
Die Ideen von Domain-driven Design wie z.B. die Aufteilung der Verantwortlichkeiten nach fachlichen Gesichtspunkten auf mehrere Bounded Contexts haben sich in vielen Projekten mittlerweile gut etabliert. Dabei beschäftigt sich das Entwicklungsteam intensiv mit den Fachexperten, deren Sicht auf die Fachlichkeit und deren Sprache. Ihr Ziel dabei: das Modell für die Umsetzung soll sich möglichst genau an dieser fachlichen Sicht orientieren, zumindest soweit dies für die Lösung des Problems notwendig und sinnvoll ist.
Für die Ausgestaltung des fachlichen Domänenmodells bietet Domain-driven Design im taktischen Design eine Reihe von „Internal Building Blocks” wie z.B. Value Objects, Aggregates oder Repositories. Auch diese Konstrukte sind mittlerweile in vielen Projekten gut verstanden und werden aktiv in der Modellierung genutzt.
Fachliches Design vs. Framework
Diese „saubere” Modellierung nach fachlichen Aspekten - am Whiteboard, mit Post-Its beim Event Storming oder im Designdokument meist noch gut erreicht - wird ab der eigentlichen Umsetzung in Code und unter Verwendung von konkreten Technologien dann aber oftmals sehr stark herausgefordert. Den meisten wird die Aussage „das muss man mit Framework X eben so abbilden” kaum fremd vorkommen. Als Konsequenz finden wir uns nach einigen Monaten dann in einem System wieder, in welchem wir ob all dem technischen Einfluss unser sorgfältig entworfenes, hinterfragtes und iterativ verbessertes fachliches Modell kaum mehr wiederfinden.
Eine erfolgsversprechende Möglichkeit, dieser Technologiefalle zu entkommen, ist es, Technologie eben gerade nicht an die erste Stelle zu setzen, sondern zuerst auf die möglichst technologieneutrale Umsetzung des Kerns der Fachlichkeit zu fokussieren und so eine starke Trennung zwischen Code, welche für die Umsetzung der Geschäftslogik notwendig ist, von Code, welcher aus technischen oder nicht-funktionalen Gründen notwendig ist, zu erreichen. Bei dieser Trennung geht es nicht primär darum, den technischen Code später mit möglichst wenig Aufwand austauschen zu können, sondern darum, bei der Abbildung des fachlichen Lösungsmodells möglichst wenige technisch bedingte Einschränkungen in Kauf nehmen zu müssen, und dieses Modell im Code möglichst klar und unverfälscht sichtbar machen zu können. Dies kann die Nachhaltigkeit, Lesbarkeit und Wartbarkeit des fachlichen Codes wesentlich erhöhen. Natürlich werden wir schlussendlich viele der wunderbaren Features unseres Lieblingsframeworks verwenden wollen, wie z.B. Persistenz, Transaktionen, Security, Unterstützung für REST, und vieles mehr. Aber an der richtigen Stelle, mit der richtigen Priorität und mit akzeptablem Einfluss auf unseren fachlichen Code.
Onion Architecture
Dieser Ansatz der Trennung bedingt nicht nur ein Umdenken im Fokus und im Vorgehen bei der Umsetzung, sondern auch eine geeignete Applikationsarchitektur, welche die Fachlichkeit ins Zentrum setzt. Genau dies macht die Onion Architecture, welche Jeff Palermo in 2008 in einer Serie von Blog-Posts erstmals beschrieben hat. Sein markiges Motto: „The database is not the center - it is external”.
Weitere Architekturansätze, welche ebenfalls diese Trennung als Ziel haben, sind die Hexagonal Architecture oder die Clean Architecture. Die Onion Architecture beschreibt mit ihrer Analogie einer Zwiebel jedoch sehr bildlich, was die prägenden Eigenschaften dieser Applikationsarchitektur sind.
Fachlichkeit im Zentrum, Technologie am Rand
So baut die Onion Architecture eine Applikation aus einer Menge von konzentrischen Ringen auf - so, wie sich eine durchgeschnittene Zwiebel zeigt, wenn wir auf die Schnittfläche schauen. Abbildung 1 zeigt die typische Darstellung einer Onion Architecture.
