
In einem Cluster, der durch Kubernetes verwaltet wird, darf eine Persistenz aber keine Abhängigkeit zu einem bestimmten Knoten (sei es eine VM oder Hardware) hinzufügen. Macht sie das dennoch, hat Kubernetes (und damit sein Scheduler) nicht mehr die Freiheiten, die benötigt werden, um wichtige “Nicht Funktionale Anforderungen” (NFR) wie hohe Verfügbarkeit, dynamische Skalierung, Health Checks, Re-Placement etc. sicher zu stellen. Zum Beispiel kann der Scheduler bei Ausfall von Knoten (z.B. während automatischer Kernel Updates) die Container nicht mehr einfach auf einem anderen Knoten neu starten.
In diesem ersten Teil des Artikels gibt es zunächst einen Vergleich der prinzipiellen Varianten, mit denen eine Persistenz bei gängigen Cloud Providern oder auch Bare Metal realisiert werden kann.
Massenspeicher
Storage Area Networks (SANs), Network Attached Storage (NAS) und Dateisysteme wie NFS gibt es schon eine ganze Weile.
Fast ebenso lange gibt es verschiedenste Dienste der Cloud-Anbieter. Sie bieten unter anderem:
- Skalierbare lokale Platten oder SSD pro VM
- Zahlreiche Dienste zur Speicherung von Daten (Block oder Object Storage wie AWS S3/EBS, Azure Disk Volume, …)
- Managed Services für beispielsweise Datenbanken (AWS RDS)
Das sieht eigentlich nach brauchbaren Lösungen aus. Dennoch bleiben einige Fragen offen:
- Bei bestimmten horizontal zu skalierenden Anwendungen ist es notwendig, direkten Zugriff auf ein Filesystem zu haben. Was ist also, wenn ein Filesystem benötigt wird, dass sich über mehrere Knoten erstreckt?
- Wenn wir ein eigenes NAS implementieren, wo befinden sich dann seine Daten?
- Wenn wir unsere stateful Anwendungen dynamisch skalieren wollen, wer erzeugt die Instanzen und wer provisioniert die dann notwendigen zusätzlichen Volumes?
- Was ist, wenn unser Cloud-Anbieter nur Local Storage anbietet?
- Was ist mit Bare-Metal-Installationen?
- Welche Unterstützung dafür bietet Kubernetes?
Strategien für zustandsbehaftete Applikationen
Generell erhöhen wir die Verfügbarkeit durch Replikation von Daten. Bei drei Knoten, die jeweils 99,95% garantierte Verfügbarkeit haben, kommt man bei dreifach redundanter Auslegung auf 99,9998%. Das heißt: die maximale Ausfallzeit von ca. 4.5 Stunden reduziert sich auf nur noch geringe 12 Minuten.
Natürlich lässt sich Verfügbarkeit nicht so trivial buchhalterisch berechnen. Es müssen alle Komponenten eines Systems beachtet werden. Gewisse Hardware-Komponenten werden gemeinsam verwendet, ebenso muss man auf Fehler der eigenen Software und der verwendeten Produkte achten. Überschlägig kann man aber gut erkennen, welche signifikante Auswirkung Redundanz auf die Verfügbarkeit hat.
Eine solche Replikation von Daten können wir generell über die Verwendung entsprechender Produkte wie MongoDB, Postgresql, Kafka etc. erreichen. Mit allen kann sichergestellt werden, dass pro Instanz auch eine Replika der Daten vorliegt. Die Frage, die sich hier stellt, ist aber: Wo werden die Daten gespeichert?
Stellt ein Cloud-Anbieter Block-Storage-Dienste bereit, die die notwendige Verfügbarkeit garantieren, ist eine mögliche Lösung schon gefunden. Fehlen solche Dienste, so ist eine VM-lokale SSD oder ein Container Native Storage (Cluster Filesystem) ein ebenso möglicher Weg.
Ein wichtiges Kriterium ist aber, dass containerisierte Anwendungen in Produktion einige spezifische Anforderungen haben. Wie bereits beschrieben, kann Kubernetes die Einhaltung einiger wichtiger NFRs sicherstellen. Bezogen auf persistente Daten heißt das: das Volume (Datenträger) einer Containerinstanz sollte dynamisch erzeugt werden können und muss auf jedem Knoten des Clusters stabil zur Verfügung stehen.
Managed Services
Cloud-Anbieter wie Amazon bieten fertige Dienste (managed services) für relationale oder NoSQL-Datenbanken, Messaging Systeme, BigData und vieles mehr an. Mitentscheidend ist hier, ob ein solches, zumeist im Ausland sitzendes Unternehmen für das eigene Projekt in Frage kommt und ob der erhöhte Vendor Lock-In ein Problem darstellt.
