
Zunächst einige Worte über Microservices [1]: Dieser Artikel versteht unter Microservices unabhängig deploybare Module. Das können Docker Container sein. Eine neue Version eines Microservices bedeutet dann, dass ein Docker Container gestoppt, durch eine neue Version ersetzt und wieder gestartet wird. Das beeinflusst andere Docker Container und damit andere Microservices nicht.
Microservices sollten von einem Team weiterentwickelt werden. Ein Team kann durchaus an mehreren Microservices arbeiten. Aber ein Microservice, an dem mehrere Teams arbeiten, ist kaum sinnvoll. Schließlich ist das System ja gerade in Module aufgeteilt, damit eine unabhängige Arbeit an einzelnen Modulen möglich ist. Wenn Teams immer an getrennten Microservices arbeiten, müssen sie sich viel weniger abstimmen.
Microservices haben viele Vorteile. Entwickler können ein Feature implementieren und es in Produktion bringen – ohne dass dazu eine Koordination mit anderen Microservices zwingend notwendig wäre. Schließlich können Microservices ja unabhängig in Produktion gebracht werden. Außerdem kann jeder Microservice unabhängig skaliert werden und einen anderen Technologie-Stack nutzen. Außerdem sind Microservices isoliert: Der Absturz eines Microservices bleibt auf den Microservice begrenzt und ebenso können Microservices bezüglich Sicherheit beispielsweise durch Firewalls isoliert werden.
Am Ende ermöglichen Microservices ähnlich wie andere Arten von Modulen auch Entkopplung – aber nicht nur auf Ebene der Architektur, sondern auch bei der Technologie, beim Deployment, bei der Sicherheit oder bei der Robustheit. Dieser hohe Grad an Entkopplung rechtfertigt auch die hohe technologische Komplexität, die Microservices mit sich bringen.
Zentrale Datenbank
Die Speicherung von Daten ist kein Thema, das nur Microservices betrifft. Wie gehen Systeme typischerweise mit Datenbanken um? Viele komplexe Software-Systeme nutzen zentrale Datenbanken. Es ist nicht ungewöhnlich, dass sich mehrere Module oder gar Systeme eine Kunden- oder Produktdatenbank teilen. Die Vorteile liegen auf der Hand: Nicht nur die Daten sind konsistent, sondern auch das Datenformat. Änderungen an Daten und Datenformaten stehen sofort allen System zur Verfügung. Die Systeme können sogar Datenformate wiederverwenden, was die Entwicklung und Wartung vereinfacht.
Microservices sollen keine zentrale Datenbank nutzen. Denn eine gemeinsame Datenbank widerspricht der Entkopplung. Es ist kaum sinnvoll, den hohen technischen Aufwand für Microservices zu betreiben, um dann durch eine gemeinsame Datenbank doch wieder eine enge Kopplung zu bekommen. Bei einer gemeinsamen Datenbank sind Änderungen an den Schemata kaum möglich, weil sie jedes System betrifft, das die Datenbank verwendet. Also müssen solche Änderungen zwischen allen Microservices abgestimmt und nachgezogen werden. Nicht nur aus diesem Grund ist es auch problematisch ein „kanonisches“ Datenmodell zu definieren, das systemübergreifend gelten soll [2]. Ebenso leidet die Robustheit: Der Ausfall der Datenbank führt dazu, dass alle Microservices ebenfalls ausfallen.
Daten-Microservice
Eine Lösung ist, den Zugriff auf die Datenbank in einem eigenen Microservice zu kapseln (Abb. 1). Also würde es einen Bestellung-Daten-Microservice statt einer Bestellung-Datenbank geben. Der Regel „Jeder Microservice hat seine eigene Datenbank“ ist damit genüge getan. Wenn die Microservices den Ausfall anderer Microservices beispielsweise mit einem Cache kompensieren können, dann ist die Lösung auch robust.
