
Alle Projekte müssen Software in Produktion bringen – also sollten die Herausforderungen in diesem Bereich bereits gelöst sein. Zumindest nachdem Continuous Delivery vor mittlerweile mehr als fünf Jahren dieses Thema in den Fokus gestellt hat. Eigentlich geht es nur um das automatisierte Deployment – und gerade in diesem Bereich sind neuere Werkzeuge wie Chef, Puppet, Ansible oder Ansätze wie Docker eine wesentliche Vereinfachung. Also sollte der Umsetzung von Continuous Delivery nichts mehr entgegenstehen.
Continuous Delivery = Tests
Das Ziel von Continuous Delivery [1] ist, Software möglichst regelmäßig in Produktion zu bringen. Das Deployment von Software dauert selbst bei manuellen Vorgehen nur sehr selten länger als einen Tag. Die neuen Deployment-Werkzeuge reduzieren diesen einen Tag. Aber wenn die Installation nur einen Tag dauert, ist es möglich, Software jede Woche oder noch öfter zu deployen. Die Installation selber kann also nicht der Grund sein, warum Unternehmen dennoch Quartals-Releases machen oder noch weniger häufig deployen.
Das Problem ist nicht das Deployment. Software wird nur selten in Produktion gebracht, weil das Vertrauen in die Software fehlt. Leider ist es so, dass doch Fehler in der Software sind, die erst in der Produktion auffallen und Schaden verursachen – oder einfach den Gang in Produktion vollkommen verhindern. Die Automatisierung des Deployments ist also eigentlich die falsche Maßnahme, um Software öfter und mit einer höheren Qualität in Produktion zu bringen. Wirklich wichtig ist die Optimierung der Tests:
- Die Tests müssen wesentlicher schneller durchlaufen. Wenn ein Test-Team Wochen benötigt, um die Software zu testen, dann sind schnelle Release-Zyklen kaum umsetzbar. Nur eine Automatisierung kann die notwendige Geschwindigkeit bieten.
- Wenn ein Kunde die Anwendung noch manuell testet, wird das Release ebenfalls verzögert. Außerdem können gerade bei diesem Schritt unklare Fehlerbeschreibungen entstehen, so dass offenbleibt, wie die Fehler reproduziert werden können und ob die Fehler tatsächlich behoben werden.
Akzeptanz-Tests überprüfen, ob die Software die Anforderungen der Kunden erfüllt. Gerade diese Tests sollten automatisiert sein. Erst so sind schnelle Release-Zyklen möglich. Außerdem sollten die Kunden so viel Vertrauen in die Tests haben, dass sie die Anwendung nicht mehr selber manuell testen. Dazu ist es notwendig, dass Kunden automatisierte Tests nicht nur verstehen, sondern so weit vertrauen, dass sie die Anwendungen nicht mehr selber manuell testen müssen.
Technische Lösungen dazu gibt es einige: Beispielsweise Behaviour-driven Design (BDD), bei dem Anforderungen als natürlichsprachlicher Text formuliert werden und dann automatisiert ausgeführt werden. Wesentlicher Vorteil: Kunden sollten dazu in der Lage sein, den natürlichsprachlichen Text und damit den Test zu verstehen. Technisch stehen dahinter eine Art Lückentext. Der Code liest aus dem Lückentext entsprechende Variablen aus und führt dann den Code aus.
Natürlich können auch automatisierte UI-Tests eine Option sein. Schließlich testen Kunden oft die Anwendung von der Oberfläche her – so wie normale Benutzer die Anwendung auch verwenden würden. Allerdings sind Tests über die Benutzeroberfläche fragil, weil kosmetische Änderungen an der Benutzeroberfläche die Tests brechen können – selbst wenn die Logik unverändert bleibt. Außerdem sind die Tests oft langsam und unzuverlässig. Um es noch einmal klar zu sagen: Die Anforderungen an die automatisierten Akzeptanztests sind, dass der Kunde die Software akzeptiert, wenn der Test erfolgreich ist. Der Kunde muss daher nicht nur den Test verstehen, sondern an der Gestaltung des Tests mitarbeiten. Nur so kann er sicher sein, dass der Test wirklich das testet, was für ihn relevant ist. Natürlich muss der Kunde den Test nicht selber schreiben – aber er muss den Test verstehen und ihm vertrauen.