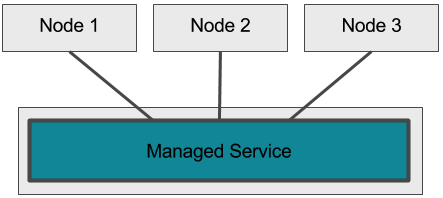
Pro:
- Das in “In-Produktion-bringen” ist sehr einfach
- Die Verantwortung für Verfügbarkeit, Skalierung etc. liegt beim Cloud-Anbieter
Con:
- Angebotene Dienste müssen zur Anwendung passen (nach Möglichkeit auch für zukünftige Änderungen der Anforderungen)
- Es herrscht erhöhter Vendor Lock-In, je nachdem, ob Standardprodukte angeboten werden oder anbieterspezifische APIs verwendet werden müssen
Nutzung der Lokalen Persistenz
Die Nutzung einer lokalen SSD über eine VM oder auch über Bare Metal ist die einfachste und klassische Methode, Daten zu persistieren. Allerdings befinden sich alle Daten dann nur auf einem spezifischen Knoten. Verschiedene Anforderungen eines Container Managers können also nicht befriedigt werden. StatefulSets von Kubernetes, beispielsweise, werden so überhaupt nicht funktionieren.
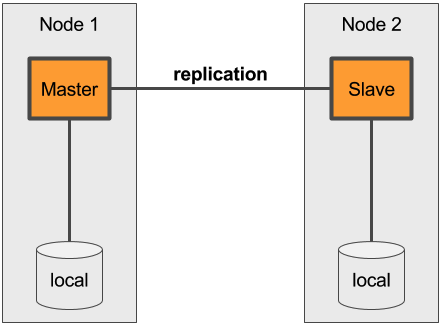
Pro:
- Die Performance ist meist sehr gut
- Die Umsetzung ist einfach zu verstehen und zu realisieren
- Replikation wird durch eine Vielzahl von Produkten unterstützt
- Durch die klassische Nutzung werden wenig Probleme bei IO Zugriffen oder Dateiberechtigungen auftreten. Ebenso sind, im Gegensatz zu verteilten Dateisystemen, keine speziellen Optimierungen notwendig
Con:
- Dieses Vorgehen Ignoriert die Anforderungen eines Container Managers
- Container und deren Daten sind an spezifische Knoten gebunden
- Replikation ist bei jedem Tool unterschiedlich zu konfigurieren
- Es sind keine shared volumes möglich (distributed file locks etc.)
- Meistens nur sehr begrenzt skalierbar
- Manche Anbieter löschen alle Daten bei einem Stop der VM-Instanz
Managed Block Storage Services
Alle üblichen Cloud-Anbieter bieten in irgendeiner Form Block- oder Object-Storage-Dienste an. Solche Dienste können auf die Knoten und weiter in die Container gemountet werden. Im Fall von Kubernetes erfolgt das automatisch. Es stellt auch sicher, dass ein Volume mit dem “eigenen” Container zu einem anderen Knoten wandert, sollte das notwendig sein.
Es sollte auch nicht vergessen werden, dass hinter solchen Diensten immer ein komplexes Storage-System steckt. Die maximal verfügbaren IO Operations liegen signifikant unter denen einer lokalen SSD.
