder einfach die durchschnittliche Verweildauer auf der Webseite sein. Gerade um bei den Businessmetriken Anomalien festzustellen, müssen sich Product Owner und Team intensiv Gedanken machen, woran man den Norm-Wert festmacht. Denn Norm-Werte sind immer Schwankungen unterlegen. So reicht es nicht, die Anzahl der erfolgreichen Logins zu überwachen, denn diese wird Sonntag morgens um 03:00 Uhr vermutlich deutlich niedriger sein als Montag Abends um 18:00 Uhr.
Neben der Festlegung, welche Metriken wir denn überwachen mussten, blieb für uns noch die Entscheidung offen, wie wir diese Metriken am besten visualisieren und überwachen. Hier schied Nagios relativ schnell aus, denn dafür war es nicht konzipiert. Zum Glück hatten wir uns noch eines unserer drei Innovation-Tokens aufbewahrt, so dass wir uns einige Monitoring-Stacks und hier vor allem Timeseries-Databases ansehen konnten. Zunächst evaluierten wir die Timeseries-Datenbank “Graphite”, welche seit Jahren auf dem Markt ist, deren Weiterentwicklung in den letzten Monaten allerdings nur sehr langsam voran ging. Im Vergleich dazu erschien uns InfluxDB und der darum entstehende Monitoring-Stack eine gute Option zu sein. Wir setzten deshalb eine zentrale InfluxDB [7] auf und wählten Grafana [8] für die Visualierung der Metriken. Auf jedem Host in unserem Testsystem installierten wir telegraf [9], welches die Systemmetriken sammelte und in die InfluxDB exportierte. In unsere Spring Boot Anwendungen bauten wir die Dropwizard Metrics Library [10] ein, welche Applikations- und Businessmetriken über einen Exporter ebenfalls an InfluxDB senden konnte. Da unser Operations-Team sehr viel Expertise mit Nagios aufgebaut hatte und es unbedingt weiterhin für das Alarming verwenden wollte, definierten wir mit ihnen zusammen Nagios Checks, die Metriken über die InfluxDB HTTPS-API abfragten und beim Überschreiten von Schwellwerten Alarme verschickten. Anschließend führten wir einige Lasttests durch, um die Stabilität dieses Stacks unter der erwarteten Last zu prüfen.
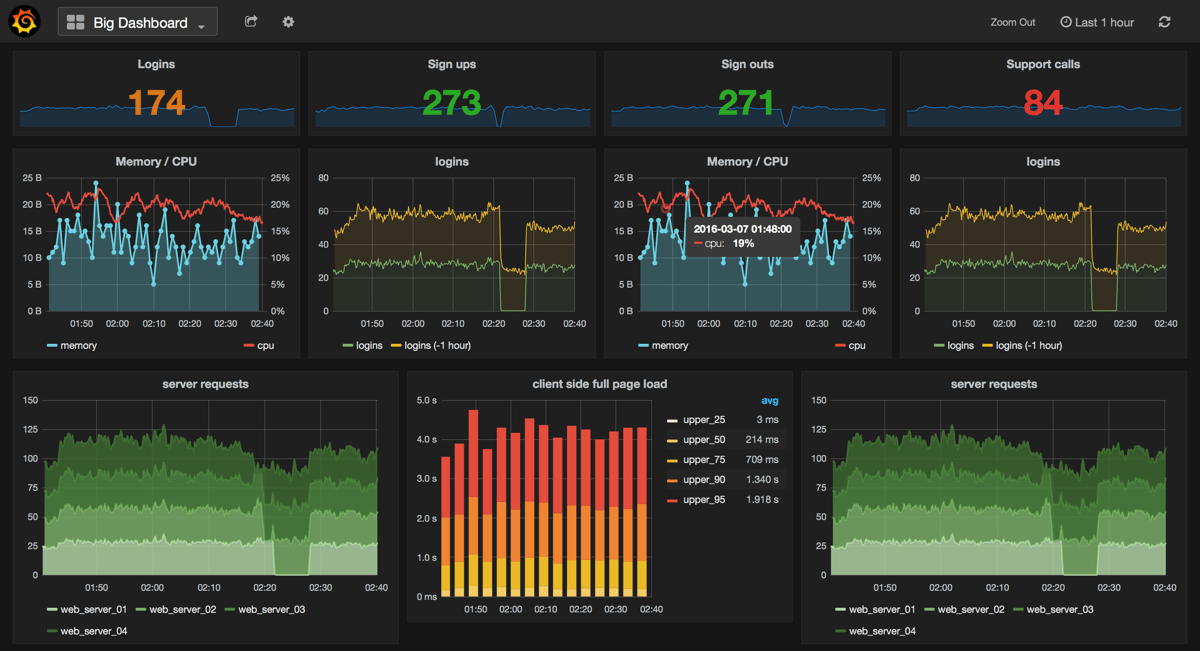
Die Benutzeroberfläche von Grafana überzeugte uns auf Anhieb. Wir konnten verschiedene Dashboards für unsere Stakeholder und deren unterschiedliche Fragestellungen erstellen und diese sowohl untereinander als eine Art drill-down als auch mit externen Systemen wie bspw. Kibana- Dashboards verlinken. So hatte jeder Stakeholder sein eigenes Dashboard (siehe Abb. 1) und wir konnten uns auf unseren Dashboards zunächst einen Überblick verschaffen, in welchen Metriken sich das Nutzerverhalten widerspiegelte und entsprechend in Nagios Alarme auf