
Service-Meshes entwickeln sich zu einer Standard-Infrastrukturkomponente. Deshalb ist es nicht zu früh, ihr Potenzial abseits klassischer Microservices-Architekturen abzutasten.
Mancher Entwickler staunt über die Geschwindigkeit, in der Tools, Techniken und Frameworks im JavaScript- und Webumfeld erscheinen. Aber mittlerweile stehen die neuen Ideen und Techniken, die aus dem Bereich der Infrastruktur hervorsprudeln, dem Tempo in nichts nach. Ob man das aufregend oder anstrengend findet – es hilft nichts: Früher oder später muss man sich mit aktuellen Ideen wie Service-Meshes beschäftigen. Denn die vielen Verbesserungen durch Automatisierung, um die es letztlich geht, möchte sich niemand entgehen lassen.
Microservices - schön und gut, aber…
Eine Microservice-Architektur teilt eine Anwendung entlang fachlicher Grenzen in Module, die bis in den Betrieb erhalten bleiben. Netzwerkverbindungen integrieren die einzelnen Microservices erst zur Laufzeit. Damit sind sie nicht nur logisch, sondern ebenso technisch voneinander entkoppelt. Neben der freien Wahl der Methoden und einer einfacheren organisatorischen und technischen Skalierbarkeit ist die schnelle Auslieferung von Software das wichtigste Argument für Microservices.
Microservices haben aber auch viele Schwächen, die zum großen Teil mit den Tücken verteilter Systeme[1] einhergehen. Denn auf das Netzwerk ist kein Verlass, weshalb Microservices jederzeit mit Verzögerungen und Ausfällen rechnen müssen, wenn sie darüber kommunizieren. Durch verschachtelte Aufrufe ist die Latenz außerdem viel höher als Methodenaufrufe innerhalb von Monolithen. Sie sind durch die vielen Netzwerkschnittstellen potenziell angreifbarer, weshalb jeder Microservice die Vertrauenswürdigkeit seiner Kommunikationspartner immer überprüfen muss.
Der Betrieb von Microservices ist eine Herausforderung, die jedoch durch Container, Orchestrierern wie Kubernetes und die Cloud beherrschbar geworden ist. Ein Service-Mesh hat darüber hinaus das Potenzial, viele weitere Probleme von Microservices mit einem Streich zu bewältigen. Beispielsweise könnten Service-Meshes das Monitoring und die Widerstandsfähigkeit gegenüber Netzschwankungen oder Ausfälle anderer Services (Resilienz) ebenfalls in die Infrastruktur verlagern. Das entlastet die mit Bibliotheken und zusätzlichem Code überladenen Microservices. Zentrale Infrastrukturkomponenten wie API Gateways, die Aufrufhierarchien aufblähen und die dezentrale Architektur untergraben, könnten dadurch der Vergangenheit angehören.
Jedoch haben sich Microservices-Architekturen inzwischen weiterentwickelt. Anstatt die Nachteile synchroner Aufrufhierarchien zu akzeptieren, fällt die Wahl häufig auf eine asynchrone Kommunikation oder auf Self-contained Systems (SCS), die einige Schwächen von Microservices im Kern vermeiden.
Der Monolith steckt noch in der synchronen Kommunikation
Die Probleme von Microservices sind zum großen Teil mit den gegenseitigen Netzwerkaufrufen verbunden. Die einfachste Möglichkeit, eine monolithische Anwendung zu Microservices zu migrieren, ist die Anwendung aufzuspalten und Methodenaufrufe zwischen Modulen (bzw. Microservices) mit synchronen Netzwerkaufrufen zu ersetzen. Eine asynchrone Umsetzung der Kommunikation bietet allerdings Vorteile wie eine geringere Latenz und eine losere Kopplung der Microservices. Die Schwierigkeit ist, sich von der Frage-Antwort-Interaktion loszulösen.