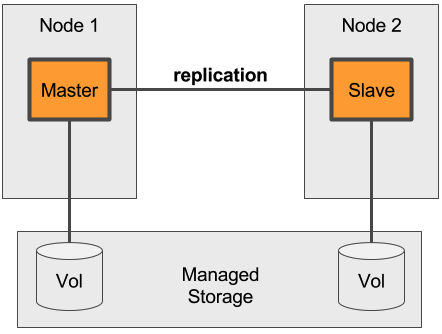
Pro:
- Block Storage ist nicht an bestimmte Knoten gebunden
- Die Verantwortung für die Verfügbarkeit liegt beim Cloud-Anbieter
- Unterschiedliche Volumes für z. B. Fotos (viel Kapazität, aber mit niedrigen Kosten) oder DBs (schnell, höhere Kosten) sind möglich
- Die Größe ist skalierbar
- Diese Dienste sind als querschnittlich/gemeinsam genutztes Volumes verwendbar (nicht bei allen Diensten möglich)
- Als dynamisch provisioniertes Volume nutzbar
Con:
- Maximale erreichbare IO Operations könnten unzureichend sein. Maßnahmen dagegen können aufwändig oder teuer sein
- Es besteht erhöhter Vendor Lock-In, weil sich die Charakteristik des Zugriffs (read write many, IP Operations) zwischen den Anbietern unterscheiden kann
Verteilte Dateisysteme
Werden Cluster File-Systeme (verteilte File-Systeme) durch Container verwendet, spricht man auch von einem Cloud Native Container Storage. Charakteristisch für solche Systeme im Umfeld Kubernetes ist:
- Sie werden, wie andere Elemente der Applikation, im Cluster deployt und durch den Container Manager verwaltet (das kann klassisch durch DaemonSets o.ä. erfolgen oder aber auch durch das Operator Pattern)
- Erstellte Volumes sind auf allen Knoten des Cluster zugreifbar
- Ein Volume kann ggf. in mehreren Containern verwendet werden
- Volumes lassen sich dynamisch provisionieren (z.B. durch ein Volume Plugin und das Attribut StorageClass des VolumeClaimTemplate eines StatefulSets)
- Widerstandsfähigkeit und Verfügbarkeit wird durch Datenreplikation innerhalb des verteilten Dateisystems sichergestellt
- Weitere per-volume-features, wie flexible Quotas, flexible Replikas, Distribution, Striping oder Kombinationen davon, können verwendet werden (je nach verwendetem Produkt)
Interessante Kandidaten sind derzeit:
Nutzung Lokaler Persistenz
Im Gegensatz zur direkten Nutzung lokalen SSDs kann ein Cluster FS eine ausreichende Grundlage zur Verwendung eines Container Managers legen. Hat man nur lokal Storage zur Verfügung ist das, neben dem Aufsetzen eines eigenen SAN, der einzig sinnvolle Weg.
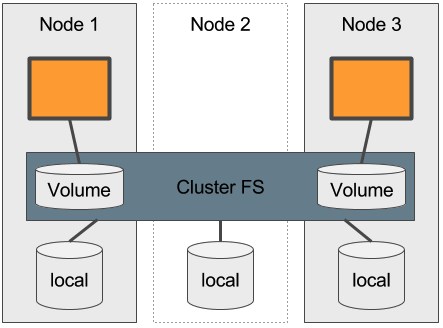
Pro:
- Gut für Bare-Metal-Installationen oder für Cloud-Anbieter ohne zusätzliche “höher wertige” Serviceangebote
- Widerstandsfähigkeit und Verfügbarkeit über das verteilte Dateisystem
- Dynamische Verteilung der Daten über den gesamten verfügbaren Plattenspeicher des Clusters
- Hohe Performance, eventuell durch Striping noch steigerbar
Con:
- Komplexität eines verteilten Dateisystems
- Wegfall eines Knotens reduziert den Speicherplatz entsprechend
Nutzung Managed Block Storage Services
Natürlich kann man statt lokaler SSDs auch den Managed Storage des Cloud-Anbieters verwenden. Ob sich der Aufwand eines solchen weiteren Layers allerdings lohnt, muss im Detail geklärt werden, kann aber durchaus Vorteile bringen.
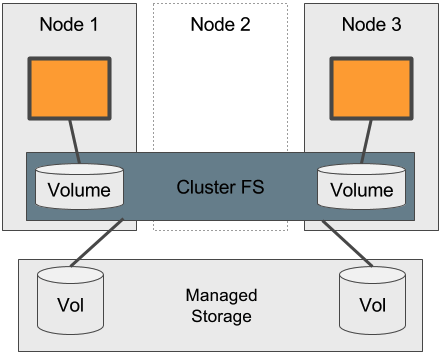
Pro:
- Bei zu wenig verfügbaren IO Operations können Zugriffe über alle managed Volumes verteilt werden (Striping)
- Zusätzlicher Abstraktions-Layer sorgt für geringeren Vendor Lock-In
- Managed Volumes sind unterschiedlich zu den Container Volumes administrierbar
- Verfügbarkeit über das verteilte Dateisystem und über den Cloud-Anbieter
Con:
- Komplexität eines verteilten Dateisystems
Fazit
Mit den hier genannten Möglichkeiten, persistente Daten zu verwalten, lassen sich die meisten Anwendungsfälle wie Cloud Provider, Bare Metal, verschiedene Zugriffsszenarien etc. abdecken. Besonders die Systeme zur Container Native Storage erhöhen die Flexibilität und bieten dazu noch einige sehr sinnvolle Dinge wie Quotas oder Striping. Dennoch: obwohl ihre Anwendung recht leicht verständlich ist, darf ihre Komplexität nicht unterschätzt werden. Wer sich davor nicht scheut, sollte aber einen näheren Blick darauf werfen.
Im zweiten Teil dieses Posts werde ich näher auf die Unterstützung durch Kubernetes eingehen.