
Cloud-Umgebungen sind nicht mehr neu. Amazon ist bereits 2006 den Schritt in die Cloud. Ein häufiges Missverständnis bezüglich der Cloud ist, dass es um eine Kostenreduktion im Betrieb geht. Zumindest für die damalige Situation bei Amazon kann das kaum stimmen. Es gab damals keine schlüsselfertigen Cloud-Lösungen. Amazon musste also eine erhebliche Investition tätigen, um die notwendige Infrastruktur zu schaffen.
Cloud-native
Der wichtigste Vorteil der Cloud ist, dass sie eine Umgebung bietet, die Probleme wie Skalierung löst. Software, die in der Cloud deployt ist, kann praktisch beliebig skalieren. Damit ist dieses Problem gelöst. Entwickler können sich um andere Aufgaben kümmern, die das Geschäft direkt unterstützen.
Außerdem erlaubt die Cloud es den Teams, mehr Verantwortung zu übernehmen. Sie können ihre Umgebungen im Rahmen der Angebote der Cloud beliebig konfigurieren und mehr Einfluss in den Betrieb nehmen. So können Aufgaben, die klassisch beim Anwendungsbetrieb liegen, durch die Teams übernommen werden. Diese Teams kennen die Anwendungen oft besser. Außerdem können sie die Anwendungen so modifizieren, dass der Anwendungsbetrieb einfacher wird. So wachsen Entwicklung (Dev) und Betriebs (Ops) zu DevOps zusammen.
Warum eigentlich Continuous Delivery?
Und schließlich erleichtert die Cloud Infrastruktur-Automatisierung. Das vereinfacht Continuous Delivery[1], also das regelmäßige Ausliefern der Software. Continuous Delivery hat offensichtliche Vorteile: Änderungen gehen schneller in Produktion. Daher kann man Features schneller ausrollen. Besseres Time-to-Market kann einen Wettbewerbsvorteil darstellen. Es ist eigentlich auch offensichtlich, dass regelmäßige Deployments weniger häufig fehlschlagen und damit das Risiko geringer ist. Schließlich werden weniger Änderungen pro Deployment ausgeliefert und wenn man etwas häufiger macht, ist man geübter darin.
Mittlerweile gibt es jedoch eine Studie[2], die belegt, dass auch die Zeit zum Beheben eines Ausfalls bei Systemen mit Continuous Delivery kürzer ist. Da Deployments weniger häufig fehlschlagen und Ausfälle schneller behoben werden können, müsste man Systeme, die sehr verfügbar sein sollen, eigentlich regelmäßig ausliefern.
Außerdem zeigt die Studie, dass Projekte, die oft deployen, 50% der Entwickler-Zeit auf neue Features verwenden, während andere Projekte nur 30% aufwenden können. Das verbessert also die Produktivität der Teams gemessen an neuen Features. Gleichzeitig geht der Anteil der Arbeit, der sich mit Sicherheitsproblemen, von Endbenutzern gemeldeten Fehlern und Kundensupport beschäftigt, zurück. Das weist darauf hin, dass die Qualität der Software aus Benutzerperspektive ebenfalls besser wird. Continuous Delivery hat also so viele Vorteile in verschiedenen Bereichen, dass dieses Vorgehen auf jeden Fall sinnvoll erscheint.
Die Studie zeigt auch, ab welcher Deployment-Frequenz man mit diesen positiven Effekten rechnen kann. Sie treten ein, wenn man mehrmals pro Tag deployt. Eine solche Deployment-Frequenz ist ohne eine dynamische Infrastruktur, wie sie die Cloud bietet, kaum denkbar.
Aber viele Anwendungen werden nur einmal im Quartal ausgeliefert und müssen wochenlang getestet werden. Solche Anwendungen mehrmals pro Tag zu deployen würde bedeuten, dass man irgendwo mehrere Größenordnungen in der Geschwindigkeit zulegen muss. Man kann wohl nur so häufig deployen, wenn man die Software in kleine, unabhängig deploybare Artefakte aufgeteilt hat. Genau das sind Microservices [3][4]: Kleine, unabhängig deploybare Module einer großen Anwendung.