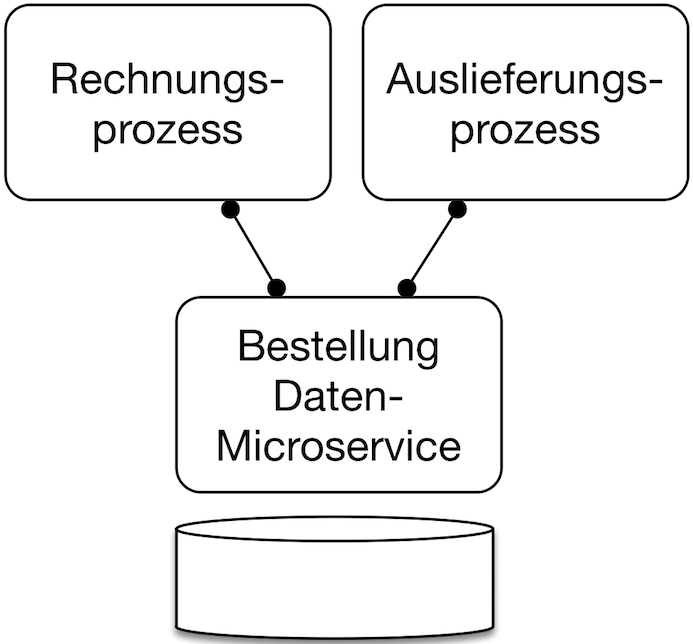
Aber dieser Ansatz hat auch Nachteile:
- Jeder Zugriff auf die Daten ist nun eine Kommunikation zwischen Microservices und geht damit über das Netzwerk. Das beeinflusst die Performance. Außerdem wird ein Ausfall wahrscheinlicher, da nun der Zugriff über das Netzwerk und auf einem anderen Server stattfindet – und damit ist viel mehr Infrastruktur im Spiel, die ausfallen kann.
- Ebenso sind Transaktionen über verschiedenen Daten nun nicht mehr möglich, da die Zugriffe über das Netz keine Transaktionen unterstützen.
- Soll eine Änderung einen Prozess wir einen Rechnungserstellung und auch Daten beispielsweise einer Bestellung umfassen, so sind nun mehrere Microservices zu ändern und neu zu deployen. So wird ein wesentlicher Vorteil der Microservices zunichtegemacht: Das unabhängige Deployment. Nun müssen nämlich mehrere Microservices angepasst werden und auch neu deployt werden, wenn eine Änderung notwendig ist.
Also schränken Daten-Microservices die Entkopplung aus unterschiedlichen Gründen ein. Die Entkopplung ist aber eine wesentliche Eigenschaft von Microservices. Dem steht gegenüber, dass der Daten-Microservice die einzige Quelle für die Daten ist und so Konsistenz sicherstellen kann. Es ist klar, welchen Stand jeder Datensatz gerade hat. Das kann beispielsweise relevant sein, um zuverlässig über einen Lagerbestand Auskunft zu geben.
Kapselung
Von der Architektur-Perspektive hat dieser Ansatz aber noch ein ganz anderes Problem: Er entspricht nicht mehr den Ideen der Einkapselung und des Information Hiding. Ein Microservice ist ein Modul und sollte daher seine internen Datenstrukturen nicht nach außen exponieren, sondern verstecken. Eine Klasse in einem objekt-orientierten System erlaubt deswegen keinen Zugriff auf ihre Instanzvariablen. Für ein grob-granulares Modul wie einen Microservice sind die internen Datenstrukturen in der Datenbank. Wenn also die Daten aus der Datenbank einfach nach außen sichtbar gemacht werden und andere Microservices auf die Daten zugreifen, widerspricht das der Kapselung.
Dadurch ergeben sich die Probleme bei der Nutzung eines Daten-Microservice: Der Daten-Microservice exponiert seine internen Datenstrukturen. Wenn ein Use Case diese Daten benötigt, greift er auf den Daten-Microservice zu und nutzt seine internen Datenstrukturen. Der Daten-Microservice kann nicht anders umgesetzt werden – das Ziel ist ja gerade, Daten zu verwalten und zu exponieren. Die Alternative wäre, dass der Use Case die Daten selber verwalten – so wie eine objekt-orientierte Klasse in erster Linie Methoden und Logik zur Verfügung stellt und die Daten intern hält. Ein Daten-Microservices ist so wie eine Klasse, die nur Instanzvariablen sowie Getter und Setter hat.