Tatsächlich automatisierte Tests zu erstellen, denen die Kunden vertrauen, ist wirklich schwierig. Aber die Vorteile, die sich dadurch ergeben, sind so groß, dass es den Aufwand wert ist. Es ist sogar entscheidend für den Erfolg von Continuous Delivery. Die Lösung liegt nicht nur im technischen Raum. Wenn ein Entwickler einen Test mit einem BDD-Tool [2][3] schreibt, den nie ein Kunde sieht, wird das Ziel sicher nicht erreicht. Der Kunde soll den Tests ja vertrauen. Es ist sogar kontraproduktiv: Der Entwickler kann Tests einfacher in einer Programmiersprache schreiben als in natürlicher Sprache.
Der Kunde muss direkt an den Tests mitarbeiten. Dazu ist intensive Kommunikation mit den Entwicklern und den Testern notwendig. Alle beteiligten müssen ein gemeinsames Verständnis der Tests aufbauen. Selbst Tester haben oft Schwierigkeiten mit automatisierten Tests. Sie wissen zwar, wie man Software testet, aber wie man die Tests automatisiert, ist ihnen oft nicht klar. Zudem müssen Tests eindeutig definieren, was die Software tun soll. Genau das ist ein Kernproblem in der Software-Entwicklung. Was soll die Software tatsächlich leisten? Deswegen setzt agile Softwareentwicklung die Software in Iterationen um, so dass immer wieder neue Anforderungen umgesetzt werden können, weil eine vollständige Spezifikation nicht möglich ist. Tests sind die eindeutige Definition der Anforderungen und treiben daher das Problem auf die Spitze.
Ständig Deployen!
Eine weitere Herausforderung ist, dass die Automatisierung des Deployments eines großen und komplexen Deployment-Monolithen kaum zu bewältigen ist. Vor allem, wenn es fundamentale Änderungen gibt. Das Deployment großer Änderungen an einem Deployment Monolith zu automatisieren, ist aber auch gar nicht das Ziel von Continuous Delivery.
Wie der Name schon verrät, geht es bei Continuous Delivery darum, Software kontinuierlich auszuliefern (Abb. 1). Also sollten Deployments öfter stattfinden. Und damit kann ein Deployment keine fundamentale Änderung an der Software in Produktion bringen. Wenn Änderungen öfter deployt werden, kann jede Änderung nur verhältnismäßig klein sein. Das reduziert das Risiko, denn die Wahrscheinlichkeit für einen Fehler sinkt, weil die Änderung nicht so groß ist. Strategien wie Blue/Green Deployment sind einfacher umzusetzen. Dabei wird eine komplett neue Umgebung aufgebaut, so dass die neue Version ausführlich getestet werden kann und beim einem Problem das Deployment zurückgerollt werden kann.
Auch an dieser Stelle kann der Kunde dem Projekt einen Strich durch die Rechnung machen. Oft sind Kunden daran gewöhnt, in Quartalsreleases zu denken. Daraus ergibt sich eine lange Liste von Features, die alle umgesetzt werden müssen, um die Software wirklich weiterzuentwickeln. Also kann es nur ein großes Release geben, bei dem alle diese Features live gehen.
Das widerspricht der kontinuierlichen Auslieferung. Viel wichtiger ist allerdings, dass dieses Vorgehen ein wichtiges Optimierungspotential von Continuous Delivery zunichtemacht. Forschung [4] zeigt, dass weniger als die Hälfte aller Features tatsächlich die erwarteten Ergebnisse bringen – also mehr Umsatz, Registrierungen oder wie auch immer Erfolg gemessen wird. Meiner Erfahrung nach ist die Situation oft sogar schlimmer: Es ist gar nicht klar, wie der Erfolg eines Features gemessen werden soll.