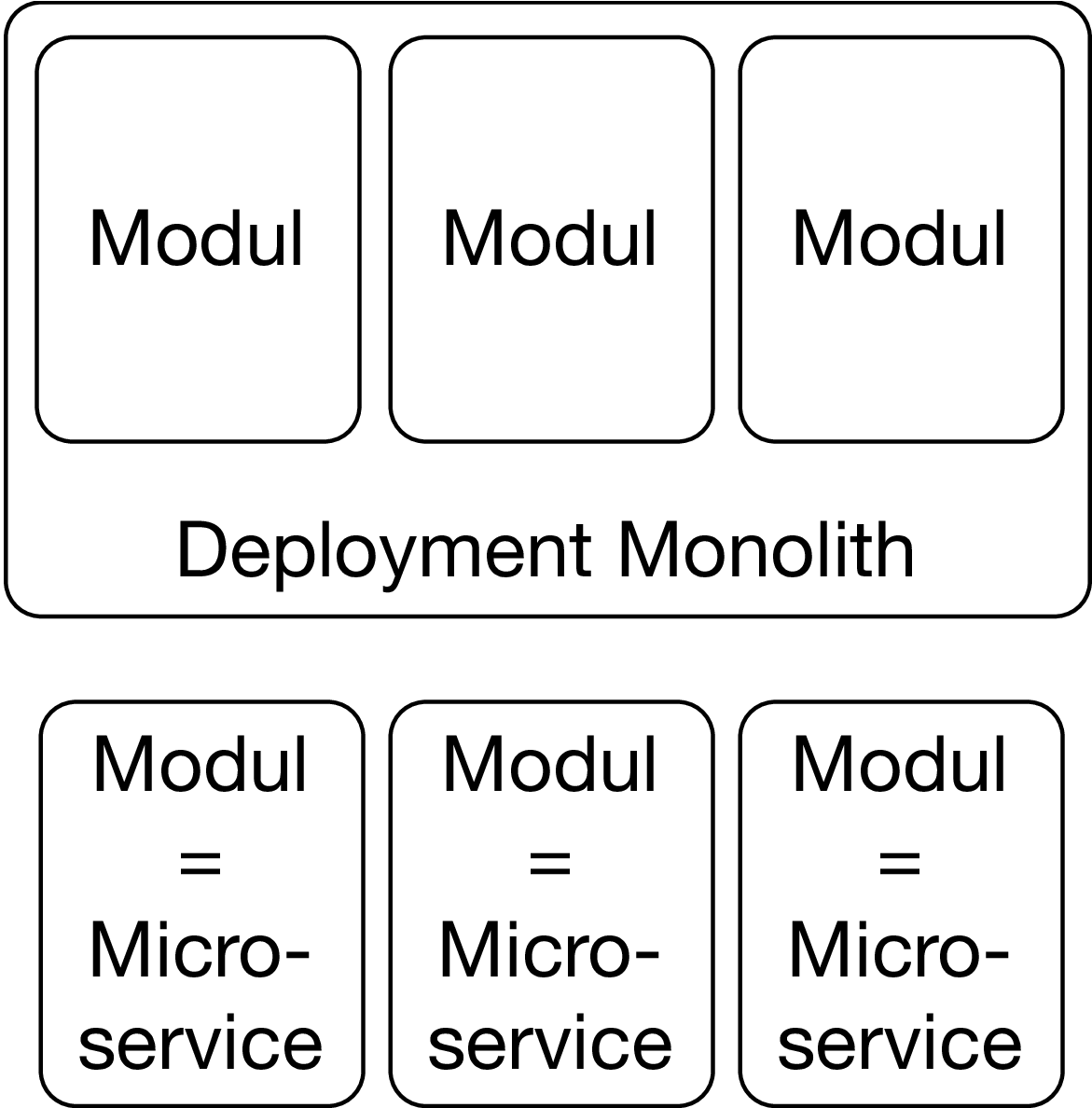
Microservices sind Cloud-native
Microservices helfen in der Cloud aber auch aus anderen Gründen. Cloud-Infrastrukturen sind nicht besonders zuverlässig. Maschinen können ausfallen oder neu starten. Sogar ganze Rechenzentren können ausfallen, ohne dass die Service Level Agreements der Cloud verletzt werden. Ebenso kann die Kommunikation über das Netzwerk ausfallen. Es scheint kaum machbar, auf solchen Umgebungen Software ohne Ausfälle zu betreiben. Aber einige der Systeme mit der höchsten Verfügbarkeit basieren genau auf solchen Infrastrukturen.
Auf der anderen Seite bieten Clouds nämlich an, dass man Anwendungen verteilt in mehreren Rechenzentren laufen lassen kann. Und wegen der Infrastruktur-Automatisierung können Anwendungen auch in anderen Rechenzentren automatisch gestartet werden oder es können zusätzliche Instanzen gestartet werden, wenn die Last das notwendig macht. Die Architektur muss aber zeitweise Ausfälle kompensieren können und Teile der Anwendung in neuen Rechenzentren neu starten können. Microservices teilen Anwendungen in getrennte Prozesse auf, die unabhängig voneinander laufen. Der Ausfall eines Servers wird daher wahrscheinlich nur einige Microservices ausfallen lassen. Außerdem können Microservices wegen der Größe schneller neu gestartet werden als große monolithische Anwendungen.
Zusätzlich können Microservices feingranularer skalieren: Jeder Microservice kann in mehreren Instanzen auf verschiedenen Rechner gestartet werden und so mit einer höheren Last umgehen. Das kann ein so wichtiger Vorteil sein, dass er allein schon den Einsatz von Microservices rechtfertigt.