diese Metriken und bspw. Fehler-Raten konfigurieren. Der typische Troubleshooting-Prozess sah dann so aus, dass wir von Nagios einen Alarm per EMail bekamen, welche einen Link auf das zugehörige Grafana- Dashboard enthielt. Dort verschafften wir uns einen Überblick der Lage und klickten uns bei Bedarf bis in Kibana-Dashboards durch, um dort - im von Grafana weitergereichten Zeitintervall - die Log-Events nach Ursachen der Anomalie zu durchsuchen.
Vollständige Automatisierung?
Mit dieser Überwachung im Rücken konnten wir nun Fehler nach einem Deployment in den meisten Fällen relativ schnell feststellen. Um das Risiko weiter zu reduzieren und noch schneller reagieren zu können, diskutierten wir die Einführung eines Gatekeeper-Services. Dieser Service erlaubt es, Traffic Shaping vorzunehmen. Der Traffic an unsere Systeme wird dabei in kleinen Schritten (z.B. +5% alle 5min) auf eine gerade neu deployte Version eines Services umgeleitet. Laufen die Requests an den neuen Service auf einen Fehler oder überschreiten Toleranzgrenzen, wird der umgeleitete Traffic-Anteil wieder reduziert. Ansonsten wird die Traffic-Zuleitung erhöht, bis der Service 100% des Produktions-Traffics behandelt. Ist dies für einen Zeitraum von zum Beispiel 30 Minuten stabil, wird die alte Version dieses Services abgeschaltet. Durch diese Art des Traffic-Shapings spart man nicht nur die Zeit für Lasttests, sondern auch die manuellen Tests einer Änderung. Diese Tests werden dann von einem gewissen Prozentsatz der Benutzer der Produktionssysteme durchgeführt.
Ein Produkt, das ein solches Feature-Paket mitbringen soll ist Fabio von eBay [11], welches unser Team als nächstes evaluieren möchte, sobald es wieder Innovation Tokens zur Verfügung hat.
Fazit: Microservice Deployment ist Team-Work
Geht man es richtig an, bringt der Umstieg auf Microservices Vorteile an vielen Stellen für Entwicklung und Betrieb. Den Teams muss die notwendige Unabhängigkeit eingeräumt werden, so dass sie den Anforderungen mit den passenden Antworten begegnen können. Microservices bedürfen aber auch eines gewissen Engagements der Teams, denn die richtigen Entscheidungen müssen sie im durch die Makro- und Domänenarchitektur [12] vorgegebenen Rahmen selbst treffen und für die Konsequenzen daraus einstehen. Gerade der Blick auf das Deployment der eigenen Services und die daraus entstehenden Fragen können für viele Teams eine neue Perspektive eröffnen. Da Microservices sehr klein sind und eine geringe fachliche Komplexität haben, können Teams sich diese neue Sichtweise Schritt für Schritt erschließen, ohne direkt davon überfordert zu werden.