Um es noch einmal klar zu sagen: Die Hälfte der Features, die Entwickler programmieren, erzeugt keinen Nutzen oder hat sogar einen negativen Effekt. Und viele Projekte messen den Erfolg oder Misserfolg noch nicht einmal. Offensichtlich liegt in diesem Bereich ein großes Optimierungspotential.
Ein großes Release investiert in sehr viele Features. Ein besserer Ansatz ist, einzelne Features zu implementieren und bei Kunden zu testen. Dadurch kann man herausfinden, ob die gewünschten Effekte überhaupt eintreten. Wenn das Feature tatsächlich erfolgreich ist, kann es erweitert werden. Wenn nicht, wendet sich das Team einem anderen Feature zu. Ein Beispiel: Die Registrierung soll verbessert werden. Der erste Schritt sollte sein, den Erfolg der Verbesserung zu messen. Das kann beispielsweise die Absprungrate sein – wie viele Benutzer beginnen mit der Registrierung, beenden sie aber nicht? Dann sollten mögliche Optimierungen implementiert werden. Änderungen an der Oberfläche wie beispielsweise mehr oder weniger Schritte in der Registrierung oder Eingabehilfen sind sicher einfacher zu implementieren als neue Arten von Benutzern, die komplett andere Rechte haben. Jede dieser Maßnahmen sollte einzeln umgesetzt werden, um den Erfolg zu messen und gegebenenfalls Ansätze frühzeitig verwerfen zu können.
Dazu müssen aber die Features einzeln eingeplant werden und das Projekt muss darauf reagieren, dass nicht alle Änderungen die gewünschten positiven Auswirkungen haben. Wenn dieser Ansatz umgesetzt wird, dann kann Continuous Delivery seine volle Wirkung entfalten.
Gerade Techniker sind nicht immer dazu in der Lage, Kunden davon zu überzeugen, ihr Vorgehen zu ändern. Ein Denken in kleinen Features und Releases ist ganz anders als die üblichen Quartals-Releases. Aber das muss nicht unbedingt ein Grund sein, Continuous Delivery nicht einzuführen. Continuous Delivery erleichtert nicht nur Experimente, sondern erhöht auch die Zuverlässigkeit des Deployments. Das alleine kann schon ein ausreichender Grund sein, um Continuous Delivery einzuführen. So kann Software einfacher und zuverlässiger in Produktion gebracht werden – was sicher jedem gefällt, der in der Software-Entwicklung arbeitet.
Microservices: Architektur für Continuous Delivery
Um Continuous Delivery zu ermöglichen, kann noch eine andere Maßnahme ergriffen werden: Durch die Software-Architektur kann das Deployment vereinfacht werden. Die Aufteilung einer Software in Microservices [5] erlaubt es, jeden Microservice einzeln zu deployen. Beispielsweise kann die Registrierung in einem Microservice realisiert sein, während die Suche oder der Bestellprozess in anderen Microservices umgesetzt sind. Das erleichtert Continuous Delivery erheblich: Sowohl das Deployment selber als auch das Testen wird wesentlich einfacher, weil die Einheiten dafür kleiner sind. Eine Änderung an der Registrierung erfordert nur ein Deployment und ein Test des Registrierung-Microservices. Maßnahmen wie ein Blue/Green Deployment sind dann natürlich auch einfacher umzusetzen. Ebenso sinkt das Risiko: Ein Fehler in dem Microservice oder ein Ausfall, wie er ja bei einem Deployment vorkommen kann, bedeutet nur, dass die Registrierung nicht mehr zur Verfügung steht. Der Rest des Systems ist davon nicht beeinflusst.