In Abbildung 1 sind die synchrone Kommunikation sowie zwei Ansätze für die asynchrone Umsetzung der Kommunikation zwischen Microservices gegenübergestellt. Asynchrone Kommunikation kann man über eine Message Queue (MQ) oder mit HTTP implementieren. Kommt eine Message Queue zum Einsatz, kommunizieren die Microservices nicht direkt miteinander, sondern senden und empfangen Ereignisse über sie (Microservice B, C und D rechts in Abb. 1). Bei asynchroner Interaktion über HTTP entfällt ein Warten auf die Antwort nach einer Anfrage (Microservice A rechts in Abb. 1). Ist ein Ergebnis notwendig, kommt es an einem weiteren Endpunkt regelmäßig zur Abfrage (Polling).
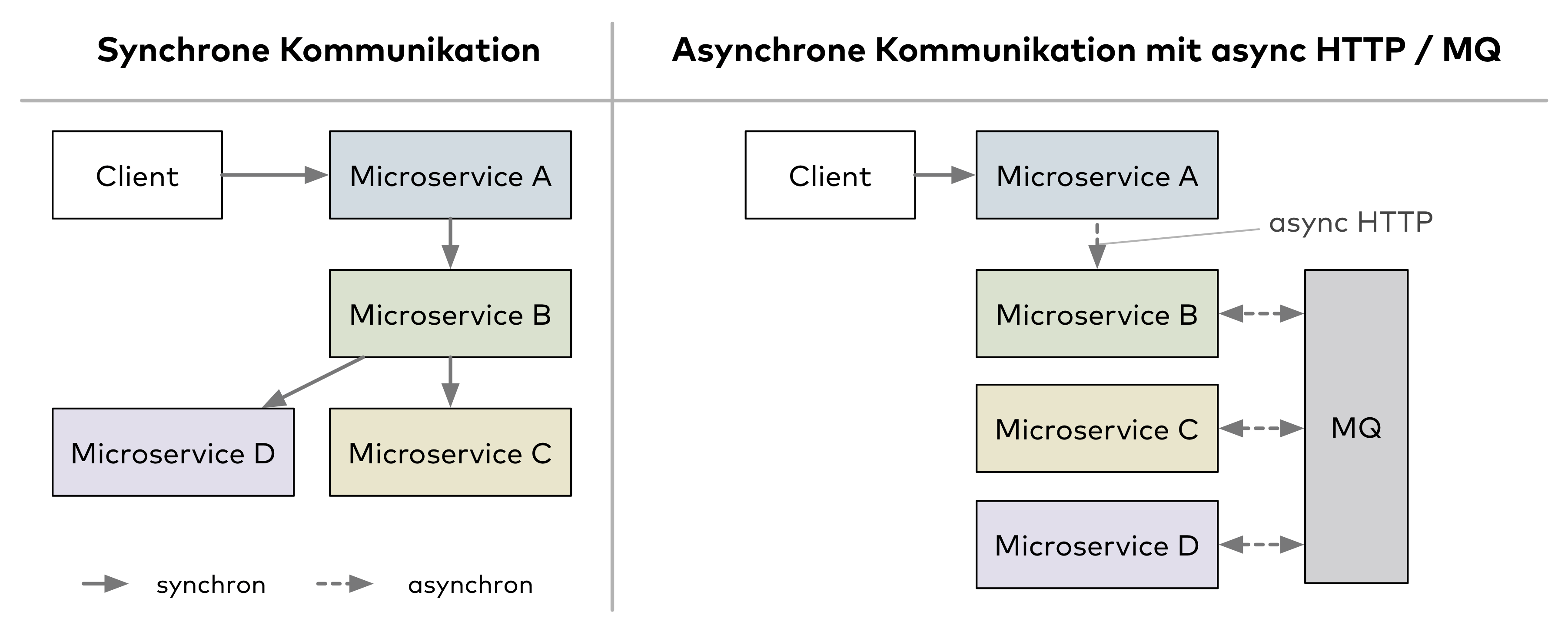
Anders als bei der synchronen Kommunikation müssen Microservices, die asynchron kommunizieren, meist keine besonderen Vorkehrungen für Ausfälle und Verzögerungen treffen, da sie nur mit der hoch verfügbaren Message Queue kommunizieren. Da der Empfänger einer Client-Anfrage, beispielsweise Microservice A, nicht auf die Antwort von anderen Microservices wie Microservice B, wartet, kann die asynchrone Kommunikation eine viel kürzere Antwortzeit erreichen. Bei einer synchronen Abarbeitung (Abb. 1 links) muss Microservice A auf Microservice B, C und D warten, bevor er die Client-Anfrage beantworten kann.