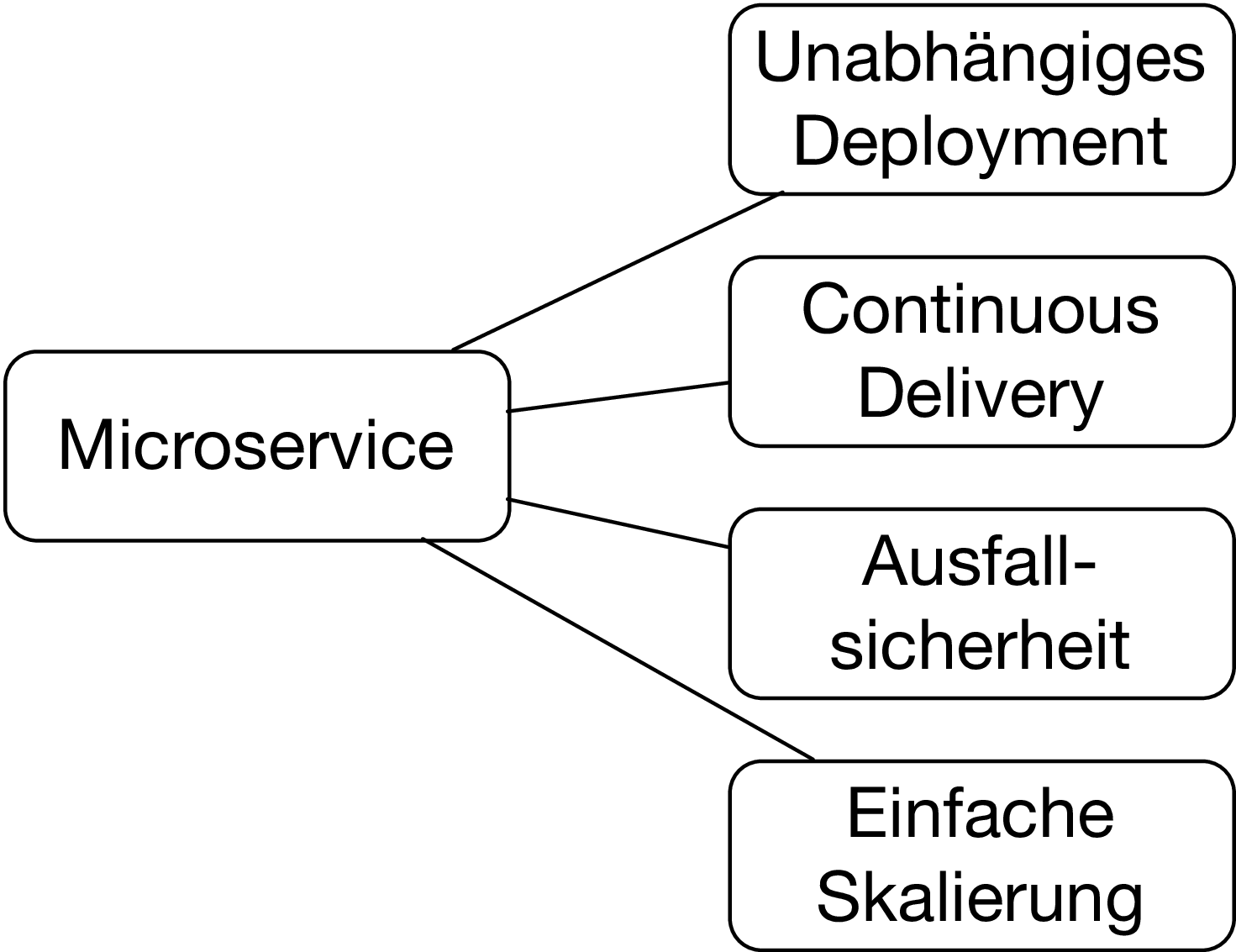
Also sind Microservices Cloud-native: Sie verstärken die Vorteile einer Cloud-Umgebung wie das regelmäßige Deployment oder die bessere Skalierung. Auf der anderen Seite können sie Schwächen wie die Unzuverlässigkeit der Infrastruktur kompensieren. Gerade das regelmäßige Deployment verspricht viele Vorteile und zwar nicht nur beim Time-to-Market sondern auch bei der Produktivität und der Zuverlässigkeit.
Neue Module braucht das Land
Microservices sind aber nicht nur wegen der Cloud interessant. Microservices stellen eine neue Art von Modulen dar. Damit stehen Microservices in einer Konkurrenz zu anderen Modularisierungsansätzen - sei es mit Programmiersprachenfeatures oder beispielsweise Bibliotheken. Eine Entscheidung für Microservices ist eine Entscheidung für eine Art der Modularisierung innerhalb eines Projekts und kann für jedes Projekt anders entschieden werden.
Modularisierung ist der Schlüssel zur Entwicklung komplexer Systeme. Nur mit Modulen ist es möglich, große Systeme so aufzuteilen, dass ein Mensch zumindest noch einen Teil des Systems verstehen kann. Schlüssel ist die Entkopplung: Änderungen sollen nur ein Modul betreffen, sonst muss man am Ende doch wieder das gesamte System verstehen. Klassisch wird Entkopplung bezogen auf die Änderung der Software betrachtet. Da Microservices klare Schnittstellen haben, unterteilen sie das System besser. Es kann ohne weiteres passieren, dass man ebi klassischer Modularisierung aus Versehen eine Klasse in einem anderen Modul nutzt und so eine Abhängigkeit erzeugt, die eigentlich nicht erwünscht ist. Microservices haben klare Schnittstellen z.B. als REST-Schnittstellen und können so den Zugriff auf die eigene Logik kontrollieren. Klassen aus anderen Microservices hat man gar nicht direkt im Zugriff.