Die Einführung von Continuous Delivery kann auch mit einer Änderung der Architektur kombiniert werden. So kann beispielsweise die Registrierung als Microservice aus dem Deployment Monolithen herausgelöst werden, um so Continuous Delivery in diesem Bereich zu ermöglichen. Das kann insbesondere sinnvoll sein, wenn dieser Bereich absehbar ein Änderungsschwerpunkt sein wird. Das einfachere Deployment eines Microservice wird sich dann sicher eher kurzfristig als langfristig lohnen.
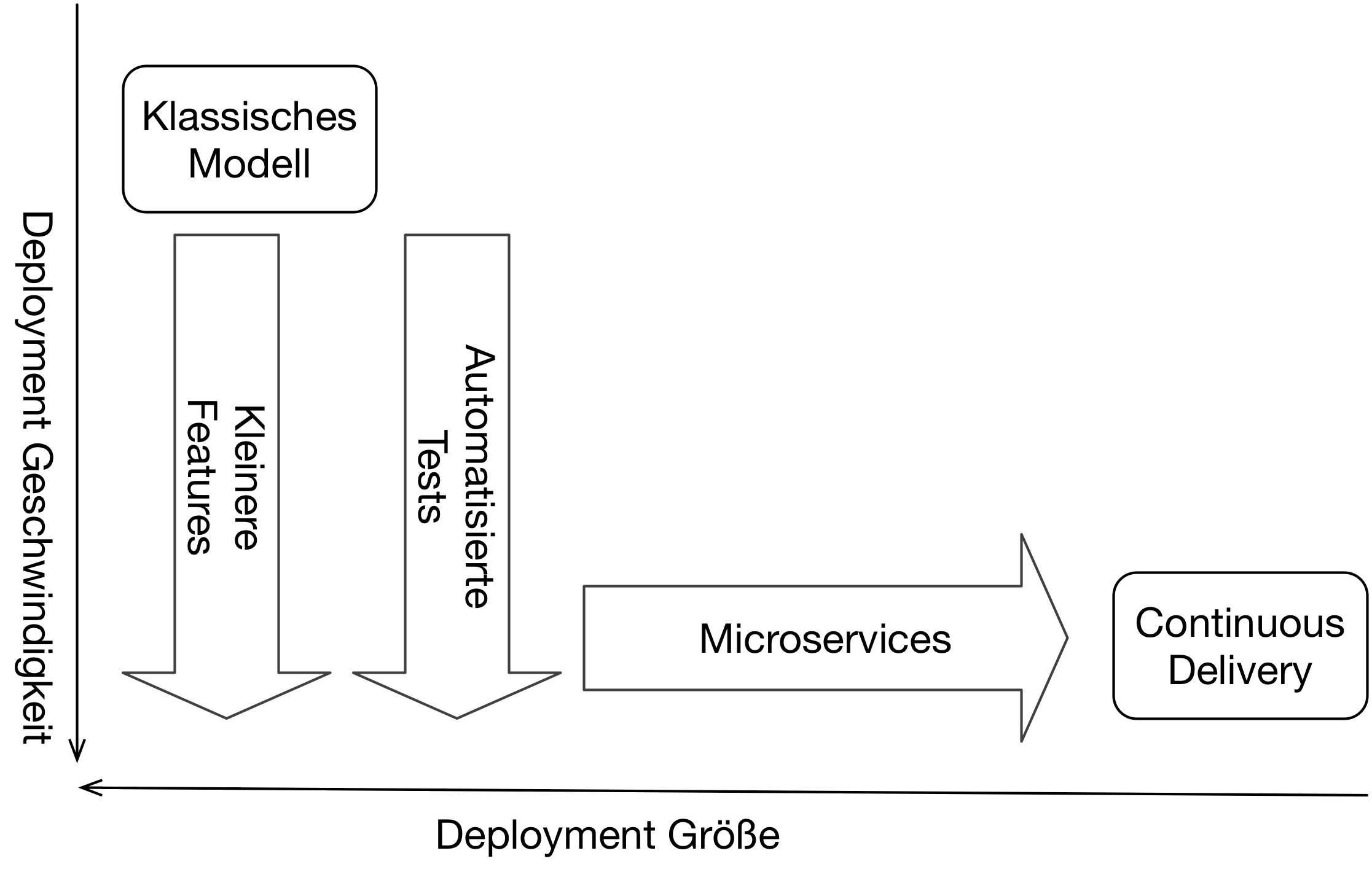
Mit anderen Worten: Beim Einführen von Continuous Delivery sollte auch erwogen werden, die Architektur anzupassen. Continuous Delivery kann man nur dann gewährleisten, wenn die Kunden bei kleineren Features mitziehen, das Deployment automatisiert ist und die Architektur darauf ausgerichtet ist (Abb. 2). Ein Deployment Monolith, bei dem die Planung auf Quartalsreleases basiert, ist nur schwer mit einem Continuous-Delivery-Prozess auslieferbar. Und selbst dann wird Continuous Delivery nicht den vollen Nutzen bringen.