Datenbanken und Schemas
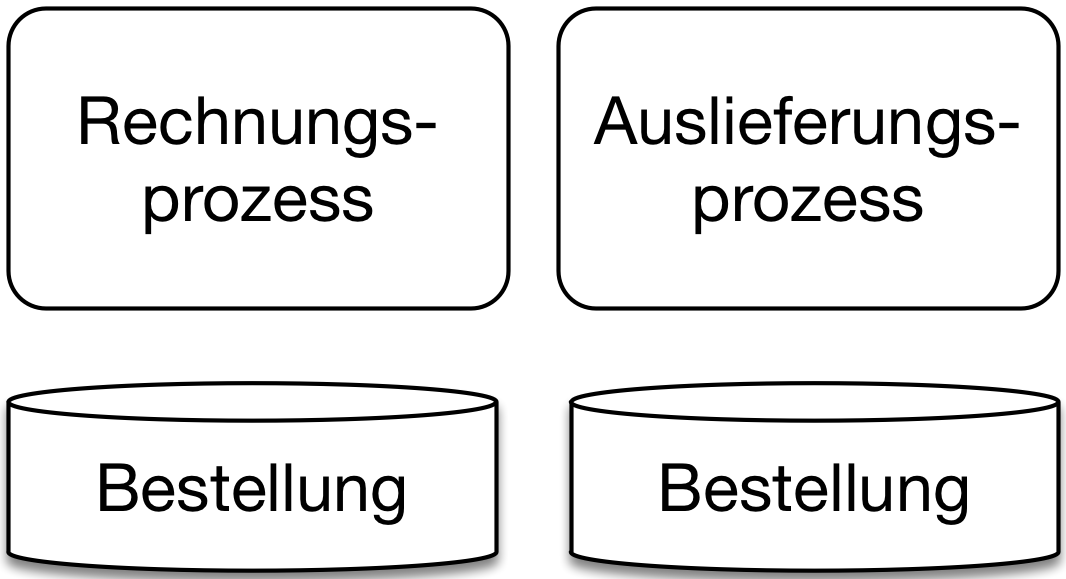
Also sollte jeder Microservice seine eigene Datenbank haben (Abb. 2). Das ermöglich polyglotte Persistenz: Jeder Microservice kann eine andere Datenbank nutzen – beispielsweise eine relationale Datenbank oder eine Graphendatenbank wie neo4j, die vor allem für Graphenprobleme nützlich ist. Dann muss es jedoch für jede Datenbank ein eigenes Konzept für Backup und Disaster Recovery geben, so dass der Aufwand für den Betrieb recht hoch ist. Polyglotte Persistenz entspricht der Idee der Technologieunabhängigkeit der Microservices, nach der jeder Microservices einen eigenen Technologie-Stack nutzen kann. Aber im Vergleich zur Nutzung beispielsweise eines anderen Frameworks sind die Konsequenzen bei Datenbanken schwerwiegender, da der Aufwand für den Betrieb so hoch ist.
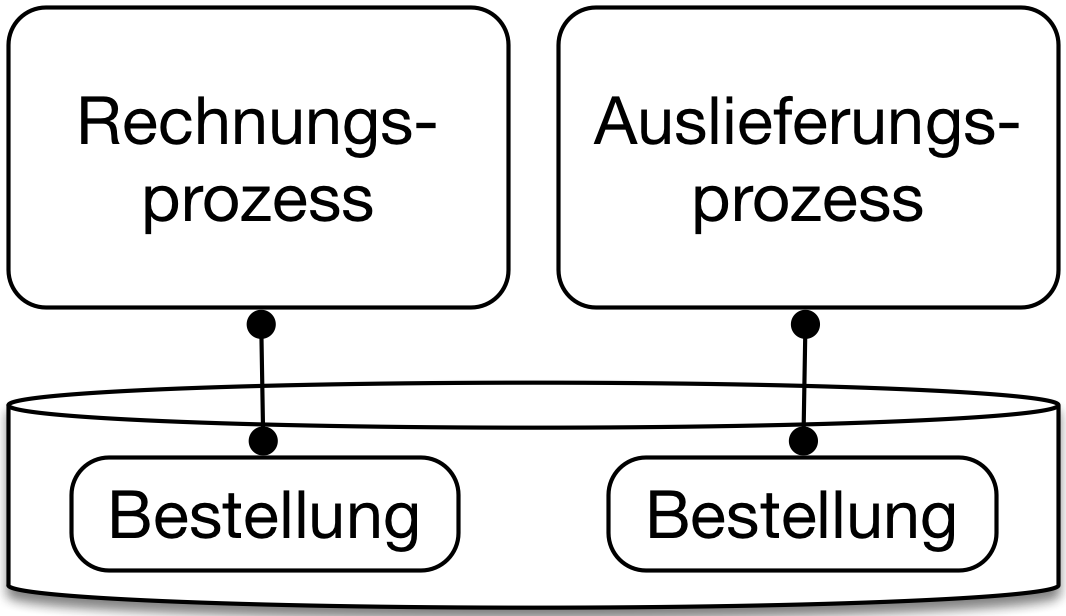
Eine Alternative sind getrennte Schemata in der Datenbank (Abb.3). Dann hat jeder Microservice ein getrenntes Datenbankmodell, aber sie teilen sich dennoch eine Datenbank. Das kann die Robustheit beeinträchtigen, weil ein Ausfall der Datenbank zu einem Ausfall aller Microservices führt. Aber dafür ist der Aufwand für den Betrieb geringer und die Entkopplung auf der Architektur-Ebene kann so sichergestellt werden.