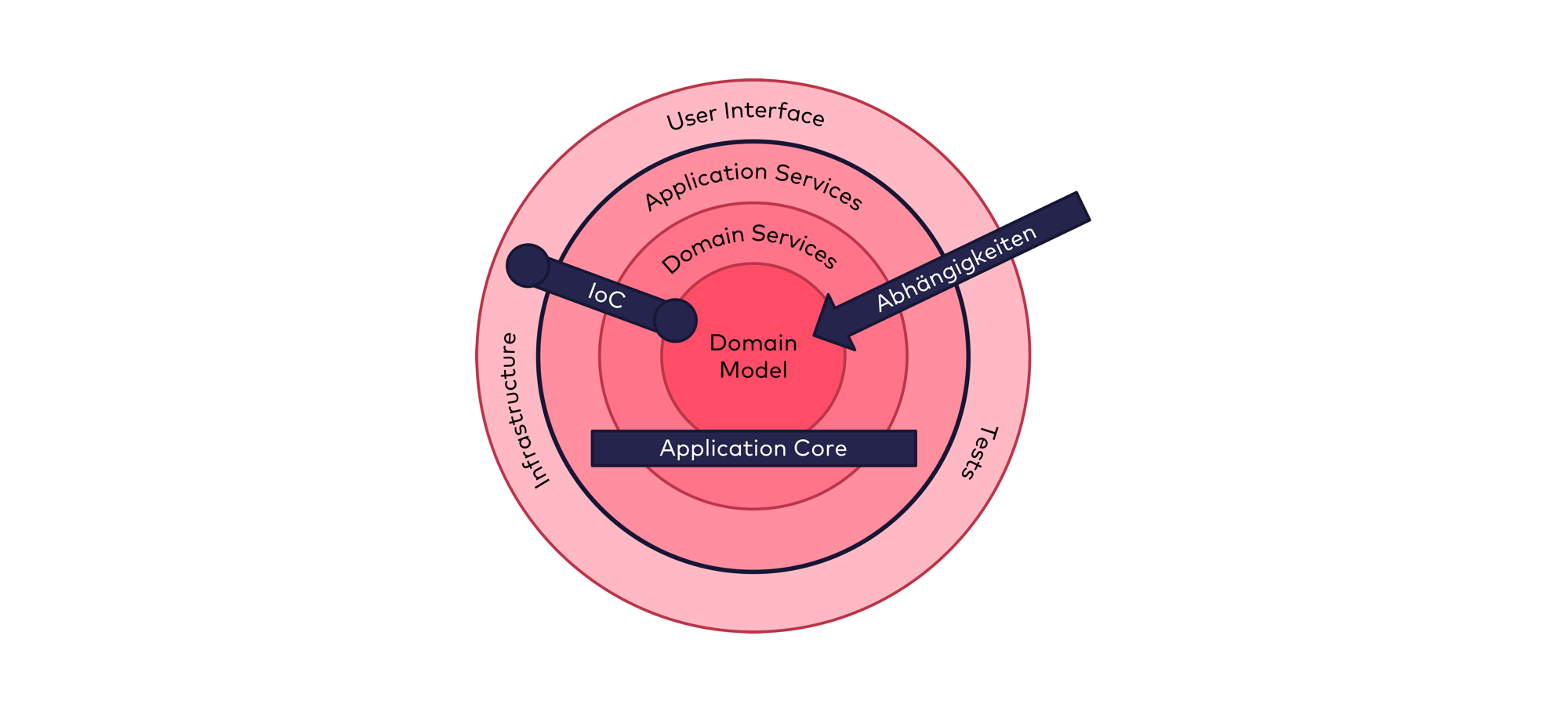
Ganz im Zentrum, im innersten Ring bzw. in der Scheibe „Domain Model”, wird der vorwiegende Teil der Geschäftslogik abgebildet. Dieser Ring beheimatet also nicht nur den Zustand der Applikation, sondern insbesondere auch die fachlichen Regeln und Invarianten. Darum herum folgt der Ring „Domain Services”, welcher Geschäftslogik enthält, welche nicht direkt auf ein einzelnes Element des Domänenmodells passt, weil sich die Geschäftslogik über mehrere Elemente des Domänenmodells erstreckt. Durch diesen Ring wird sichergestellt, dass fachliche Invarianten in äusseren Ringen nicht mehr verletzt werden können. Im nächsten Ring „Application Services” soll sich bereits keine Geschäftslogik mehr befinden, sondern lediglich Code für die Realisierung von konkreten Anwendungsfällen, welche die Geschäftslogik aus den inneren Ringen nutzen.
All diese drei Ringe zusammen werden als „Application Core” bezeichnet - und beschreiben denjenigen Teil des Codes, der von Technologie- und Frameworkeinflüssen frei bleiben soll. Selbstverständlich ist darin die Verwendung eines spezifischen Logging-APIs oder einer Bibliothek mit unveränderbaren Collection-Typen nicht verboten. Vielmehr geht es darum, den fachlich motivierten Code im Application Core nicht mit stark beeinflussenden Technologien aus Frameworks wie Spring, JPA oder Servlet-API zu verschmutzen.