Ganzheitliche Module mit Self-contained Systems
Anders als ein Microservice besteht ein Self-contained System (SCS)[2] aus Webanwendungen (oder Web-Apps), die in sich geschlossen und möglichst unabhängig von anderen Anwendungen sind. Ein SCS kann Anwendungsfälle komplett bedienen und schließt dazu Daten und das zugehörige Frontend ein. Wenn Aufrufe zwischen SCS nötig sind (wie in Abb. 2 zwischen SCS A und SCS B) finden sie bevorzugt asynchron statt. Innerhalb jedes SCS können Entwickler über Modularisierung und Architektur frei entscheiden. Wie die Abbildung zeigt, kann ein SCS etwa aus einer Web-App bestehen oder in Microservices aufgeteilt sein.
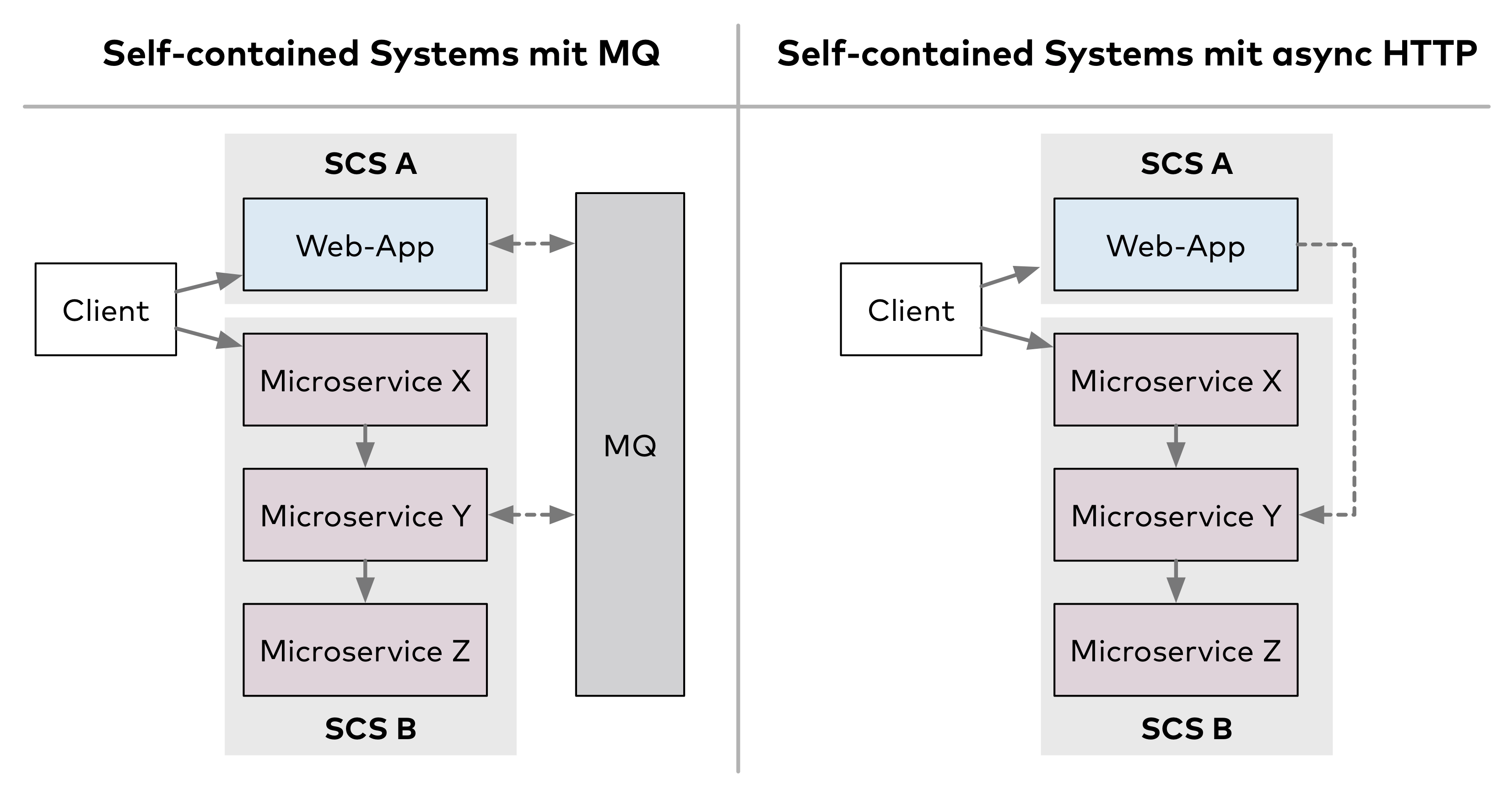
Gegenüber klassischen Microservices haben SCS zusätzlich den Vorteil, dass Entwickler Entscheidungen zu Technik und Mikroarchitektur für zusammenhängende Komponenten fällen können, ohne dass andere SCS davon betroffen sind.