Microservices bieten aber auch in anderen Bereichen eine Entkopplung: Sie können wie schon erwähnt getrennt skaliert und deployt werden. Dem Deployment kommt dabei eine besonders wichtige Rolle zu: Durch das getrennte Deployment können Änderungen nicht nur begrenzt in einem Modul programmiert werden, sondern auch in Produktion gebracht werden und vom Benutzer verwendet werden. Erst eine ausgelieferte Änderung ist wertvoll. Eigentlich ist also eine Entkopplung, die bis zum Deployment reicht, erst eine wirkliche Entkopplung.
Zudem können pro Microservice andere Technologien genutzt werden. In der Praxis wird man zwar vermutlich bei einem im Wesentlichen einheitlichen Technologie-Stack landen. Aber das Update auf eine neue Bibliothek oder eine neue Version einer Programmiersprache kann jeder Microservice getrennt vornehmen. Das reduziert das Risiko und erlaubt es auch, die Technologie-Updates auf die Microservices zu konzentrieren, die einen besonders großen Vorteil aus den neuen Technologien ziehen können. Weil jeder Microservice nicht nur unabhängig entwickelt werden kann, sondern auch unabhängig in Produktion gebracht werden kann und unabhängige technische Entscheidungen getroffen werden können, sind Microservices gerade in der wichtigsten Disziplin der Module - nämlich Unabhängigkeit - anderen Konzepten deutlich überlegen. Das erlaubt es, in großen Organisationen Entwicklung anders zu skalieren: Weil Microservices so unabhängig sind, können Teams viel eigenständiger entwickeln. Das reduziert den Kommunikationsbedarf zwischen den Teams und erlaubt so eine Skalierung der Entwicklung nicht auf Basis von organisatorischen Maßnahmen, sondern auf der Basis von architektonischen Maßnahmen, die mehr Kommunikation und eine engere Abstimmung überflüssig machen. Wenn Teams unabhängig Fachlichkeit entwickeln und deployen können und technisch ebenfalls weitgehend unabhängig sind, dann bleibt wenig Koordination übrig. Die Skalierung der Organisation ist aber nicht immer der Grund für den Einsatz von Microservices. Einfacheres Continuous Delivery, bessere Aufteilung in Module, bessere Skalierung und mehr Zuverlässigkeit können unabhängig von der Team-Größe ausreichende Gründe sein.
Fachlichkeit mit Domain-driven Design
Die stärkere Entkopplung nützt aber wenig, wenn eine fachliche Anforderung dann doch Änderungen an mehreren Microservices verursacht. Idealerweise sollte jede fachliche Änderung nur zu Änderungen an einem Microservice führen. Um zu einer solchen Aufteilung zu gelangen, bietet sich Domain-driven Design (DDD) an [5][6]. DDD bietet eine umfassende Methodik, um System fachlich zu entwerfen. Der Teil, der bei Microservices eine besondere Rolle spielt, ist das Strategic Design. Eine wesentliche Idee ist es, ein System in Bounded Context aufzuteilen. Das sind Teile des Systems, die jeweils ein eigenständiges Domänenmodell haben.
