
Passwords, pass phrases and secret keys may not have existed since humans roamed the earth and hunted mammoths, but we can find recorded references to secrets and cyphers ranging back 2500 years to the Greek and Persian empires. The Romans used a “watchword” for guard duty – in computer science it has existed since the beginning of multi-user systems like the MITs CTSS, which was released 1961 and required you to log in. Although Bill proclaimed the “Death of the password” 2004, I’m pretty sure we will be stuck with them for a good while. Besides, authentication methods of the future still have their own problems:
Geordi,
— Worf Email (@WorfEmail) March 7, 2018
Is there a way to enter our authorization codes by typing them instead of speaking aloud to the computer? Several crew members have complained that they need to memorize a new code after each use because coworkers overheard them.
Worf
An dieser Stelle möchten wir Dir gerne einen Tweet anzeigen. Um ihn zu sehen, musst Du dem Laden von Fremdinhalten von twitter.com zustimmen.
If you rely on password-based authentication, the security of your system will depend on strong passwords. The big breaches and hacks often don’t just use a single zero-day exploit to get into a system, it’s a lot of these tiny details, (un)luckily chained together. It’s the broken account of that one unprivileged user (or educational system) which opens the possibility for the attacker to dig deeper into the network. Even with technologies like SSO, there is always that local backup user to log in, in case the SSO or directory service is unavailable. Therefore it is important to enforce strong passwords.
Over the years, some things have changed. The net has grown and user databases tend to grow really big, at least in centralized services: think Twitter, Google, Facebook etc. They also offer a large attack surface and the effects of a breach are huge. Adobe’s data breach affected 38 million users. Hopefully, the times of storing passwords in plain text are over, but salting a password hash is not as common as it should be. These stolen database dumps tend to be freely available after a while and lead to much more sophisticated and realistic dictionaries for attacking. This brings us to the question: What is a strong password?
Since xkcd #936 we all know it is “CorrectHorseBatteryStaple”:

See the explain xkcd wiki for an in-depth explanation.
To clarify: A really long simple password (or pass phrase) is better than a short complex password. A long complex password is better than long simple password. So in an ideal world, we simply require 40-character long auto-generated passwords. Problem solved.
We all know that reality looks a little different and in many projects there are many more considerations in play than my own views on things. However, this must never, ever lead you to implement an insecure system, no matter what – but often there is an acceptable compromise. For password rules, people tend to implement something like the following regular expression:
/(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[@#$%!])(?=\\S+$).{8,256}$/This means something like at least 8 characters, lower-/uppercase letters, a
number and a special character. At first glance, this looks like a good solution.
But this will not actually enforce a good password. Here is an example:
P@ssw0rd will match the regex but will definitely be included in every
common dictionary. Previously breached databases are full of millions of clever ideas
which exactly circumvent the idea behind these rules, refined over years by
millions of users.
So what is a good way to check for secure passwords? The good news is, we are not the only ones with this kind of problem and to some degree others have already solved this. There are dozens of different libraries which can check the strength of a password, including l33t speak, keyboard patterns, and so on. An excellent example is the zxcvbn library, written by Daniel Lowe Wheeler at Dropbox. If you can find the time, also watch his Usenix conference talk “zxcvbn: Low-Budget Password Strength Estimation”.
If we look further into this, we shouldn’t make any assumptions by ourselves, but base our assessment on commonly accepted guidelines. NIST’s Special Publication 800–63 is one such guideline. The interesting part is inside the chapter “Authentication and Lifecycle Management”, Section 5 “Authenticator and Verifier Requirements”:
When processing requests to establish and change memorized secrets, verifiers SHALL compare the prospective secrets against a list that contains values known to be commonly-used, expected, or compromised. For example, the list MAY include, but is not limited to:
- Passwords obtained from previous breach corpuses.
- Dictionary words.
- Repetitive or sequential characters (e.g. ‘aaaaaa’, ‘1234abcd’).
- Context-specific words, such as the name of the service, the username, and derivatives thereof.
If the chosen secret is found in the list, the CSP or verifier SHALL advise the subscriber that they need to select a different secret, SHALL provide the reason for rejection, and SHALL require the subscriber to choose a different value.
If the dictionary of “previous breach corpuses” is large enough, this may be the most efficient way to check for unsafe passwords. Troy Hunt did an excellent job in collecting these breaches and has been running https://haveibeenpwned.com/ for a while now. You can check if your e-mail address was part of a prior breach. Additionally, he is also offering a possibility to check if a password is inside one of the breaches: https://haveibeenpwned.com/Passwords This is not the interesting part. Of course, you don’t want to ever enter your own passwords on a foreign website on the internet. The interesting part is that Troy offers an API service which lets you check in a nearly secure way whether a new password is included inside a data breach. My colleague Michael Krämer wrote a short how-to: „Have YOU been pwned?”. Hint: The keyword for this is range requests. The data Troy is using consists of 501+ million passwords, this may be one of the largest and highest-quality dictionaries you can get.
It still might not be possible for you to use the API service. There are several reasons for this, like the required connection to the web, some kind of overhead or complexity this introduces, or simply the fact that it is strictly forbidden by company guidelines to use something like that. The good thing is, Troy made the whole dictionary available for download. You can get it via torrent or hosted HTTP download. The uncompressed file is 30 GB in size and contains the passwords as SHA-1 hashes. To use this, you take any password you want to check, hash it and compare the hash to the downloaded dictionary.