Service Mesh - das Rundum-sorglos-Paket für Microservices
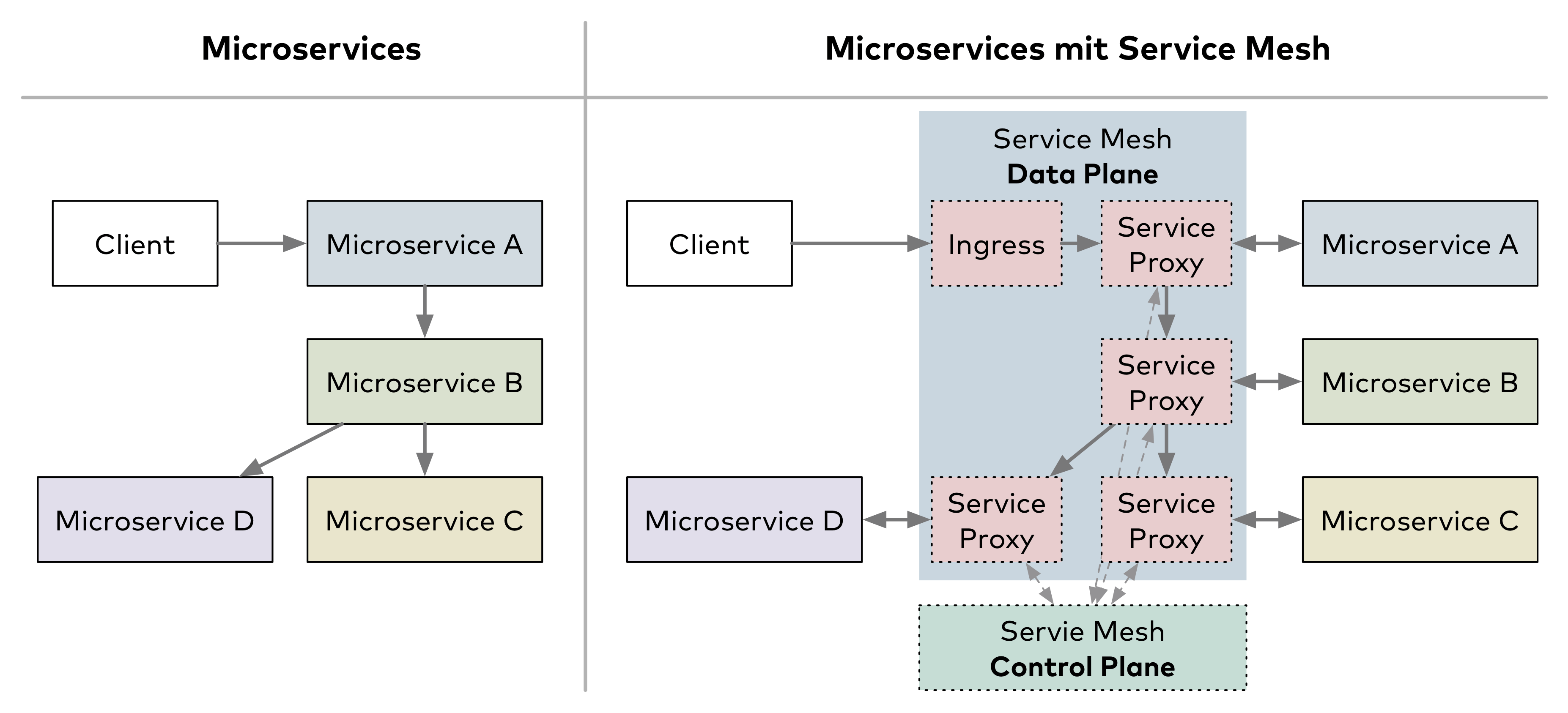
Ein Service-Mesh hebt viele Funktionen zu Observability, Routing, Resilienz und Sicherheit in die Infrastruktur. Es macht sich die verteilte Microservices-Architektur zunutze, statt sie mit zentralen Komponenten wie einem API Gateway unter Kontrolle zu bringen. Es stellt jeder Serviceinstanz einen Service-Proxy zur Seite, über den alle ein- und ausgehenden Netzwerkverbindungen der Instanz laufen. Der Service-Proxy wendet auf die Netzwerkanfragen Observability-, Routing-, Resilienz- und Sicherheitsfunktionen an (Abb. 3).