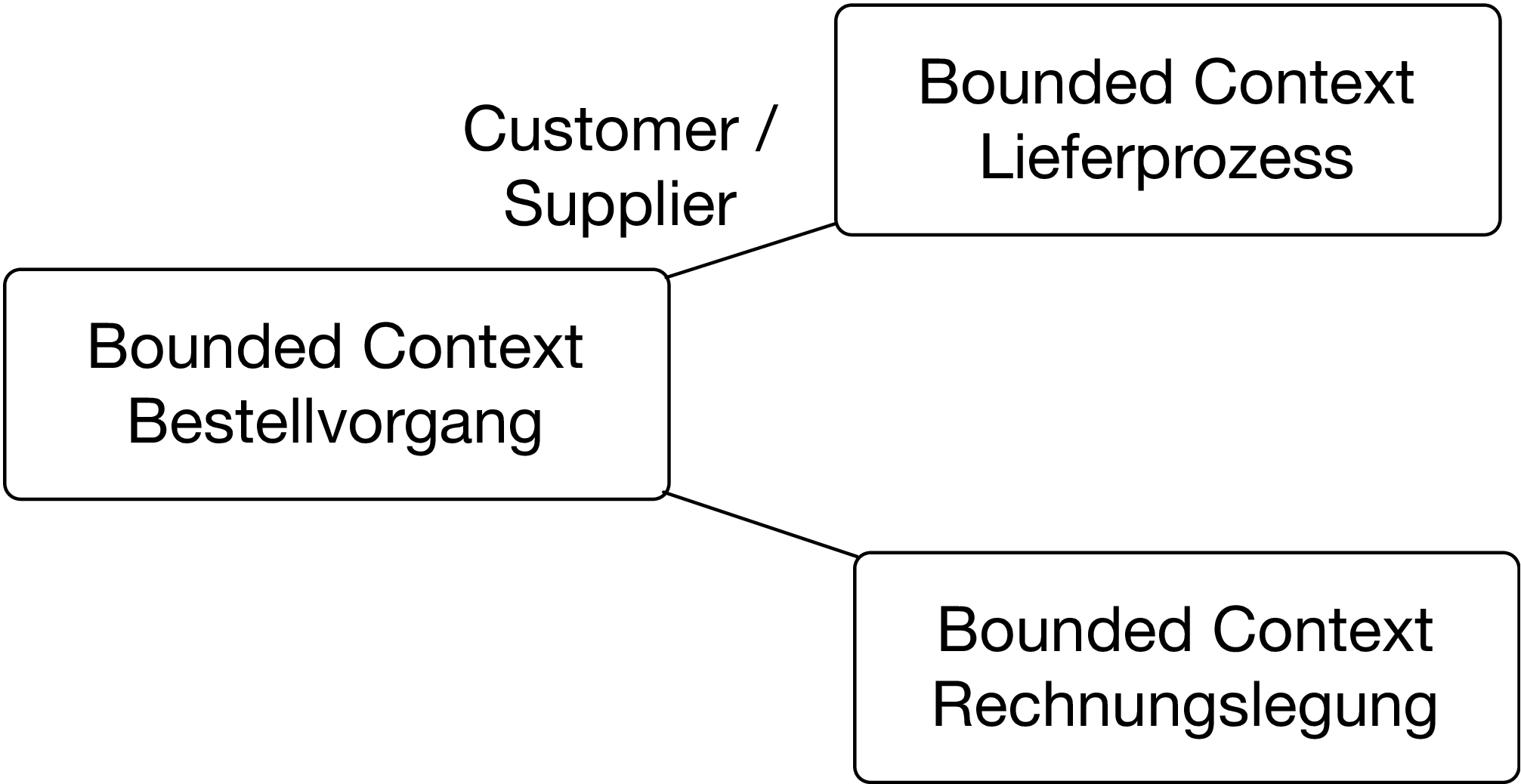
Beispielsweise könnte es die Bounded Contexts Bestellvorgang, Lieferprozess und Rechnungslegung geben. Jeder dieser Bounded Contexts hat ein Domänenmodell: Der Lieferprozess kann entscheiden, wie und mit welchen Kosten die Waren zum Kunden transportiert werden. Die Rechnungslegung kennt Steuern und Preise. Jeder Bounded Context kennt bestimmte Eigenschaften grundlegender Domänenobjekte: So kennt der Lieferprozess die Lieferadressen und die bevorzugten Lieferservices eines Kunden. Die Rechnungslegung hingegen kennt die Zahlungsmöglichkeiten, die ein Kunde nutzen möchte. So kennt zwar jeder Bounded Context dieselben Domänenobjekte wie Kunde oder Ware, aber in Wirklichkeit sind es unterschiedliche Aspekte dieser Domänenobjekte, so dass nur wenige Redundanzen entstehen. Wenn sich die Regeln für die Rechnungslegung ändern oder ein Lieferdienst seine Schnittstelle ändert, muss nur jeweils ein Bounded Context angepasst werden. Das vereinfacht die Änderung und spricht für eine gute Modularisierung. Wenn der Bounded Context als Microservice implementiert ist, kann er unabhängig deployt werden und technologische Entscheidungen können isoliert getroffen werden. Das Ergebnis ist eine weitgehende Unabhängigkeit in den Dimensionen Deployment, Technologie und Fachlichkeit.
Bounded Contexts sind allerdings Module eines Gesamtsystems. Es ist daher unmöglich, dass Anforderungen immer nur ein Bounded Context betreffen. Anforderungen können mehrere Bounded Context umfassen. Nehmen wir beispielsweise an, dass es einen neuen Lieferdienst gibt, der im Bestellprozess ausgewählt werden soll und dann im Lieferprozess beachtet werden muss. In diesem Fall müssen also zwei Bounded Contexts geändert werden. Dazu liefert Strategic Design auch Patterns. Beim Cluster/Supplier Pattern kann der Customer (Kunde) dem Supplier (Lieferant) darum bitten, Features zu implementieren. Es wäre logisch, wenn das Feature für einen neuen Lieferdienst im Lieferprozess umgesetzt wird. Wenn das Lieferprozess-Team eine Customer/Supplier-Beziehung zum Bestellprozess-Team hat, dann kann das Lieferprozess-Team vom Bestellprozess Änderungen verlangen, um den neuen Lieferdienst auswählen zu können. So ist die fachliche Gesamtzuständigkeit beim Lieferprozess, wenngleich das Bestellprozess-Team helfen muss. Es ist keine zentrale Koordination notwendig: Wenn die Customer/Supplier-Beziehung etabliert ist, können die Teams auf Basis dieser Beziehung miteinander interagieren. Eine zentrale Kontrolle ist nicht notwendig.
DDD unterstützt also nicht nur die fachliche Unabhängigkeit, sondern auch die Umsetzung der organisatorischen Unabhängigkeit.