Wie Infrastruktur automatisieren?
Die Automatisierung von Infrastruktur-Installation und Software-Deployment ist ein zentraler Bereich von Continuous Delivery. Dafür ist eine Kombination von Skills notwendig: Software-Entwicklung-Skills, weil es um die Entwicklung von Software zur Automatisierung von Deployments geht, und Betriebsskills, weil Wissen über Installation und Betriebssysteme notwendig ist. Eigentlich ist dafür DevOps als Kollaboration zwischen Entwicklung (Dev) und Betrieb (Ops) sinnvoll. In der Praxis scheint sich jedoch häufig ein anderer Ansatz durchzusetzen: Die Entwicklung übernimmt den Betrieb. Ein Anzeichen ist der Erfolg von Docker bei Entwicklern. Vor einigen Jahren wäre wohl kaum jemand auf die Idee gekommen, auf einer Entwickler-Konferenz einen Vortrag über die Möglichkeiten zur Isolation von Linux-Prozessen und Linux-Filesystemen überhaupt einzureichen. Genau dieses Thema ist aber durch Docker ein wesentlicher Hype. Also bauen Entwickler gerade Betriebs-Skills auf.
Neue Fähigkeiten sind immer eine gute Sache. Aber es ist ein Symptom dafür, dass die Entwicklung die Aufgaben des Betriebs übernimmt – und eigentlich sollte der Betrieb dazu besser aufgestellt sein.
Die Gründe dafür sind vielfältig: Der Betrieb ist kostenoptimiert und nicht darauf ausgerichtet, die Entwicklung optimal zu unterstützen. Es ist egal, wenn die Installation einer Datenbank sich über einen Monat hinzieht und das Entwicklungsteam dazu mehrere verschiedene Betriebseinheiten koordinieren muss. In einer solchen Umgebung ist Continuous Delivery schwer vorstellbar. Durch Continuous Delivery muss Software öfter in Produktion gebracht werden und dazu muss Infrastruktur wie Datenbanken schnell zur Verfügung stehen. Werden Microservices zur Unterstützung von Continuous Delivery genutzt, erhöht sich die Anzahl der zu deployenden Anwendungen und damit die Anzahl der Server, die installiert, gewartet und überwacht werden müssen. Das bedeutet mehr Aufwand für den Betrieb. Dem steht der Betrieb oft nicht aufgeschlossen gegenüber.
Auch hier gibt es also wieder ein soziales Problem: Betrieb und Entwicklung müssten kollaborieren – tun es aber nicht. Das führt dazu, dass Entwickler diese Aufgaben übernehmen. Leider bleibt dabei das Potential der Betriebsexperten ungenutzt. Aber so ist immerhin gewährleistet, dass die notwendigen Neuerungen im Betrieb tatsächlich umgesetzt werden.