Mehr Details zum Service Mesh gibt es im Service Mesh Primer, im Blogbeitrag „Service Mesh und Kubernetes” und im Podcast zum Thema Service Mesh Teil 1 und Teil 2
Das Sidecar-Pattern gab es bereits vor Service-Meshes. Neu ist eine weitere Ebene, die sogenannte Control Plane. Sie kennt alle Service-Proxys und konfiguriert deren Verhalten. Die Service-Proxys führen ihre Funktion als Teil eines dezentralen Netzes aus, sind aber zentral konfigurierbar. Sie erfassen außerdem Daten zum Netzverkehr, der sie passiert, und senden ihn an die Control Plane. Die Daten ermöglichen ein flächendeckendes Basis-Monitoring. Mit einem Service-Mesh wird also einerseits ein konsistentes Verhalten der Services unabhängig von ihrer Implementierung ermöglicht und andererseits die Komplexität der einzelnen Microservices reduziert.
Service-Meshes haben einen regelrechten Hype ausgelöst, weil sie gleich eine ganze Reihe komplexer Probleme von Microservices-Architekturen lösen, ohne dass Entwickler bestehenden Code ändern müssen. Nun sind viele Entwicklungsteams damit beschäftigt zu evaluieren, wie ein Service-Mesh in ihre individuelle Umgebung passt. Bei einer klassischen Microservices-Architektur ist die Antwort (in aller Regel „Ja!”) schnell gefunden. Aber können asynchron kommunizierende Microservices oder Self-contained Systems von Service-Meshes profitieren?
Service Mesh - auch bei asynchroner Kommunikation?
Während die aktuellen Service Mesh Implementierungen asynchrones HTTP ohne weiteres unterstützen, wird an der Kompatibilität zu Message Queues, die häufig eigene Protokolle nutzen, aktuell noch gearbeitet.
Tiefe Einblicke in Echtzeit: Observability
Zwischen asynchron kommunizierenden Microservices gibt es keine verschachtelten Aufrufe, die man mit Tracing sichtbar machen müsste. Antwortzeiten und Fehlerraten sind aber trotzdem wertvolle Daten, die Einblick in den Zustand einer Anwendung und Anhaltspunkte für Fehler liefern können. Bei beiden Formen der asynchronen Kommunikation kann ein Service-Mesh zu einem flächendeckenden Basis-Monitoring führen. Die von den Service-Proxys aufgezeichneten Metadaten zu Netzwerkverbindungen wie Quelle und Ziel einer Anfrage, URL, http-Methode, Statuscode und Antwortzeit können Tools wie Prometheus auswerten oder zu einem Dashboard mit Graphen zum Live-Netzwerkverkehr aufbereiten.
Der Netzwerkverkehr zwischen den Microservices und einer Message Queue läuft ebenfalls über einen Service-Proxy – damit ist ein Überwachen möglich. Um Fehler bei der Kommunikation zu erkennen, muss das Service-Mesh allerdings das Protokoll der Message Queue unterstützen. Da ein Service-Mesh aber keinen Einblick in den Inhalt der Anfragen und in die Interna der Anwendung hat, ist zusätzliches fachliches Monitoring weiterhin nötig.
