
Microservices [1] [2] sind kein fest definierter Begriff. Die ISA-Prinzipien stellen deswegen Regeln für Microservices auf:
- Microservices sind Module. Die Nutzung von Microservices ist eine Entscheidung, die bei jedem System getroffen wird und nicht etwa für die gesamte Firma gelten muss.
- Neben der Makro-Architektur, die Entscheidungen für alle Module umfasst, gibt es auch die Mikro-Architektur. Das sind die Entscheidungen, die nur für jedes Modul anders getroffen werden können. Mehr Mikro-Architektur verbessert die Unabhängigkeit.
- Die Module werden als Docker-Container implementiert. Das erlaubt beispielsweise in jedem Microservice einen anderen Technologie-Stack zu nutzen und so die Entscheidung für einen Technologie-Stack in die Mikro-Architektur zu verschieben.
- Die Integration und Kommunikation zwischen den Microservices muss auf Ebene der Makro-Architektur entschieden werden, um zu gewährleisten, dass alle Microservice miteinander kommunizieren können.
- Ebenso muss die Authentifizierung und andere Metadaten zum Beispiel für das Tracing der Aufrufe zwischen den Microservices als Teil der Makro-Architektur standardisiert werden. Ohne diese Standards ist kein Tracing von Aufrufen zwischen Services möglich und Nutzer müssten sich bei jedem Microservice erneut authentifizieren.
- Microservices können ihre Vorteile erst dann voll ausspielen, wenn sie unabhängig in Produktion gebracht werden können. Dazu müssen die Continuous Delivery Pipelines unabhängig sein. Es darf beispielsweise keine gemeinsame Test-Stages geben, die ein Microservice blockieren und so das Deployment aller anderen Microservices unmöglich machen kann.
- Der Betrieb der Microservices sollte standardisiert sein, um so Aufwand einzusparen.
- Standard dürfen sich nur auf die Schnittstellen beziehen. Beispielsweise kann das Format der Log-Nachrichten definiert sein, nicht aber die Log-Library zur Implementierung. Das ermöglicht Technologie-Unabhängigkeit. Es entspricht auch dem Modul-Konzept, die zwar eine feste Schnittstelle haben, aber bei der Implementierung frei sind.
- Schließlich müssen die Microservices resilient sein. Sie müssen damit umgehen können, dass andere Microservices ausfallen.
Das Gegenteil zu einem Microservices-System ist ein Deployment-Monolith, bei dem alle Module gemeinsam in Produktion gebracht werden. Das ist genauso wie Microservices ein Architektur-Ansatz mit Vor- und Nachteilen. Es ist also keinesfalls sinnvoll, Deployment Monolithen als Architektur-Ansatz von vorneherein auszuschließen.
Vorteile
Wie jede Architektur haben Microservices Vor- und Nachteile. Zunächst gibt es einige technologischen Vorteile:
- Entwicklung, Skalierbarkeit und Ausfall sind entkoppelt. Jeder Microservice kann getrennt entwickelt und skaliert werden. Wenn ein Microservice ausfällt, dann laufen die anderen weiter. Entkopplung ist ein wichtiges Konzept von Modulen und wird so weiter verbessert.
- Für Sicherheit sind Microservices ebenfalls vorteilhaft: Wenn ein Microservice kompromittiert wird, können andere Microservices beispielsweise durch Firewalls geschützt werden.
- Funktionalitäten anderer Microservice können nur über die Schnittstelle genutzt werden, während sonst oft auch die Interna anderer Module zugreifbar sind. Auch das Verschieben von Code zwischen Microservices ist nur schwer möglich. Damit bieten Microservices Architektur-Firewalls: Die Aufteilung in Microservices kann nur schwer geändert werden. So wird die Architektur gegen den Verfall abgesichert.
- Microservices können einzeln ersetzt werden. Dabei kann der neue Microservice einen komplett anderen Technologie-Stack nutzen. Bei einem Deployment Monolithen sind alle Module an die gemeinsame technische Basis gebunden.
- Continuous Delivery bietet erhebliche Vorteile. Neben besserem Time-to-Market beispielsweise stehen Systeme nach einem Ausfall auch schneller wieder zur Verfügung und Entwickler verbringen mehr Zeit mit der Implementierung neuer Features. Durch das unabhängige Deployment erleichtern Microservices Continuous Delivery erheblich.