Der äusserste Ring – der «Infrastruktur Ring» - beinhaltet dann den Code für die Anbindung von unterschiedlichen Infrastrukturen wie z.B. Datenbanken, Message Brokers oder Umsystemen, für Web/REST APIs und Benutzerschnittstellen und für Tests, welche die Fachlichkeit aus der Anwendungsfallperspektive testen sollen. Innerhalb dieses äussersten Rings ist die Verwendung von beliebigen Technologien möglich, so wie sie gemäss den konkreten Anforderungen als sinnvoll erscheinen.
Abhängigkeiten: nur von aussen nach innen
Die Onion Architecture schreibt vor, dass Abhängigkeiten zwischen den Ringen nur von aussen nach innen bestehen dürfen. Die Ringe sind dabei jedoch nicht als strikte Layer zu betrachten. Somit ist es durchaus erlaubt, dass Code aus dem Ring „Application Services” eine direkte Abhängigkeit auf Code aus dem Ring „Domain Model” hat.
Durch die Richtung der Abhängigkeit wird somit sichergestellt, dass z.B. das Domänenmodell eben genau keine direkte Abhängigkeit auf Elemente aus der Infrastruktur erhält und so frei von den jeweiligen Technologien der Infrastruktur (wie z.B. JPA) bleibt. Doch wie ist es dann aber überhaupt möglich, dass eine Entität aus dem Ring „Domain Model” in einer Datenbank gespeichert und wieder daraus geladen werden kann? Dazu wird das Konzept von „Inversion of Control” verwendet: das Domain Model definiert mittels einer Schnittstelle die Anforderung, welche durch die Infrastruktur erfüllt werden soll. Die Implementation dieser Schnittstelle ist dann Teil der Infrastruktur, womit die Richtung der Abhängigkeit wiederum eingehalten ist. Erst zur Laufzeit wird die konkret zu verwendende Implementation an Stelle der Schnittstelle zur Verfügung gestellt, typischerweise durch einen Dependency Injection Mechanismus wie z.B. Spring.
An diesem Beispiel zeigt sich auf anschauliche Weise, wie sich die Onion Architecture von einer klassischen N-Tier Architektur unterscheidet: dort findet ich allzu oft eine direkte Abhängigkeit vom Domänenmodell (oder den Entitäten) auf Technologien bzw. Infrastruktur z.B. mittels Verwendung von JPA-Annotationen direkt auf Elementen des Domänenmodells. Abbildung 2 stellt die Ringe bzw. Schichten einer Onion Architecture und einer typischen N-Tier Architektur gegenüber.

Zwiebeln einsetzen
Die Idee einer Zwiebel, welche in ihrem Kern eine konkrete Fachlichkeit abbildet, passt sehr gut auf die Idee der Modularisierung eines Systems in mehrere Bounded Contexts mit jeweils eigenem, auf die spezifische Fachlichkeit optimiertem Domänenmodell aus Domain-driven Design: jeder Bounded Context ist ein natürlicher Kandidat, um als eine separate Zwiebel umgesetzt zu werden. Wird eine Microservice-Architektur verfolgt, sind die Zwiebeln komplett unabhängig voneinander und können bei Bedarf sogar mit unterschiedlichen Technologien realisiert werden. Falls das System als gut strukturierter Monolith (einem „Modulithen”) umgesetzt werden soll, so erstreckt sich oftmals der Infrastruktur-Ring um mehrere Application Cores, wobei sich die einzelnen Application Cores hingegen nicht überschneiden.
Eine Anmerkung aus dem Praxiseinsatz: in konkreten Projekten hat sich bewährt, die Ringe „Domain Model” und „Domain Services” nicht wie von Jeff Palermo ursprünglich beschrieben zu trennen, sondern zu vereinen. Dadurch wird z.B. möglich, dass ein Aggregate aus dem Ring «Domain Model» einen Service aus dem Ring «Domain Services» in Anspruch nehmen kann. Dies ist sinnvoll, weil neben Aggregates auch Domain Services Geschäftslogik enthalten können, die oft von Aggregaten aufgerufen werden soll: ein Aggregate Warenkorb kann so zum Beispiel eine komplexe Preisberechnung basierend nicht nur auf allen Artikeln im Warenkorbs, sondern zusätzlich abhängig vom Wohnort des Kunden, seinem Status im Kundenbindungsprogramm oder der Bestellhistorie über einen Domain Service nutzen.