Netzwerkverkehr intelligent steuern: Routing
Ein Service-Mesh kann Routing-Regeln umsetzen, mit denen Entwickler neue Versionen, zum Beispiel durch Canary Releasing, gezielt ausrollen oder zwei Versionen miteinander vergleichen können (A/B-Tests). Wenn asynchrone Kommunikation über eine Message Queue stattfindet, kann ein Service-Mesh Canary Releasing allerdings nicht allein umsetzen, da Metadaten der HTTP-Anfragen nicht ohne weiteres im Event landen. Realisiert man asynchrone Kommunikation durch HTTP-Aufrufe, kannn man wie bei synchroner Kommunikation Routing-Regeln für Canary Releasing und A/B-Tests nutzen.
Immun gegen Ausfälle und Fehler: Resilienz
Resilient ist ein Microservice, wenn er widerstandsfähig gegenüber Fehlern anderer Services oder des Netzwerks ist. Die Umsetzung erfolgt mit den Circuit-Breaker, die fehlerhafte Komponenten zeitweise vom Netzwerkverkehr abschirmen. Kurzzeitige Netzwerkfehler beheben Retry- und Timeout-Mechanismen. Auf den ersten Blick erscheint asynchrone Kommunikation solchen Fehlern vorzubeugen, weil sie blockierende Aufrufe zwischen Microservices vermeidet.
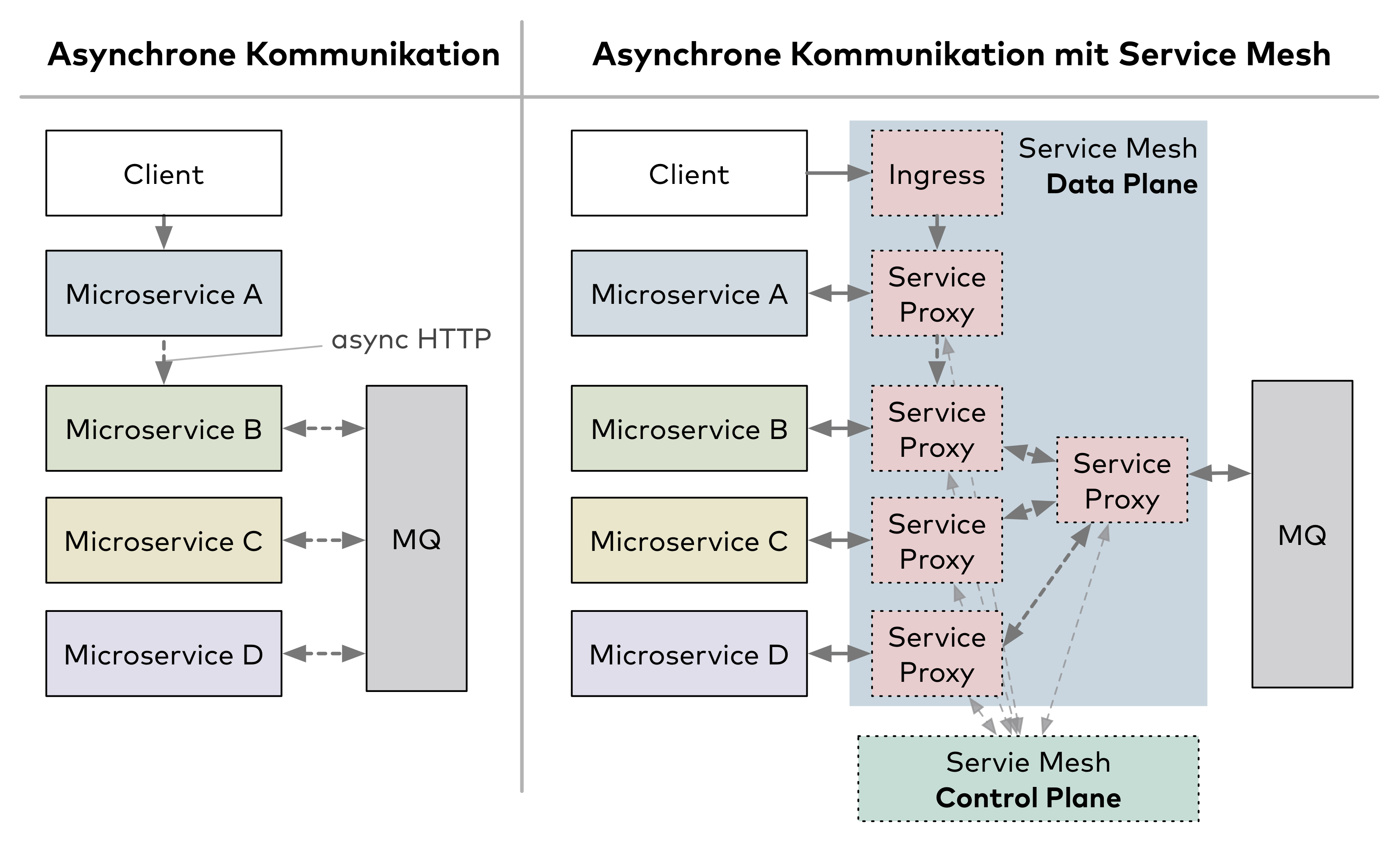
Wie Abbildung 4 allerdings zeigt, muss man den auf dem Server eingehenden Netzwerkverkehr über einen sogenannten Ingress an eine Microservice-Instanz routen (z. B. von Client zu Microservice A). Bei solchen Verbindungen können Resilienz-Maßnahmen durchaus sinnvoll sein.