Auf organisatorischer Ebene ergeben sich ebenfalls Vorteile:
- Jeder Microservice kann seinen eigenen Technologie-Stack haben.
- Jeder Microservice sollte einen unabhängigen Teil der Fachlichkeit implementieren.
- Wenn Technologie und Fachlichkeit der Microservices unabhängig sind, dann können Teams jeweils für einen Microservice verantwortlich sein und unabhängig von den anderen Teams Entscheidungen treffen. Das ermöglicht Selbst-Organisation, bei der jedes Team sich selber darum kümmert, die jeweiligen Probleme in den Microservices zu lösen.
Herausforderungen
Natürlich gibt es auch Herausforderungen:
- Die wichtigste Herausforderung bei Microservices ist der erhöhte Aufwand im Betrieb. Es müssen viele Microservices betrieben werden, während bei einem Deployment-Monolithen nur eine Komponente deployt und betrieben werden muss.
- Die Konsistenz der Daten kann nicht mehr immer gewährleistet werden. Microservices stellen ein verteiltes System dar. Daten sind über Microservices verteilt. Daher können unterschiedliche Microservices unterschiedliche Stände der Daten haben.
- Die Microservices müssen so umgesetzt sein, dass sie mit dem Ausfall anderer Microservices umgehen können, ohne dabei selbst auszufallen.
- Schließlich gibt es im Microservices-Umfeld viele neue Technologien [3] [4], in die man sich einarbeiten muss, weil sie die Umsetzung von Microservices erheblich vereinfachen oder gar erst praktikabel machen.
Gemeinsames Datenmodell
Für das Scheitern von Microservices gibt es unterschiedliche Gründe. Ein Grund kann ein gemeinsames Datenmodell sein. Das gemeinsame Datenmodell muss nicht unbedingt zur Speicherung der Daten dienen, sondern es kann beispielsweise auch nur zu Kommunikation genutzt werden.
Beispielsweise können der Bestellprozess, der Lieferprozess und der Rechnungsprozess alle ein gemeinsames Datenmodell für Kunden oder Waren nutzen (Abb. 1). Um Aufwand zu sparen, kann man das Modell als Library implementieren, die alle Microservices nutzen. Wenn alle Microservices aus Kompatibilitätsgründen immer die neuste Version der Library nutzen müssen, hat man einen Deployment Monolithen implementiert. Die Container können nicht getrennt deployt werden, wenn es eine Änderung am Datenmodell gibt, sondern alle müssen gemeinsam aktualisiert und dann deployt werden. So können die Vorteile von Microservices wie getrenntes Deployment und genau genommen auch die getrennte Entwicklung nicht mehr ausgenutzt werden.
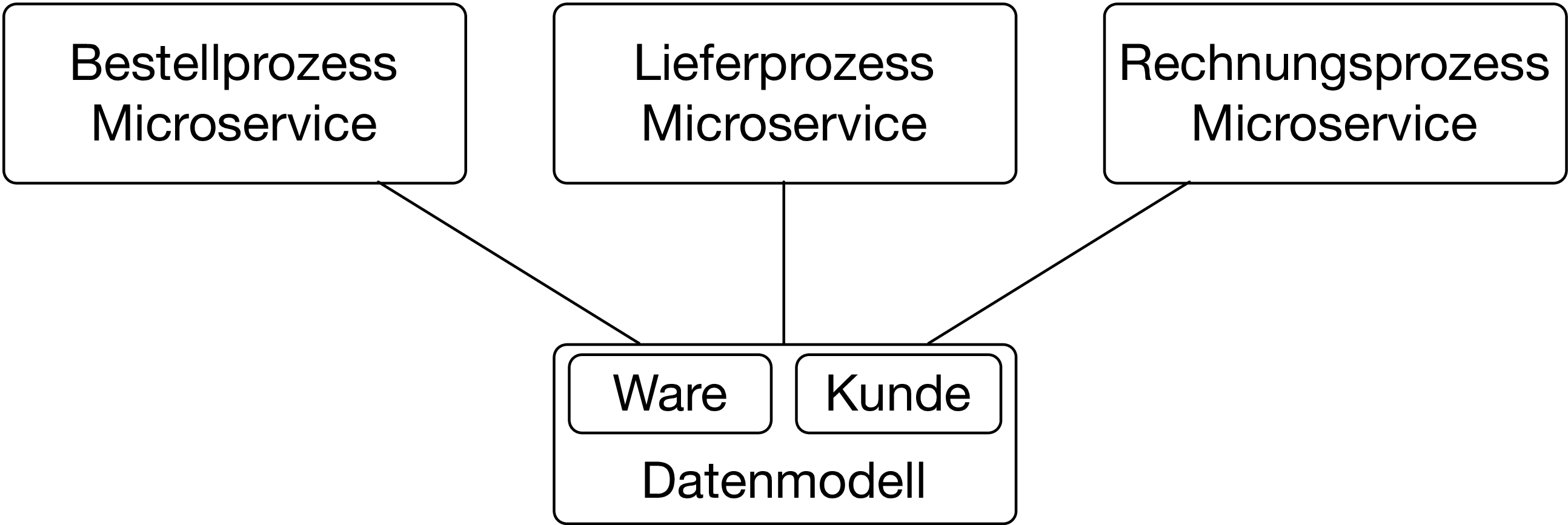