PaaS als sozialer Hack
Um mit den Herausforderungen im Betrieb umzugehen, gibt es auch eine technische Lösung: Man installiert ein PaaS wie Cloud Foundry [6] oder OpenShift [7]. Die Betriebsorganisation kann das System installieren. Auch wenn PaaS komplex sind: Es ist nicht weiter problematisch, wenn die Installation etwas länger dauert. Denn danach steht ein System bereit, mit dem Entwickler neue Anwendungen ohne größeren Aufwand in Produktion bringen können. Wenn also das PaaS einmal installiert ist, muss der Betrieb sich am Ausrollen individueller Anwendungen nicht mehr beteiligen. Dadurch ist eine Installation oder ein Update einzelner Anwendungen sehr einfach möglich. Das gilt auch für Lösungen, die auf Docker Container setzten, wie beispielsweise Kubernetes [8]. Der Vorteil eines PaaS ist, dass mehr Infrastruktur angeboten wird. Entwickler müssen keine Docker Images erstellen, sondern sie können Anwendungen, die beispielsweise in Java geschrieben sind, anliefern. Der Betrieb behält auch die Kontrolle über die genutzte Linux-Version und kann so Sicherheitspatches oder ähnliches einspielen. PaaS bieten oft auch weitere Features wie die Verwaltung von Log-Dateien, Monitoring oder Datenbanken.
Bis zu einem gewissen Maße lassen sich so also die organisatorischen Herausforderungen insbesondere bei der Kollaboration zwischen Betrieb und Entwicklung beheben. Eigentlich ist es keine gute Idee, ein organisatorisches Problem mit einer Technologie zu lösen. So werden Symptome behandelt, aber nicht das zugrundeliegende Problem gelöst. In diesem speziellen Fall erscheint die Installation eines PaaS aber oft die einzige pragmatische Lösung zu sein, um Release-Zyklen entscheidend zu beschleunigen.
Fazit
Die Einführung von Continuous Delivery birgt einige technische Herausforderungen: Die Installation von Software muss automatisiert werden. Oft scheint Continuous Delivery sogar ein Synonym für die Automatisierung von Software-Installation zu sein. Wesentliche Herausforderung ist aber das automatisierte und zuverlässige Testen der Software. Zwar müssen dafür auch technologische Lösungen gefunden werden, aber die größere Herausforderung ist es, dass Kunden tatsächlich den Ergebnissen der automatisierten Tests vertrauen und keine manuellen Tests mehr vornimmt, bevor die Software in Produktion geht. Dadurch können Release-Zyklen erheblich reduziert werden.
Ebenso müssen Kunden in kleineren Iteration denken, um den vollen Nutzen von Continuous Delivery zu erreichen – und nicht zuletzt sollte die Architektur der Software so angepasst werden, dass kleinere Einheiten deployt werden können. Dazu können Microservices nützlich sein.
Eigentlich sollte Continuous Delivery in einer engen Abstimmung zwischen Betrieb und Entwicklung umgesetzt werden. Das ist in der Praxis schwierig: Der Betrieb kann oft nicht ausreichend unterstützten. Daher übernimmt die Entwicklung oft Aufgaben des Betriebs. So wird das Wissen des Betriebs leider nicht genutzt – aber immerhin kommt es überhaupt zu Besserungen.
Ein PaaS kann die Installation von Software in Produktion erheblich vereinfachen. Nicht nur weil es technisch einfacher ist, sondern auch weil so der Betrieb nicht bei jedem Release beteiligt werden muss. So kann das organisatorische Problem mit einer Technologie gelöst werden.
Wie bei sehr vielen Änderungsinitiativen geht es auch bei Continuous Delivery am Ende um eine organisatorische Änderung – und solche Vorhaben sind aufwändig und komplex. Erst danach kann man von den technischen Innovationen voll profitieren.
Literatur & Links
-
Eberhard Wolff: Continuous Delivery: Der pragmatische Einstieg, 2. Auflage, dpunkt, 2016, ISBN 978–3864903717 ↩︎
-
http://ai.stanford.edu/~ronnyk/ExPThinkWeek2009Public.pdf ↩︎
-
Eberhard Wolff: Microservices: Grundlagen flexibler Software Architekturen, dpunkt, 2015, ISBN 978–3864903137 ↩︎