Vertrauen automatisieren: Security
Angreifer können das gegenseitige Vertrauen von Services innerhalb eines Clusters nutzen, um einen Service zu imitieren und das System unbemerkt zu manipulieren, lahmzulegen oder auszuspionieren. Ein Service-Mesh kann ohne Codeänderungen dafür sorgen, dass alle Serviceinstanzen beidseitig TLS-authentifiziert und verschlüsselt kommunizieren (sogenanntes Mutual TLS/mTLS). Da er kein Zertifikat vorweisen kann, fehlt dem Angreifer damit der Einstiegspunkt ins System. Die für mTLS nötige Certificate Authority und die Mechanismen zum Verteilen der Schlüssel sind Teil eines Service-Mesh.
mTLS funktioniert sowohl für synchrone als auch für asynchrone HTTP-Kommunikation. Setzen Entwickler Message Queues ein, liegt die Vermutung nahe, dass die Services einander ohnehin nicht aufrufen und damit solche Sicherheitsmaßnahmen nicht benötigen. Allerdings können sich Angreifer, die Zugang zum Server haben, als Microservice-Instanz ausgeben und schadhafte Events in die Message Queue schreiben oder unautorisiert Events auslesen. Sofern die spezielle Message Queue unterstützt wird, profitiert die Anwendung vom automatischen mTLS.
Sind Self-contained Systems meshbar?
Die gerade beschriebenen Konsequenzen von asynchroner Kommunikation gelten ebenfalls für SCS, die klassischerweise untereinander asynchron kommunizieren. Da jedes SCS allerdings eine eigene Frontend-Komponente mitbringt, profitieren SCS von den komplexen Routing-Regeln eines Service-Mesh, die Canary Releasing und A/B-Tests ermöglichen. Eine Clientanfrage, die den Server erreicht, vermitteln die Service-Mesh-Proxys an ihr Ziel, sodass Routing-Regeln und Resilienz-Maßnahmen feingranularer als bei klassischen Microservices möglich sind (siehe Abb. 5).
Wenn alle SCS nur aus einer Web-App bestehen (wie SCS A), ist die Situation die gleiche wie bei asynchronen Microservices. Jede Instanz jedes SCS bekommt einen Service-Proxy, der Mesh kann sie folglich überwachen und steuern. Sobald ein SCS allerdings in mehrere Microservices aufgeteilt ist, sind zwei Ansätze denkbar:
- Ein Service Proxy pro SCS (Service Mesh zwischen SCS, Mitte in Abb.5)
- Ein Service Proxy pro Microservice (Service Mesh zwischen Microservices, rechts in Abb. 5)

Ein Service-Proxy pro SCS ist sinnvoll, wenn man alle Microservices eines SCS als Einheit betrachtet und nur zusammen (beispielsweise in einem Kubernetes Pod) deployt und skaliert. Zwischen SCS gilt in dem Fall alles, was für asynchron kommunizierende Microservices stimmt: Monitoring- und mTLS-Funktionen eines Service-Mesh können sinnvoll zum Einsatz kommen.