Redundanz?
Also würde die zentrale Bestellungsdatenbank ersetzt werden durch eine Kopie der Daten in den einzelnen Datenbanken der Microservices, die jeder Daten für die Bestellung enthalten. Also sind die Daten nun redundant gespeichert – und normalerweise ist das eine Todsünde. Daten können nun inkonsistent werden, weil sie in allen System geändert werden müssen. Es sind mehrfache Modellierungen der Daten notwendig. Aber sind diese Daten wirklich redundant? Domain-driven Design (DDD) [3][4] behauptet, dass ein Domänenmodell nur in einem bestimmten Kontext gültig ist (Bounded Context). Wenn man bei dem Beispiel der Bestellungsdaten bleibt, so wird jeder Microservice sich für andere Daten interessieren. Ein Microservice, der für die Bestellung eine Rechnung schreiben soll, muss die Preise und Steuersätze der Waren kennen. Ein Microservices, der die Waren ausliefern soll, muss diese Daten nicht kennen, sondern die Größe und Verfügbarkeit der Waren. Also haben beide Microservices zwar Bestellungsdaten, aber diese Daten sind nicht redundant. Vielmehr stellt jeder der Services einen Bounded Context dar und verwaltet nur eine Facette der Bestellung. Ein möglicher Grund für die Komplexität eines Datenmodells ist, dass zu viele Facetten oder Bounded Context abgedeckt werden sollen.
Also sind Daten nun in den verschiedenen Bounded Contexts bzw. Microservices unterschiedlich modelliert. Dennoch gibt es die Bestellung irgendwie doch als gemeinsames Datum. Dazu definiert DDD Context Relationships. Das sind Beziehungen zwischen Bounded Contexts. Ein Beispiel ist ein Shared Kernel (gemeinsamer Kern). Mehrere Bounded Context teilen sich einen Teil ihres Domänenmodells. So können bei einer Bestellung beispielsweise die Bestellnummer oder die bestellten Waren Teil des Shared Kernels sein, die der Service für die Rechnung oder die Auslieferung passend ergänzt.
Die Context Relationships sind nicht nur relevant für die Architektur, sondern sie definieren auch, wie Team miteinander kollabieren. Für den Shared Kernel ist die ursprüngliche Idee [3], dass die Teams gemeinsam den Code für das Modell implementieren und außerdem die Tests sowie das Datenbank-Schema. Das führt zu einer engen Kopplung der Teams und der Komponenten und erscheint daher für Microservices kaum umsetzbar. Dennoch könnten mehrere Microservices sich sicher einige wesentliche Informationen über beispielsweise eine Bestellung teilen.
Dazu könnte ein Daten-Microservices eine Möglichkeit sein. Die Daten aus dem Shared Kernel werden dann in diesem Service abgelegt. Damit gehen die schon erwähnten Probleme einher: Der Service kann ausfallen, die Performance ist nicht besonders gut und es gibt keine Möglichkeit für Transaktionen, die den Shared Kernel und die Daten in dem jeweiligen Microservice umfassen. Dafür sind die Daten im Shared Kernel für alle Microservices konsistent: Jeder Service hat exakt denselben Stand der Daten im Zugriff.
Eine andere Möglichkeit ist es, die Daten aus dem Shared Kernel in jeden der Microservices zu replizieren. Dann haben die Services vielleicht einen unterschiedlichen Stand der Daten, aber dafür hat jeder Service alle Daten, um einen Request zu bearbeiten. Das kommt Verfügbarkeit, Performance und Widerstandsfähigkeit zu gute.
Wie Daten replizieren?