Die Ringe der Onion Architecture zeigen sich auch im Code, vornehmlich in der Package-Struktur des Projektes. Auch wenn es hier eine ganze Reihe von Optionen für die Abbildung gibt, hat sich in mehreren Projekten folgende Struktur bewährt:
- ein Package für den Bounded Context (die ganze Zwiebel)
- ein Package „domain” für die beiden Ringe „Domain Model” und „Domain Services”, darin bei Bedarf weitere Subpackages nach fachlichen Aspekten geschnitten und mit Namen aus der Ubiquitous Language des Bounded Contexts bezeichnet
- ein Package „application” für den Ring „Application Services”, meist ohne weitere Subpackages
- ein Package „infrastructure” für den Infrastruktur-Ring, typischerweise geschnitten nach technischen Aspekten wie z.B. „persistence”, „web”, „api”, „messaging”, …
Abbildung 3 zeigt ein konkretes Beispiel aus einem Projekt.

Konstruktives Schubladendenken
Dank der Onion Architecture haben wir nun einen konzeptionellen Rahmen für die Strukturierung und Umsetzung unserer Applikation erhalten. Noch ist damit aber nicht gesagt, welche Elemente unseres Lösungsmodells (also welcher „Internal Building Block”) nun in welchem Ring abgebildet wird, und auf welche Weise. Und wir haben noch nicht geklärt, wie wir technische Funktionalitäten wie Persistenz oder Transaktionen nutzen können, ohne dabei durch Infrastruktur und Technologie unser Domänenmodell wieder zu verschmutzen. Genau hier helfen uns Stereotypen.
Stereotypen als Konzept besitzen einen prägnanten Namen und eine zugehörige, definierte Semantik. Der Name dient dabei als Platzhalter für die Semantik. Wird nun ein Stereotyp von einer Instanz über seinen Namen benutzt, so färbt sich dessen Semantik auf die Instanz ab. Abbildung 4 stellt dieses Konzept dar.

Durch die Verwendung des Stereotyps als „Auszeichner” für eine konkrete Instanz weisen wir dieser Instanz bereits eine ganze Menge von Eigenschaften und Bedeutung zu. Was ursprünglich in der Psychologie benutzt wurde, um Menschen in Schubladen einzuteilen (z.B. «Peter ist ein Choleriker»), kann in der Umsetzung von Applikationen wesentlich konstruktiver genutzt werden, gerade in Verbindung mit dem taktischen Design von Domain-driven Design: wenn wir ausgehend von den „Internal Building Blocks” die für uns relevanten Elemente als Stereotypen definieren, können wir diese Stereotypen innerhalb der Ringe der Onion Architecture verorten und in unserem Code der Applikation verwenden. Die Idee dieser Durchgängigkeit vom Konzept aus Domain-driven Design bis in den Code der Applikationsarchitektur ist in Abbildung 5 dargestellt.