Infrastrukturen: Kubernetes
Bei all diesen Vorteilen bieten Microservice natürlich auch Herausforderungen. Wenn ein System in eine Vielzahl von Microservices aufgeteilt wird, gibt es viel mehr Systeme, die betrieben werden müssen. Das stellt den Betrieb vor neue Herausforderungen, da der Aufwand für den Betrieb meistens von der Anzahl Systeme abhängt. Für die Implementierung und den Betrieb von Microservices gibt es zahlreiche Technologien. [5][7]
Virtualisierung hat sich mittlerweile durchgesetzt: Für einen neuen Server erstellt der Betrieb eine neue virtuelle Maschine, statt tatsächlich Hardware zu kaufen. Man könnte jeden Microservice in einer virtuellen Maschine betreiben. Ein wesentlicher Vorteil: Jeder Microservice hat sein eigenes Betriebssystem. So kann er alle notwendigen Bibliotheken und anderen Infrastruktur-Bestandteile im Dateisystem mitbringen. Außerdem kann der Microservice einen beliebigen Netzwerk-Port nutzen. Wären alle Microservice auf einer virtuellen Maschine beheimatet, müsste diese virtuelle Maschine so konfiguriert sein, dass sie alle Infrastruktur-Komponenten für alle Microservices dienen kann. Das kann schwierig zu erreichen und unübersichtlich sein. Außerdem müssten die Portvergabe der Microservices koordiniert werden, so dass kein Port an zwei Microservice vergeben wird.
Virtuelle Maschinen sind jedoch schwergewichtig. Sie benötigen viel RAM und viel Speicher für virtuelle Festplatten. Auch die CPU ist mit der Emulation der virtuellen Maschine beschäftigt.
Docker [8] bietet auch getrennte Dateisystem und getrennte Netzwerk-Schnittstellen. Aber es ist viel näher an einem Prozess als an einer virtuellen Maschine: Jeder Prozess bekommt nur eine eigene virtuelle Netzwerkschnittstelle und ein eigenes Dateisystem. Dabei ist das Dateisystem optimiert, so dass mehrere Docker Container sich gemeinsame Teile des Dateisystems teilen können.
Docker Container sind praktisch genauso effizient wie Prozesse, aber bieten eine ausreichende Isolation für Microservices. Auf einem Laptop können ohne Probleme Hunderte von Docker Container laufen – schließlich können auf einem Laptop auch Hunderte von Prozesse laufen.
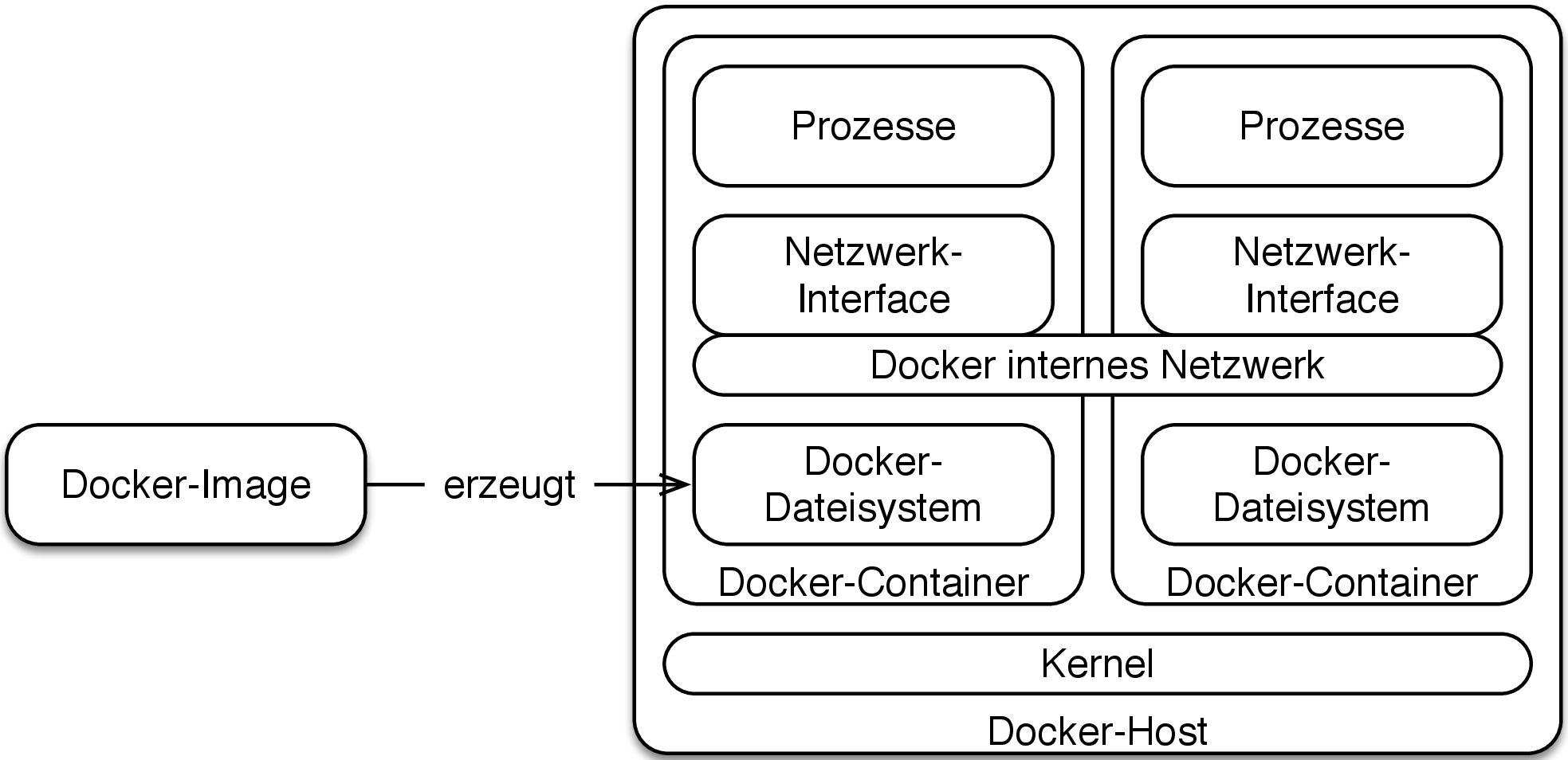
Aber für den Einsatz in einem anspruchsvollen Kontext ist es notwendig, dass die Docker Container in einem Cluster laufen, um so Ausfallsicherheit und Lastverteilung auf mehrere Server zu erreichen. Genau das löst Kubernetes [9].