Ein gemeinsames Datenmodell kann Ergebnis moderner Architektur-Ansätze sein. Wenn Microservices über Events miteinander kommunizieren, dann nutzen alle dasselbe Event-Datenmodell. Mit Event Sourcing kann der Zustand eines Microservice aus den Events wieder erzeugt werden. Dazu müssen die Events beispielsweise mit einem Messaging-System wie Kafka gespeichert werden. Wenn nun alle Daten des Rechnungs-Microservice gelöscht werden und dann alle Bestellungen noch einmal bearbeitet werden, dann sollte der Microservice wieder im selben Zustand sein. Das bedeutet, dass der Zustand der Microservices eigentlich nicht relevant ist. Er kann aus den Events wieder ermittelt werden. Also haben die Microservices kein echtes eigenes Datenmodell. Schließlich kann das Datenmodell der Microservices aus dem gemeinsamen Event-Datenmodell erzeugt werden.
Ein solches Datenmodell nutzen alle Microservices. Es stellt daher ein Abhängigkeitsschwerpunkt dar und ist schwer änderbar. Ein Attribut aus dem Datenmodell zu entfernen ist besonders schwierig, weil nicht klar ist, welcher Microservice das jeweilige Attribut nutzt. Dann wird das Datenmodell immer weiter wachsen, da es sicher irgendwann neue Attribute aufnehmen muss, aber alten Attribute nicht so ohne weiteres entfernt werden können.
Events, die in einem Microservices verarbeitet werden müssen und sich für Event Sourcing eignen, haben außerdem eine andere Granularität als Events, die über Microservices hinweg verwendet werden. Eine Vermischung dieser beiden Granularitätsebenen führt dazu, dass Microservices zu viele Abhängigkeiten bekommen.
Die Lösung ist es, konsequent auf lokale Datenmodelle zu setzen. Das Event-Modell für Event Sourcing sollte außerhalb des Microservices nicht bekannt sein. Ein globales Datenmodell sollte man für Kommunikation vermeiden. So kann beispielsweise für die Kommunikation zwischen jeweils zwei Microservices ein eigenes Datenmodell dienen. Das kann zu einer Vielzahl von Modellen führen. Hier gilt es abzuwägen: Ist die Unabhängigkeit wichtiger als eine geringe Anzahl an Modellen? Können alle Anforderungen über einen Kamm geschert werden? Für den Lieferprozess sind Gewicht oder Größe der Waren interessant, für die Rechnungserstellung die Besteuerung und der Preis. Man sollte diese sehr unterschiedlichen Belange eher nicht mit einem einzigen Modell ausdrücken.
Unzuverlässigkeit
In einem Microservices-System kann viel mehr schief gehen. Es gibt mehr Server, die Microservices kommunizieren über ein unzuverlässiges Netzwerk und es gibt viel mehr Services als bei einem Deployment Monolithen. Microservices sind Module und hängen daher voneinander ab. Wenn der Ausfall eines Microservice andere Microservices ebenfalls zum Ausfall bringt, dann führt das zu einem Domino-Effekt, bei dem der Ausfall eines einzigen Microservices am Ende das gesamte System zum Ausfall bringt. Da bei der Anzahl Microservices die Wahrscheinlichkeit für den Ausfall eines Microservice hoch ist, ist die Katastrophe vorprogrammiert.