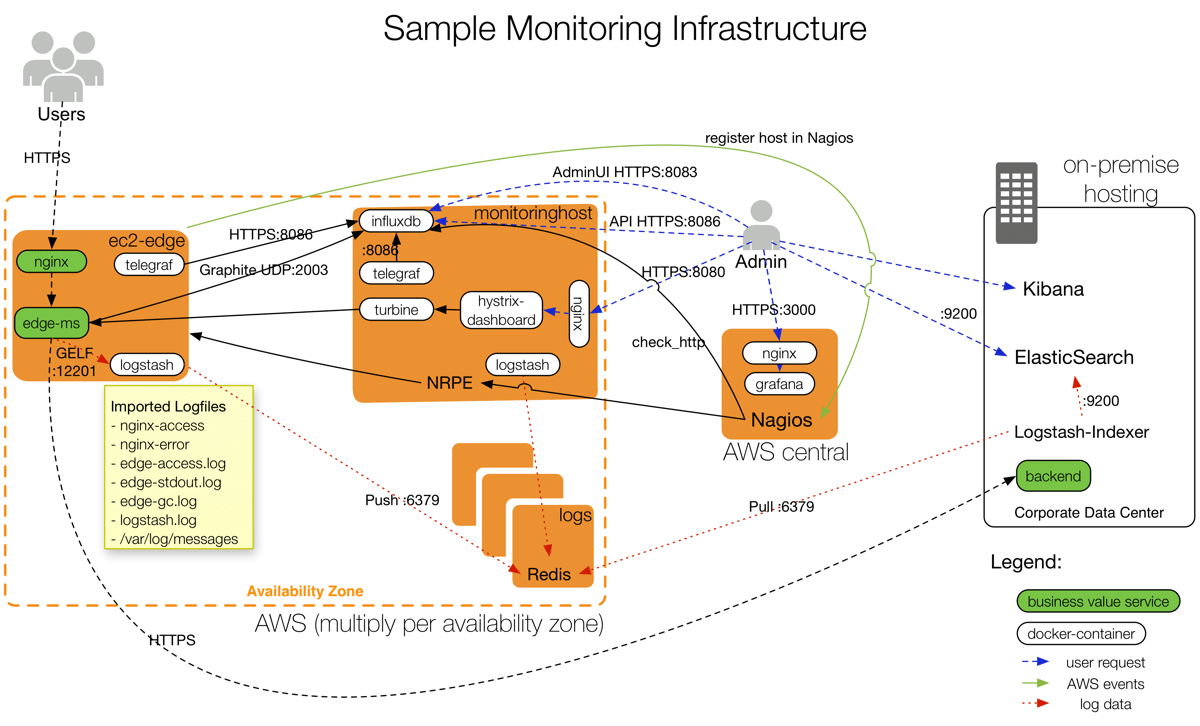
Setzt man sich schließlich das Ziel, die Deployments der Services vollständig zu automatisieren, muss man sich im Vorfeld genau überlegen, an welchen Kennzeichen man nicht erfolgreiche Deployments und deren Fehlerszenarien erkennt. Diese Fragen werden in vielen Fällen auch den Product Owner und die Business-Seite betreffen. Auf die herausgearbeiteten Kennzeichen muss dann das Monitoring angepasst werden. Die notwendige Monitoring-Infrastruktur um automatisierte Überwachung von Microservice-Deployments gewährleisten und den Teams ihre Autonomie bieten zu können, sollte nicht unterschätzt werden. Abb. 2 zeigt ein Beispiel für die unterschiedlichen Komponenten die für Logging, Metriken und Alarming neben den normalen, wertschöpfenden Services zusätzlich betrieben werden müssen.
Ein Gatekeeper-Service wie Fabio erlaubt es, den Produktions-Traffic schrittweise auf neue Services zu leiten. Er kann dabei helfen, das Risiko einer vollautomatisierten Deployment-Pipeline in die Produktionsumgebung weiter zu begrenzen, da neue Features erst von einer ausgewählten Menge an Benutzern getestet werden. Wie weit man damit gehen möchte, ist natürlich jedem selbst überlassen, allerdings ist es aus meiner Sicht beruhigend zu wissen, dass man alle Optionen hat und selbst abwägen kann, welche man wählt.