Aber Kubernetes kann mehr:
- Microservices können andere Microservices suchen (Service Discovery). Kubernetes löst das mit DNS (Domain Name System), also dem System mit dem auch im Internet Namen wie ewolff.com zu IP-Adressen aufgelöst werden. Service Discovery ermöglicht eine weitere Entkopplung, da Microservices nur die Namen anderer Microservices kennen.
- Kubernetes kann die Last zwischen mehreren Microservices-Instanzen verteilen. Dazu nutzt Kubernetes eine IP-Adresse, hinter der sich mehrere Microservice-Instanzen verbergen. Bei einem Request wird dann eine dieser Instanzen angesprochen. Nur mit Last-Verteilung ist die unabhängige Skalierung der Microservices möglich.
- Schließlich kann Kubernetes Requests, die von außen kommen, an einen der Microservices weiterleiten. Dazu dienen Ingress, die umfangreich konfiguriert werden können. So erscheint das System, das intern aus Microservices besteht, nach außen wie ein einziges System.
Auf der Basis von Kubernetes bietet ein Service Mesh wie Istio [10] weitere Features. Es leitet den Netzwerkverkehr zwischen den Microservice durch Proxies. Dadurch kann es einige Features implementieren:
- Grundlegende Metriken wie die Anzahl oder Dauer von Aufrufen aber auch die Anzahl der Fehler bei den Aufrufen kann gemessen werden. Istio bringt mit Grafana und Prometheus zwei Werkzeuge mit, die solche Metriken auswerten können.
- Wenn Microservices sich gegenseitig aufrufen, können dabei komplexe Aufruf-Graphen entstehen. Istio kann diese Graphen aufzeichnen und mit Jaeger auch visualisieren. Außerdem bietet Istio mit Kiali ein Werkzeug, um die Abhängigkeiten zwischen Microservices zu visualisieren.
- Aufrufe können als Log-Einträge gespeichert werden.
- Schließlich können komplexere Algorithmen für das Routing von Requests zwischen den Microservices umgesetzt werden. Dazu zählen beispielsweise A/B Tests, bei denen unterschiedlichen Kundengruppen unterschiedliche Versionen der Software angeboten werden, um zu entscheiden, welche attraktiver ist.
- Die Kommunikation zwischen den Microservices kann verschlüsselt werden. Außerdem können die Microservices sich gegenseitig authentifizieren. Das verbessert die Sicherheit.
- Durch Retries, Timeouts und Circuit Breaker kann die Zuverlässigkeit des Microservice-Systems verbessert werden.
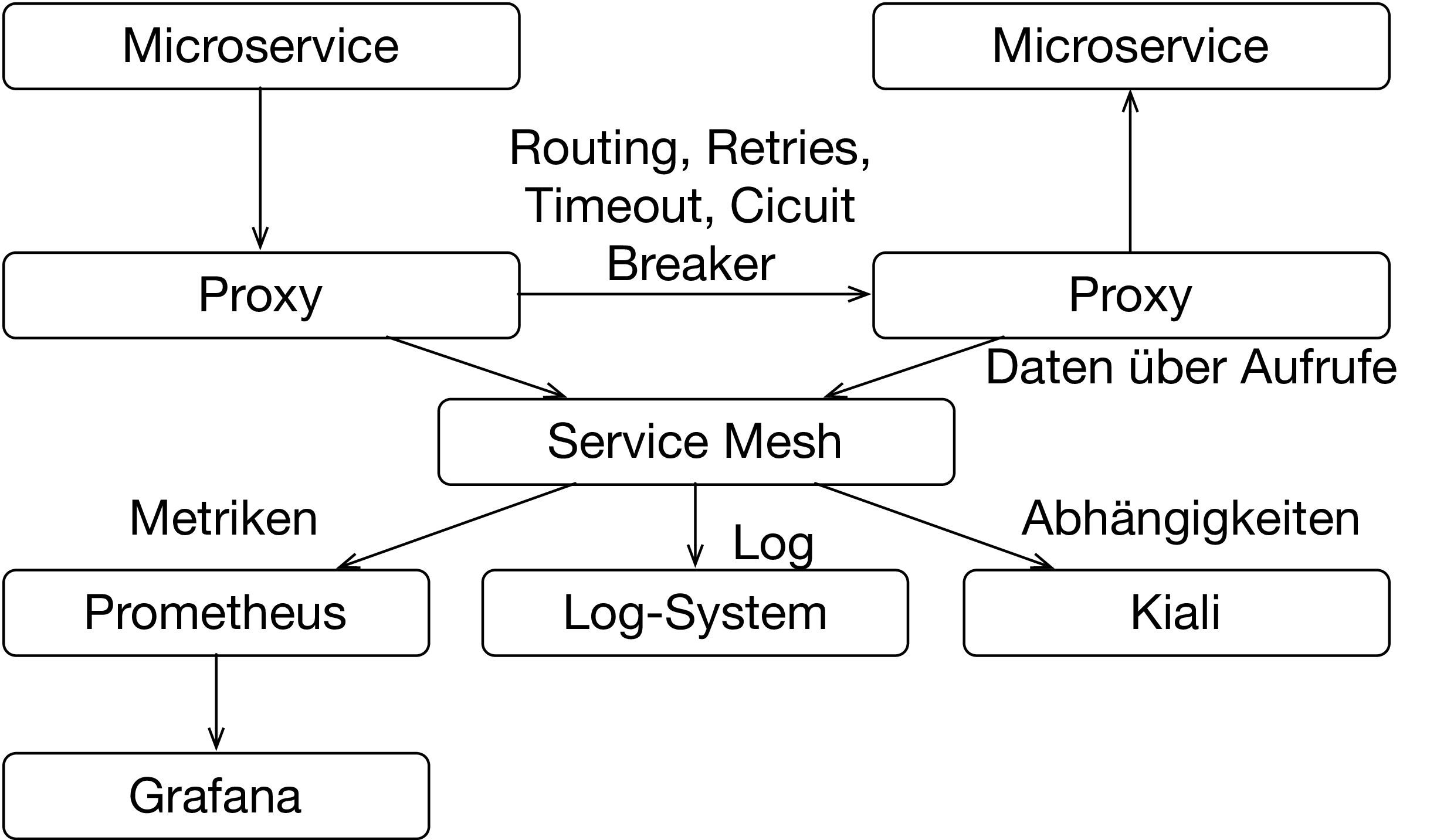