Um die Daten in die verschiedenen Services zu replizieren, erscheint die Datenbankreplikation nützlich, die in jeder modernen Datenbank enthalten ist. Das ist aber keine sinnvolle Lösung. Mit dieser Art der Replikation werden nicht nur die Daten, sondern auch die Schemata repliziert. Das bedeutet, dass die Microservices sich die Datenstrukturen teilen und so kaum getrennt weiterentwickelt werden können.
Also müssen die Microservices Daten replizieren, aber dabei unterschiedliche Schemata verwenden. Dazu können Events genutzt werden. Eine neue Bestellung löst ein Event aus. Jeder Microservice reagiert darauf auf eine geeignete Art und Weise – beispielsweise kann ein Microservice die Auslieferung der Waren anstoßen und ein anderer die Bezahlung veranlassen. Dazu können die Microservices die notwendigen Daten aus dem Event in der eigenen Datenbank speichern. (Abb. 4)
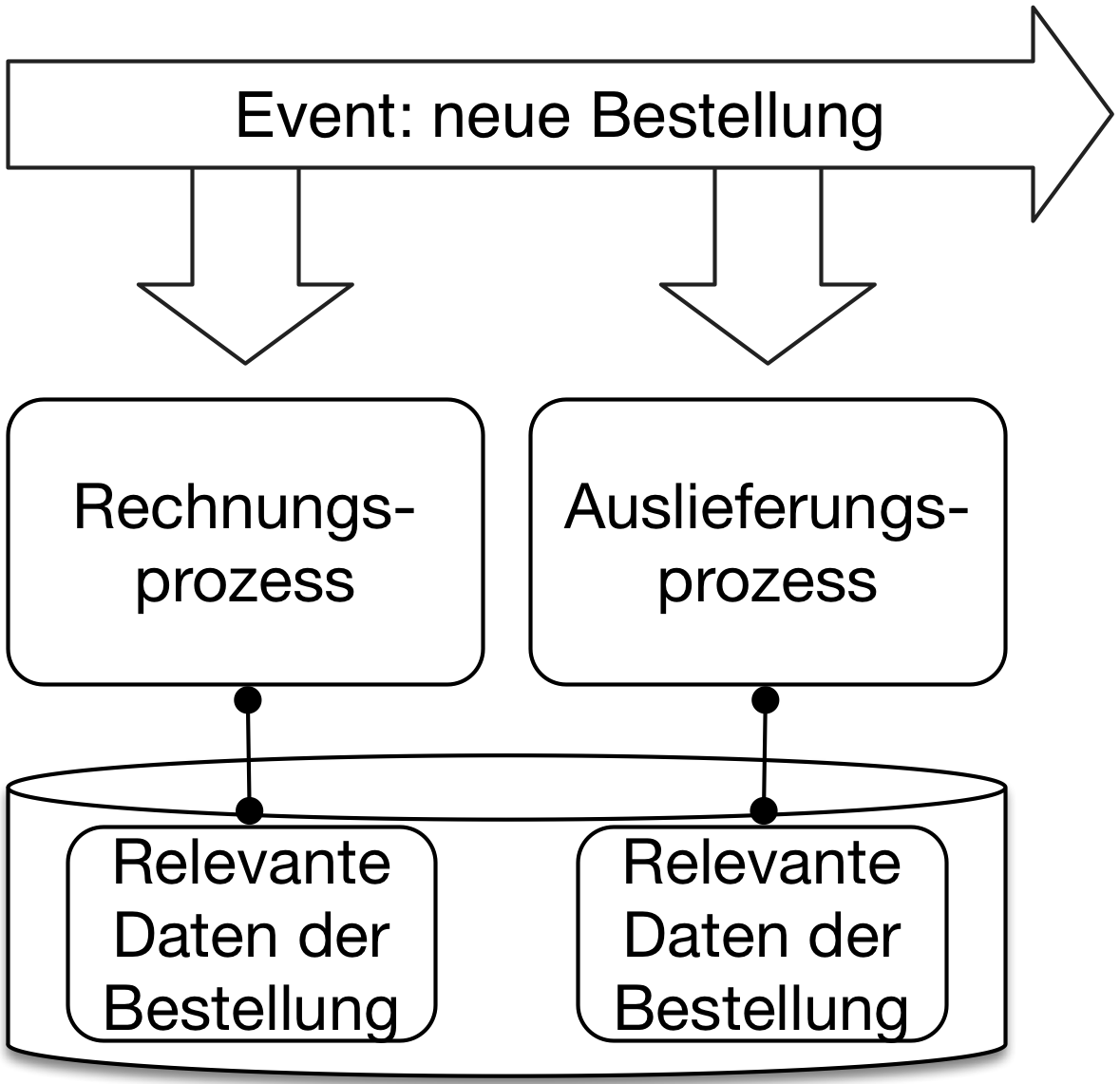
Events
Wenn Microservices durch Event lose gekoppelt sind, dann ergibt sich die Replikation der Daten praktisch von selber. Neben der Replikation der Daten ergeben sich noch weitere Vorteile: Die Systeme sind zeitlich entkoppelt – jedes System kann frei wählen, wann es ein Event bearbeitet. So kann sogar der Ausfall eines Systems toleriert werden – das verlängert nur die Zeit, bis das Event bearbeitet wird.