Die Lösung ist Resilienz. Wenn ein Microservice diesem Design-Ansatz entspricht, funktioniert er auch dann, wenn andere Microservices ausfallen. Wahrscheinlich kann der Microservice dann nur eine eingeschränkte Leistung erbringen. So könnte der Bestellprozess beispielsweise vielleicht nur Bestellungen bis zu einer Obergrenze bearbeitet, wenn die Prüfung der Kreditwürdigkeit ausgefallen ist. Im Extremfall kann der Microservice sogar nur eine Fehlermeldung zurückgeben. Auf keinen Fall darf er bei einem Request blockieren. Dann würden die aufrufenden Microservices ebenfalls ausfallen, weil sie blockiert werden und nach einiger Zeit alle Kapazitäten durch Warten blockiert sind.
Resilienz kann durch asynchrone Kommunikation erreicht werden. Dann werden Nachrichten später bearbeitet. Der Aufrufer wartet nicht auf das Ende der Bearbeitung. Wenn ein Microservice ausfällt, werden Nachrichten eben erst bearbeitet, wenn der Microservice wieder zur Verfügung steht. Aber der aufrufende Microservice fällt nicht aus.
Resilienz hat aber auch seine Grenzen. Wenn beispielsweise der Service für die Authentifizierung ausfällt, können Benutzer sich nicht mehr einloggen. Die einzige resiliente Alternative wäre es, Zugriff ohne Authentifizierung zuzulassen. Das ist aber wohl kaum sinnvoll.
Synchrone Aufrufe
Kaskadierende synchrone Aufrufe sind ein Konzept, dass beispielsweise Netflix umgesetzt hat. Zweifellos können so also auch große Systeme erfolgreich implementiert werden. Zudem sind Entwickler synchrone Aufrufe von imperativer Programmierung gewohnt. Bei kaskadierenden synchronen Aufrufen führt ein Aufruf dazu, dass andere Microservices aufgerufen werden, die wiederum andere Microservices aufrufen können.
Aber dieser Ansatz hat einige Nachteile:
- Durch die viele Netzwerk-Kommunikation ergeben sich Performance-Probleme, weil Netzwerk-Kommunikation langsamer als lokale Aufrufe ist. Außerdem addieren sich die Latenzen auf, wenn die Aufrufe nicht parallel abgearbeitet werden. Parallelität macht aber das Programmiermodell natürlich komplizierter.
- Bei synchronen Aufrufen ist es schwierig, Resilienz zu gewährleisten. Ein synchroner Aufruf bedeutet, dass der Microservice erst weitermacht, wenn das Ergebnis des Aufrufs vorliegt. Also ist das Ergebnis wichtig. Dann kann der Microservice aber kaum ohne dieses Ergebnis weiterarbeiten.
Dementsprechend ist es sinnvoll, Microservices asynchron aufzubauen. Wenn die Microservices relativ unabhängige Teile der Domäne implementieren, dann ist eine asynchrone Kommunikation recht einfach umsetzbar. Trotzdem gibt es erfolgreiche synchrone Microservices-System wie beispielsweise Netflix, die aber nicht als Vorbild für eigenen Implementierungen dienen sollten. Ganz wird sich die synchrone Kommunikation nicht verhindern lassen.
Entity Service
Ein Microservice, der ein Domänenobjekt wie Kunden oder Waren verwaltet, scheint zunächst eine gute Idee (Abb. 2). Allerdings ist es offensichtlich ein zentrales Domänenmodell, das wie schon diskutiert viele Nachteile hat. Praktisch jede Funktionalität wie beispielsweise ein Bestellprozess braucht Zugriff auf Waren oder Kunden. Der Zugriff ist eigentlich nur mit synchroner Kommunikation umsetzbar. Ein Aufruf an den Bestellprozess-Microservice ruft den Kunden-Microservice und den Waren-Microservice mindestens einmal auf. Das führt zu schlechter Performance und höherer Latenz. Außerdem wird das System unzuverlässig, weil bei einem Ausfall eines Entity Service kaum Resilienz umgesetzt werden kann.