Istio und Kubernetes lösen also zahlreiche Probleme, die Microservice mit sich bringen. Dabei ist die Nutzung dieser Infrastruktur für die Microservices transparent. Das macht nicht nur die Nutzung einfacher, sondern es bedeutet auch, dass die Microservices in beliebigen Sprachen mit beliebigen Frameworks implementiert sein können. Also wird die Technologie-Freiheit nicht eingeschränkt.
Kubernetes und Istio sind interessant, weil sie zeigen, dass der Aufwand für die Implementierung und den Betrieb durch moderne Lösungen wesentlich geringer ist als dies noch vor nicht allzu langer Zeit der Fall war. Außerdem ist Kubernetes aus einem anderen Grund interessant: Alle großen Cloud-Anbieter wie Microsoft, Amazon und Google bieten schlüsselfertige Kubernetes-Cluster an. Damit gibt es eine gemeinsame Basis-Technologie, auf die sich alle Cloud-Anbieter geeinigt haben. Allerdings ist der Hauptvorteil der Cloud-Lösungen gar nicht unbedingt die Infrastruktur. Clouds bieten zum Beispiel Datenbanken an, die mit einem Mausklick zur Verfügung stehen. Auch Features wie Backup oder Skalierung sind nur wenige Mausklicks entfernt. Es ist nicht ungewöhnlich, dass die Bereitstellung einer Datenbank in einer klassischen IT-Organisation Wochen oder Monate dauert und Backups auf Knopfdruck sind dann oft undenkbar.
Mit Kubernetes gibt es eine Infrastruktur, auf der solche Angebote aufgebaut werden können. Schließlich geht es am Ende „nur“ um die Provisionierung von Software und Storage. Genau das bietet Kubernetes an. Der Vorteil: Wenn die Lösung auf Kubernetes aufsetzt, kann sie im eigenen Rechenzentrum aber auch in einer beliebigen Cloud genutzt werden. Solche Lösungen entstehen gerade, so dass Kubernetes sich anschickt, nicht nur die Microservices-Welt sondern auch die Cloud-Welt zu revolutionieren.
Links & Referenzen
-
Eberhard Wolff: Continuous Delivery: Der pragmatische Einstieg, 2. Auflage, dpunkt, 2016, ISBN 978–3864903717 ↩︎
-
DORA DevOps-Studie https://dora.dev/research/2018/dora-report/2018-dora-accelerate-state-of-devops-report.pdf ↩︎
-
Eberhard Wolff: Microservices: Grundlagen flexibler Softwarearchitekturen, 2. Auflage, dpunkt, 2018, ISBN 978–3864905551 ↩︎
-
Eberhard Wolff: Microservices - Ein Überblick, kostenlos unter https://microservices-buch.de/ueberblick.html ↩︎
-
Eberhard Wolff: Das Microservices-Praxisbuch: Grundlagen, Konzepte und Rezepte, dpunkt, 2018, ISBN 978–3864905261 ↩︎
-
Eric Evans: Domain-driven Design Referenz, kostenlos unter http://ddd-referenz.de/ ↩︎
-
Eberhard Wolff: Microservices Rezepte - Technologien im Überblick, kostenlos unter https://microservices-praxisbuch.de/rezepte.html ↩︎