Inkonsistenzen & Event Sourcing
Auf der anderen Seite kann es durch Events zu Inkonsistenzen kommen. Wenn für die Bestellung zwar eine Rechnung geschrieben wird, aber keine Ware ausgeliefert wird, freut sich der Kunde sicher nicht – hingegen freut sich die Firma sicher nicht, wenn die Ware zwar ausgeliefert wird, aber keine Rechnung geschrieben wird.
Eine Möglichkeit ist, das Event einfach noch einmal zu schicken oder zu bearbeiten, wenn die Inkonsistenz auffällt. In dem Beispiel ist das auch recht einfach möglich, da die Reihenfolge der Rechnungen oder Auslieferungen vermutlich keine Rolle spielt. Problematischer ist es, wenn die Events in einer bestimmten Reihenfolge bearbeitet werden müssen und ein Event nicht bearbeitet wird, aber schon andere Events angekommen sind. Dieses Problem ist durch Event Sourcing (Abb. 5) lösbar. In dem Microservice müssen einige zusätzliche Funktionalitäten implementiert werden, um die Events aus der Event Queue auszulesen:
- Ein Event Store speichert eingehende Events.
- Ein Event Handler verarbeitet die Events.
- Der Event Handler kann dazu einen Snapshot nutzen. Aber der Event Handler sollte auch dazu in der Lage sein, seinen Zustand aus den Events zu rekonstruieren. Bei einem Konto kann der aktuelle Kontostand beispielsweise auch aus allen Buchungen rekonstruiert werden.
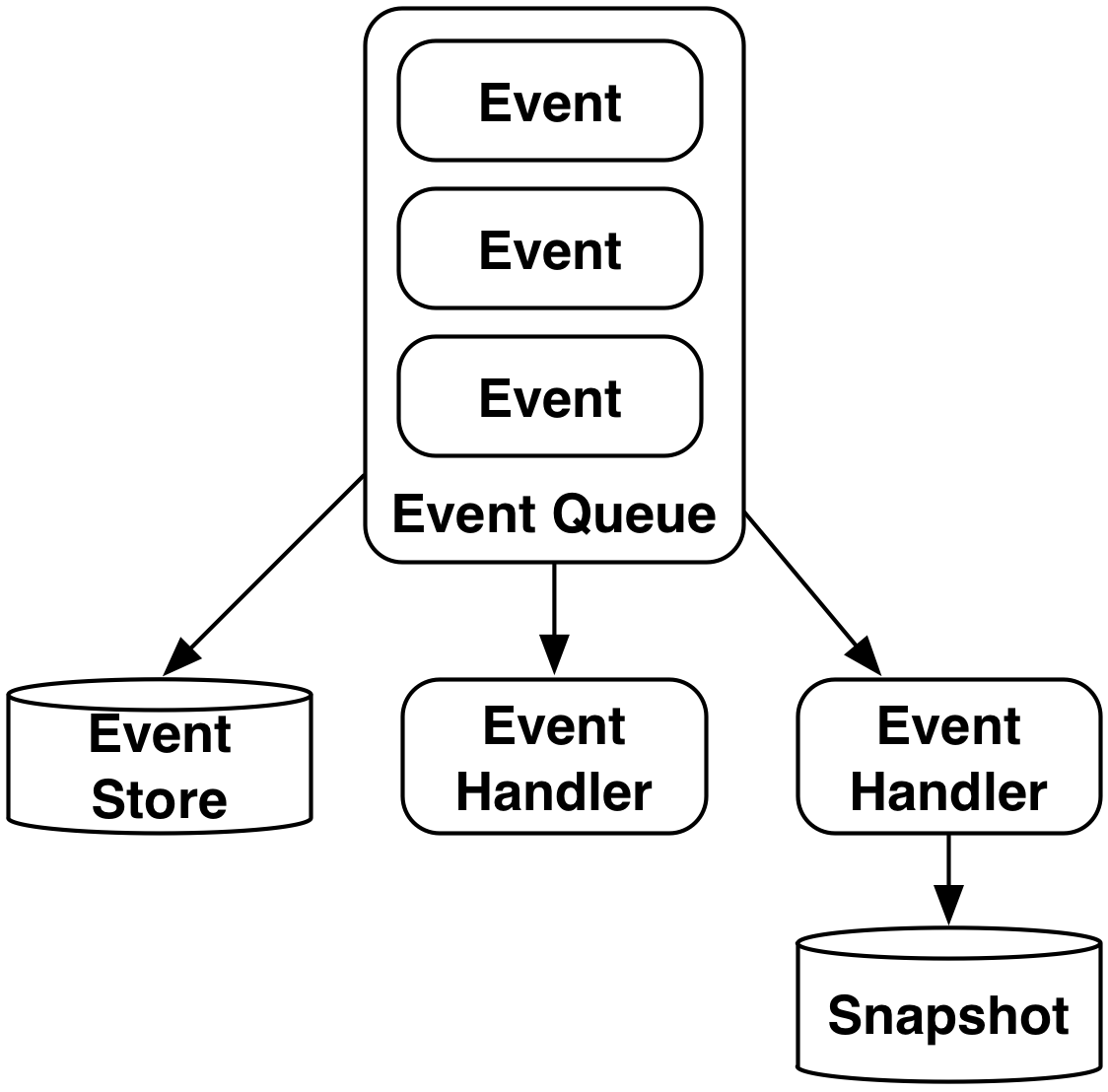
Mit diesem Mechanismus kann eine Inkonsistenz repariert werden, indem der Microservice den Snapshot verwirft und aus den Events neu aufbaut und dabei die Events ebenfalls einbezieht, die vorher nicht verarbeitet wurden.
Batch Replikation