Bestehen SCS allerdings aus mehreren klassischen Microservices, die über das Netzwerk kommunizieren (z.B. SCS B), ist ein Service-Proxy pro Microservice-Instanz (Abb. 6 rechts) die bessere Wahl. Denn so können die Microservices von der gesamten Funktionspalette eines Service-Mesh, also Observability, Routing, Resilienz und Sicherheit, profitieren. Um SCS-übergreifende Aufrufe zu beschränken, können Entwickler mit einem Service-Mesh beispielsweise Autorisierungsregeln formulieren und umsetzen.
Es ist kompliziert: Service Mesh Technologien
Ein Service-Mesh kann in Microservice-Architekturen und SCS sinnvoll sein, um grundlegende, konsistente Transparenz, Sicherheit und eventuell Routing und Resilienz ohne Codeänderungen zu erreichen. Allerdings sind Service-Mesh-Implementierungen noch sehr unterschiedlich, was ihre Features, Reife und Benutzbarkeit angeht. Die beiden wichtigsten sind die Open-Source-Projekte Istio[3], das Google und IBM entwickelt haben sowie das CNCF-Projekt (Cloud Native Computing Foundation) Linkerd[4].
Istio beeindruckt durch die Vielzahl an Features und die Flexibilität der Konfiguration. Das ist auch der Nachteil: Die Konfigurationsoptionen von Istio zu durchschauen ist eine echte Herausforderung, auch wenn die Community mit jedem Release nachbessert. Immerhin ist die Dokumentation jedoch ausführlich. Sie versucht nicht zu verbergen, dass das Projekt in erster Linie auf Kubernetes zugeschnitten ist. Allerdings möchte sich Istio in kommenden Releases weiter für andere Umgebungen wie Nomad und Consul öffnen.
Linkerd unterstützt die asynchrone Kommunikation relevanter Kernfunktionen wie Basis-Monitoring und mTLS sowie die Anwendung von Routing-Regeln, Timeout und Retry. Features wie Tracing und Circuit Breaking, die man abhängig von der Architektur sinnvoll einsetzen kann, sind mit Linkerd noch nicht umsetzbar (siehe Abb. 6). Dafür ist die Konfigurations-API gut durchdacht und einfach zu nutzen. Viele Tests[5], [6], [7] bescheinigen Linkerd außerdem einen geringeren Ressourcenverbrauch und eine geringere Beeinträchtigung der Antwortzeit. Linkerd ist nur für Kubernetes verfügbar.
Abbildung 6 zeigt eine detaillierte Gegenüberstellung der Features von Istio 1.2 und Linkerd 2.4.

Beide Projekte sind offiziell reif für den Produktionsbetrieb. Wie bei allen Infrastrukturkomponenten ist es allerdings empfehlenswert, erste Erfahrungen in einem Testsystem zu sammeln. Da an beiden Projekten intensiv entwickelt wird, lohnt es sich, neue Releases und Blogbeiträge zu verfolgen.
Fazit
Eine asynchrone Kommunikation zwischen Microservices macht einige Funktionen von Service-Meshes wie Tracing obsolet. Von Features wie Routing und Resilienz können sie weniger profitieren als klassische Microservices. Doch allein das automatische, flächendeckende Monitoring und beidseitig authentifizierte Verbindungen können gute Gründe für ein Service-Mesh sein.
SCS profitieren sogar noch darüber hinaus von einem Service-Mesh, da Entwickler Clientanfragen an die Frontends der SCS feingranular steuern können. Routing-Regeln können Canary Releases steuern und Circuit Breaker vermeiden, dass Anfragen bei überlasteten oder fehlerhaften Endpunkten laden. Besonders wenn ein SCS in Microservices aufgeteilt ist, kann ein Service-Mesh wertvolle Kontroll- und Observierungsmöglichkeiten bieten.
Es gibt gute Argumente für ein Service-Mesh in asynchronen Microservices und in Self-contained Systems. Bleibt noch die Auswahl eines Service-Meshes. Die aktuell besten Kandidaten sind Istio, das den größten Funktionsumfang, aber auch die größte Komplexität hat, und Linkerd, das zwar weniger Features, aber dafür eine bessere Developer Experience bietet und leichtgewichtiger ist.