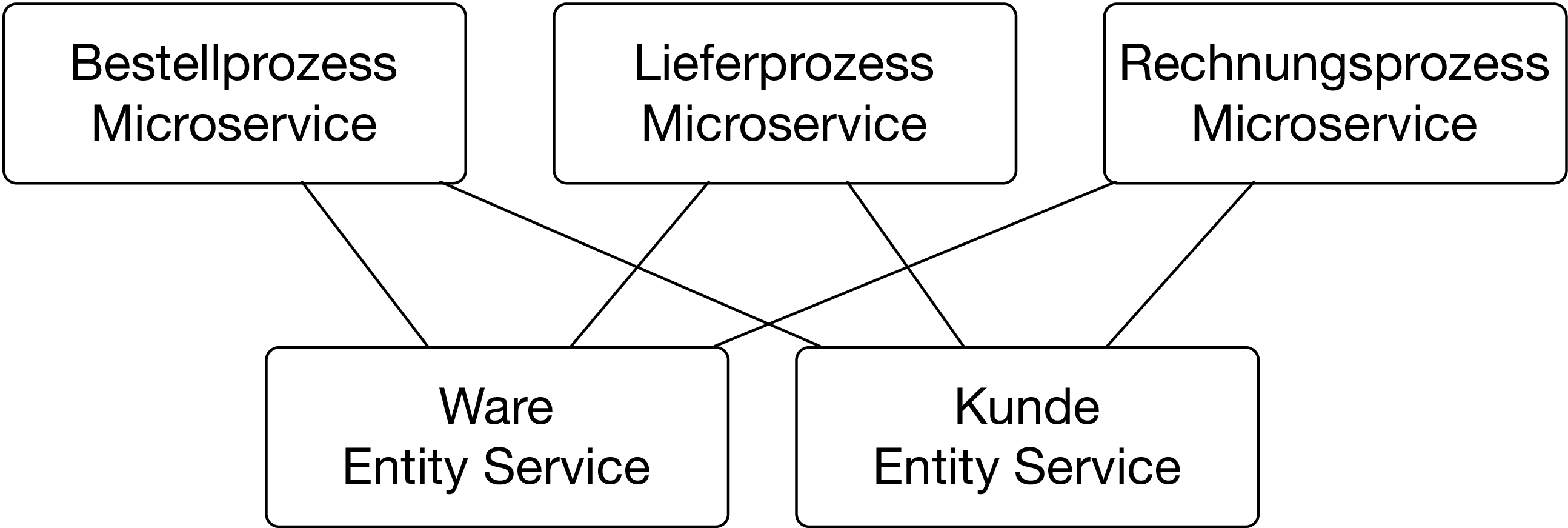
Statt der Entity Services kann eine gemeinsame Datenbank verwendet werden. Dann hat das System immer noch ein gemeinsames Datenmodell, aber die Probleme im Bereich Performance, Latenz oder Zuverlässigkeit sind gelöst. Das Datenmodell in der Datenbank wird für die interne Repräsentation der Daten im Microservice genutzt, was Änderungen des Datenmodell ohne Beeinflussung der anderen Microservices praktisch unmöglich macht und zu starken Abhängigkeiten zwischen den Microservice führt. Das gilt natürlich nur, wenn die Microservice sich ein Datenbank-Schema teilen. Nutzen die Microservices eine gemeinsame Datenbank aber getrennte Schemata, dann sind sie architektonisch unabhängig. Ein Ausfall der Datenbank führt dann allerdings zu einem Ausfall aller Microservices, was aber bei einer genügend hohen Verfügbarkeit der Datenbank akzeptabel sein kann.
Die Lösung ist es, Domänenobjekte in jedem Microservice zu modellieren. Das ist auch sinnvoll, weil beispielsweise für die Lieferung andere Informationen der Ware (Gewicht, Größe) als für die Rechnung (Preis, Steuer) notwendig sind (Abb. 3). Domain-driven Design [5] bezeichnet diese unterschiedlichen Modelle als Bounded Context, also einen abgeschlossenen Kontext wie Lieferung oder Rechnungslegung, in dem ein eigenes Domänenmodell sinnvoll ist.

Betrieb
Um Microservices umzusetzen, muss der Betrieb die Vielzahl an Microservices deployen und betreiben. Dazu ist meistens der Einsatz neuer Technologien notwendig. Die existierenden Technologien, Prozesse und Teams unterstützen oft den Wandel hin zu Microservices nicht ausreichend.
Das Problem des zusätzlichen Aufwandes im Betrieb stand von Anfang an im Zentrum der Microservices-Diskussion und ist daher recht offensichtlich. Ob ein Betriebs-Team dieses Problem lösen kann, ist meistens auch einfach zu erkennen. Gegebenenfalls kann dieses Problem dazu führen, dass man Abstand von der Microservices-Architektur nehmen muss. Das ist sicher besser als mit einem fertig entwickelten Microservices-System an Problemen im Betrieb zu scheitern.