Neben der Replikation mit Events ist es auch möglich, die Daten in einem Batch zu replizieren. Der Batch würde über eine API die Daten auslesen und dann in die Daten in ein eigenes Format überführen. Dieses Vorgehen heißt auch ETL (Extract – Transform – Load). Auch bei diesem Vorgehen sind die Datenstrukturen der beiden Microservices voneinander entkoppelt. Es ergeben sich dieselben Herausforderungen wie bei Events: Die Systeme können inkonsistente Daten haben. Da Batches wahrscheinlich sogar weniger häufig laufen als Events verarbeitet werden, kommt es sogar mit höherer Wahrscheinlichkeit zu Inkonsistenzen. Dafür kann es sein, dass die Reparatur von Inkonsistenzen einfacher ist. Schließlich sind die Systeme darauf ausgelegt, größere Datenmengen zu bearbeiten.
Wichtig für die Entscheidung zwischen Batches und Events ist also, in wie fern Inkonsistenzen tolerierbar sind. Dann kann entweder eine Entscheidung für Events oder Batches getroffen werden.
CAP-Theorem
Scheinbar gibt es also entweder die Möglichkeit, mit den Inkonsistenzen einer Replikation zu leben oder die Gefahr auf sich nehmen, dass ein zentraler Service mit den Daten ausfällt und dadurch Schwierigkeiten entstehen.
Um die Frage nach einer Alternative zu beantworten, lohnt sich ein Blick auf das CAP-Theorem [5]. Es beschreibt den Zusammenhang zwischen drei Eigenschaften eines verteilten Systems:
- C steht für Consistency (Konsistenz). Wenn man verschiedene Knoten nach einem Datum fragt, bekommt man dieselben Informationen.
- Das A ist eine Abkürzung für Availability (Verfügbarkeit). Wenn ein Knoten ausfällt, hält das die anderen Knoten nicht davon ab, weiterhin Anfragen zu beantworten.
- Partition Tolerance (P) ist die Fähigkeit des gesamten verteilten Systems, auch bei Verlust von Nachrichten weiterhin zu funktionieren.