Working with 30-gig text files is a problem, so terms like Azure Tables, AWS DynamoDB or Cassandra might pop up in your head. After some yak shaving, the easiest solution for this problem is a binary search through the ordered dictionary file. It can be implemented with a few lines of code and you can build your own local hash-checking service without using Troy’s API.
I’ve done exactly that and published the source code on GitHub: https://github.com/innoq/hashcheck
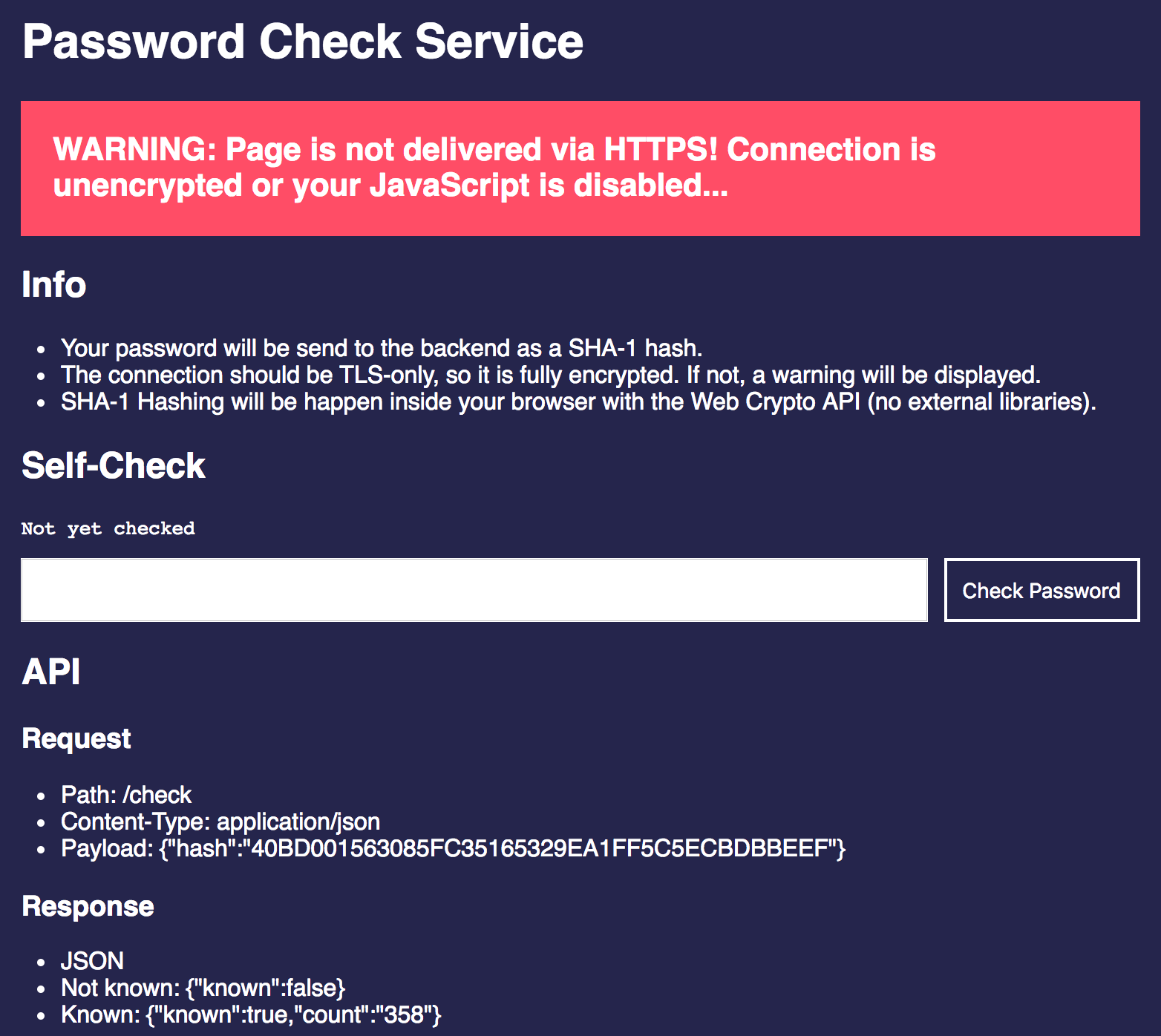
This project contains a really simple Node.js application which has a web front end
for checking the password and a /check API end point. Add the ordered
dictionary and you are ready to go. A Dockerfile to run this in a container is also included.
Build your own, use it as an example or run it directly. If you do so, please, please, please check the source code. Of course, you might trust me, but you should never run this kind of code without having a look first. It doesn’t use any libraries other than Express and body-parser and hashes your password inside the browser with the WebCrypto API. It’s fewer than 100 lines of code, but still: Be careful with that kind of thing.
If you want to do a quick check against the downloaded dictionary on your local
machine, your OS may already provide a tool for that. My colleague Martin
Eigenbrodt pointed me to
look(1) which does a binary search
lookup in a text file. On Linux you may have to supply it with the -b switch.
It looks like “123” is in the dictionary:
λ ~/ look “40BD001563085FC35165329EA1FF5C5ECBDBBEEF” pwned-passwords-ordered-2.0.txt
40BD001563085FC35165329EA1FF5C5ECBDBBEEF:977827So let’s all contribute to safer applications, no matter whether on the internet or within a company intranet.