Eine Lösung können neue Technologien wie Kubernetes bringen, die den Betrieb von Microservices deutlich vereinfachen. Für den ersten Microservice ist es allerdings sicher noch nicht notwendig, eine komplett neue Umgebung zu etablieren. Ein einzelner Microservice kann sicher auch in einer klassischen Umgebung betrieben werden.
Ein Platform as a Service (PaaS) wie Cloud Foundry oder OpenShift kann eine technologische Lösung für dieses oft eher soziale Problem sein. Nachdem der Betrieb das PaaS installiert hat, steht eine Plattform zur Verfügung, auf der beliebige Microservices installiert werden können. Dazu muss der Betrieb nicht mehr beteiligt werden. Diese „Agilisierung“ des Betriebs wird oft als Hauptvorteil eines PaaS dargestellt.
Eine Alternative ist die öffentliche Cloud. Sie bietet eine Vielzahl an Technologien, die ohne weitere Installation zur Verfügung stehen. Dazu gehören PaaS, Kubernetes aber auch beispielsweise Datenbanken. Bestimmte Betriebsprozesse wie das Booten eines Servers beim Ausfall können dabei automatisiert werden, so dass der Betrieb entlastet wird.
Schlechte Struktur
Oft werden Microservices genutzt, um Systeme leichter wartbar und änderbar zu machen. Die Wartbarkeit eines Systems hängt von der Aufteilung in Module ab. Microservices implementieren die Module nur anders. Wenn die Aufteilung in Module schlecht ist, ändert eine Implementierung als Microservices daran auch nichts.
Ein schlecht strukturiertes Microservices-System führt sogar zu größeren Problemen als ein schlecht strukturierter Deployment Monolith. Bei einem schlecht strukturierten Deployment Monolithen müssen zwar mehrere Module geändert werden, wenn eine Anforderung implementiert werden soll. Danach kann das System als Ganzes aber einfach deployt werden.
Wenn eine Änderung wegen der schlechten Strukturierung mehrere Microservice betrifft, dann muss das Deployment der verschiedenen Microservices koordiniert werden. Außerdem kommunizieren die Microservice in einem schlechten strukturierten System auch viel miteinander, was Latenz, Performance und Resilienz negativ beeinflusst. Und die Architektur-Firewalls erschweren es zusätzlich, die Struktur des Microservices-System zu verbessern.
Die Verbesserung der Struktur kann durch das Entkoppeln der Logik beispielsweise mit Domain-driven Design und Bounded Context erreicht werden. Daher ist es nicht sinnvoll, ein schlecht strukturierten Deployment Monolithen unter Beibehaltung der Struktur in ein Microservices-System zu migrieren. Stattdessen sollte ein Bounded Context nach dem anderen aus dem System herausgeschnitten werden, um so auch die Struktur zu verbessern.
Organisation
Microservices ermöglichen unabhängige Teams, da die Microservices technisch und fachlich unabhängig sind. Wenn jedes Team an einem Microservice arbeitet, muss es sich kaum mit anderen Teams koordinieren. Wenn aber eine Gruppe von Architekten alle wesentlichen Entscheidungen für alle Teams trifft, wird dieser Vorteil nicht ausgenutzt.
Die Lösung ist es, Verantwortung zu delegieren. Das erfordert Vertrauen in die Teams und Mut. Durch das Delegieren verhalten sich Teams allerdings auch anders. Wenn Änderungen direkt in Produktion gehen und nicht erst noch durch ein Test-Team bewertet werden, wird sich das Verhalten der Entwickler auch entsprechend ändern.
-
Eric Evans: Domain-driven Design Referenz, kostenlos unter http://ddd-referenz.de/ ↩
-
Eberhard Wolff: Microservices - Ein Überblick, kostenlos unter https://microservices-buch.de/ueberblick.html ↩
-
Eberhard Wolff: Das Microservices-Praxisbuch: Grundlagen, Konzepte und Rezepte, dpunkt, 2018, ISBN 978–3864905261 ↩
-
Eberhard Wolff: Microservices Rezepte - Technologien im Überblick, kostenlos unter https://microservices-praxisbuch.de/rezepte.html ↩
-
Eric Evans: Domain-driven Design Referenz, kostenlos unter http://ddd-referenz.de/ ↩