Das CAP-Theorem besagt, dass von diesen drei Eigenschaften nur maximal zwei erfüllt sein können. Diese theoretische Betrachtung lässt sich in der Praxis noch weiter einschränken: Partitionen in einem Netzwerk kommen vor. Also bleibt eigentlich nur die Wahl zwischen AP oder CP. Diese Fälle kann man genauer betrachten. Ein Knoten kann wegen einer Partitionierung im Netzwerk nicht mehr mit den anderen Knoten sprechen. Er hat also einige Änderungen nicht bekommen.
- Bei AP gibt der Knoten eine Antwort, von der bekannt ist, dass sie einen falschen Wert enthalten kann, da eben nicht alle Änderungen vorliegen.
- Bei CP gibt der Knoten keine Antwort, weil die Antwort inkonsistent sein kann – was nicht vorkommen darf. Also ist der Knoten nicht mehr verfügbar.
Eigentlich ist das CAP-Theorem beispielsweise nützlich, um NoSQL-Datenbanken auszuwählen. Sie sind meistens verteilte System und müssen sich für CP oder AP entscheiden. Aber auch bei der den Microservices ist das CAP-Theorem nützlich. Eine Replikation von Daten ist eher AP, eine zentrale Datenhaltung eher CP. Einen weiteren, geschickteren Weg gibt es also nicht.
Zusammenfassung
Klassische Architekturen nutzen zentrale Datenbanken. Dadurch koppeln sich die Systeme sehr stark aneinander. Eine Änderung der Datenbankschemata beeinflusst alle Systeme und ist daher nur möglich, wenn alle Systeme sich koordinieren.
Dem setzten Microservices eine konsequente Entkopplung entgegen, die auch eigene Datenbank-Schemata erfordert. Um mit einem Microservice-System Daten zu verwalten, gibt es verschiedene Möglichkeiten:
- Ein Daten-Microservice kann den Zugriff auf die Datenbank kapseln. So kann zwar Konsistenz gewährleistet werden, aber der zentrale Service führt zu Problemen bei der Verfügbarkeit, Performance und Transaktionen. Außerdem binden sich die Microservices so immer noch eng aneinander, weil sie die Datenstrukturen teilen.
- Jeder Microservice kann eine eigene Datenbank haben – beispielsweise eine relationale Datenbank oder eine Graphendatenbank. Das entspricht der Technologiefreiheit, führt aber zu einem hohen Aufwand beim Betrieb.
- Wenn jeder Microservice ein eigenes Schema in einer gemeinsamen Datenbank hat, können die Microservices ihre Daten unabhängig modellieren und verwalten. Gleichzeitig vermeidet es einen allzu hohen Betriebsaufwand.
Also sollten die Microservices mindestens ihre eigenen Datenbankschemata haben. Auf den ersten Blick scheint das zu redundanten Daten zu führen. Bounded Context besagt aber, dass jeder Microservices wahrscheinlich ein eigenes Datenmodell hat. Dann sind die Daten aber gar nicht redundant.
Wenn jeder Microservice eine Bestellung anders modelliert, müssen sie dennoch bei einer neuen Bestellung informiert werden. Das kann durch einen Event erfolgen oder durch einen Batch-Lauf. So bleibt die Gefahr von Inkonsistenzen und das CAP-Theorem bestätigt, dass nur entweder Konsistenz oder Verfügbarkeit möglich ist. Beides gleichzeitig ist unmöglich.
Diese Erkenntnisse lassen sich natürlich auch auf andere Modularisierungsansätze übertragen. Und vor allem: Vielleicht sollten zentrale Datenbanken einfach generell aufgelöst werden, um eine besserer Modularisierung ein einfachere Datenmodellierung zu erreichen.
Literatur & Links
-
Eberhard Wolff: Microservices: Grundlagen flexibler Software Architekturen, dpunkt, 2015, ISBN 978–3864903137 ↩︎
-
https://www.innoq.com/de/blog/thoughts-on-a-canonical-data-model/ ↩︎
-
Eric Evans: Domain-driven Design: Tackling Complexity in the Heart of Software, Addison-Wesley,2003, ISBN 978–0–32112–521–7 ↩︎
-
Vaughn Vernon: Domain-driven Design Distilled, Addison-Wesley,2016, 978–013443–442–1 ↩︎
-
Brewer, Eric: Towards robust distributed systems in Proceedings of the Annual ACM Symposium on Principles of Distributed Computing 19: 7–10., 2000 ↩︎