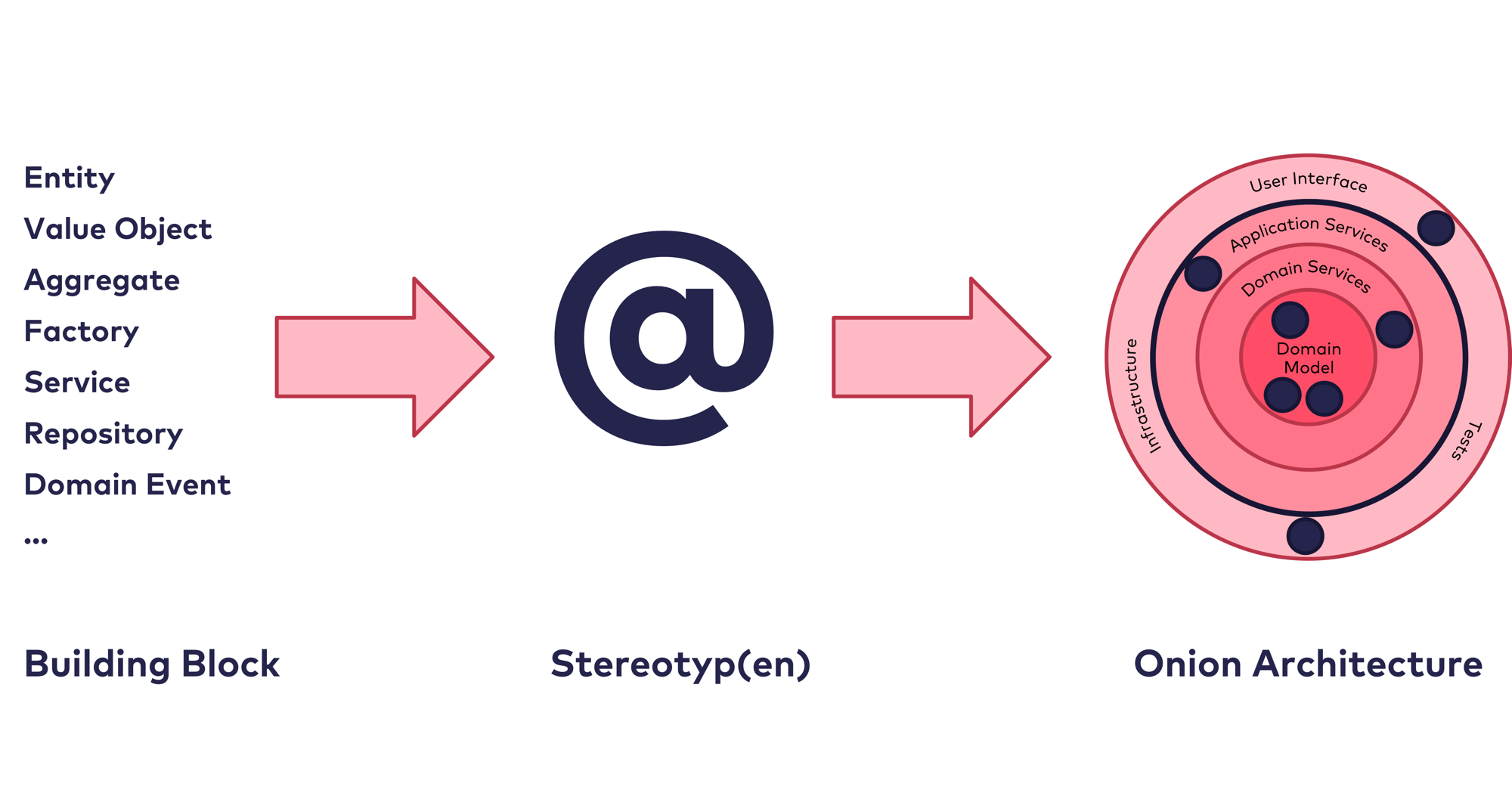
Definieren wird also z.B. einen Stereotypen „Aggregate” entsprechend dem Aggregate aus Domain-driven Design, so können wir ein konkretes Aggregate „Buchung” damit auszeichnen und somit die Semantik des Stereotyps „Aggregate” auf das konkrete Aggregate abfärben lassen. Wenn wir nun verstanden haben, was ein Aggregate ist und wissen, dass eine Buchung ein Aggregate ist, dann wissen wir bereits einiges über Bedeutung und Eigenschaften der Buchung.
Um Stereotypen im Code verwenden zu können, müssen diese entsprechend in der Programmiersprache ausgedrückt werden können. Bezogen auf Java bieten sich unterschiedliche Optionen wie reine Namenskonventionen über Klassennamen, abstrakte Basisklassen oder Interfaces, oder Annotationen. In der Praxis hat sich die Umsetzung als Annotation sehr bewährt, da Annotationen in Java für genau den Zweck der zusätzlichen „Auszeichnung” von Elementen im Code eingeführt worden sind, keine Verschmutzung der Namen oder Typhierarchie des ausgezeichneten Elements verursachen und zudem nicht nur auf Klassen, sondern bei Bedarf z.B. auch auf Methoden, Feldern oder Packages verwendet werden können. Abbildung 6 zeigt dies an einem vereinfachten Beispiel.

Was jetzt vielleicht als blosse Spielerei aussehen mag, hat in der Praxis eine ganze Reihe von handfesten Vorteilen:
Über die abgeschlossene Gesamtmenge aller Stereotypen, welche innerhalb unserer Architektur definiert sind, beschreiben wir eine Art „Architektursprache”, welche von allen Beteiligten im Team verstanden und in Design-Diskussionen verwendet werden kann.
Für jeden Stereotypen kann definiert werden, in welchem Ring der Onion Architecture Elemente mit diesem Stereotypen angesiedelt sind. So kann z.B. definiert werden, dass Elemente vom Stereotyp „Aggregate” innerhalb des Rings „Domain Model” liegen müssen, da Aggregate primär Geschäftslogik enthalten, welche im Ring „Domain Model” abgebildet sein soll. Abbildung 7 zeigt eine praxisbewährte Platzierung von gängigen Stereotypen auf die Ringe der Onion Architecture.
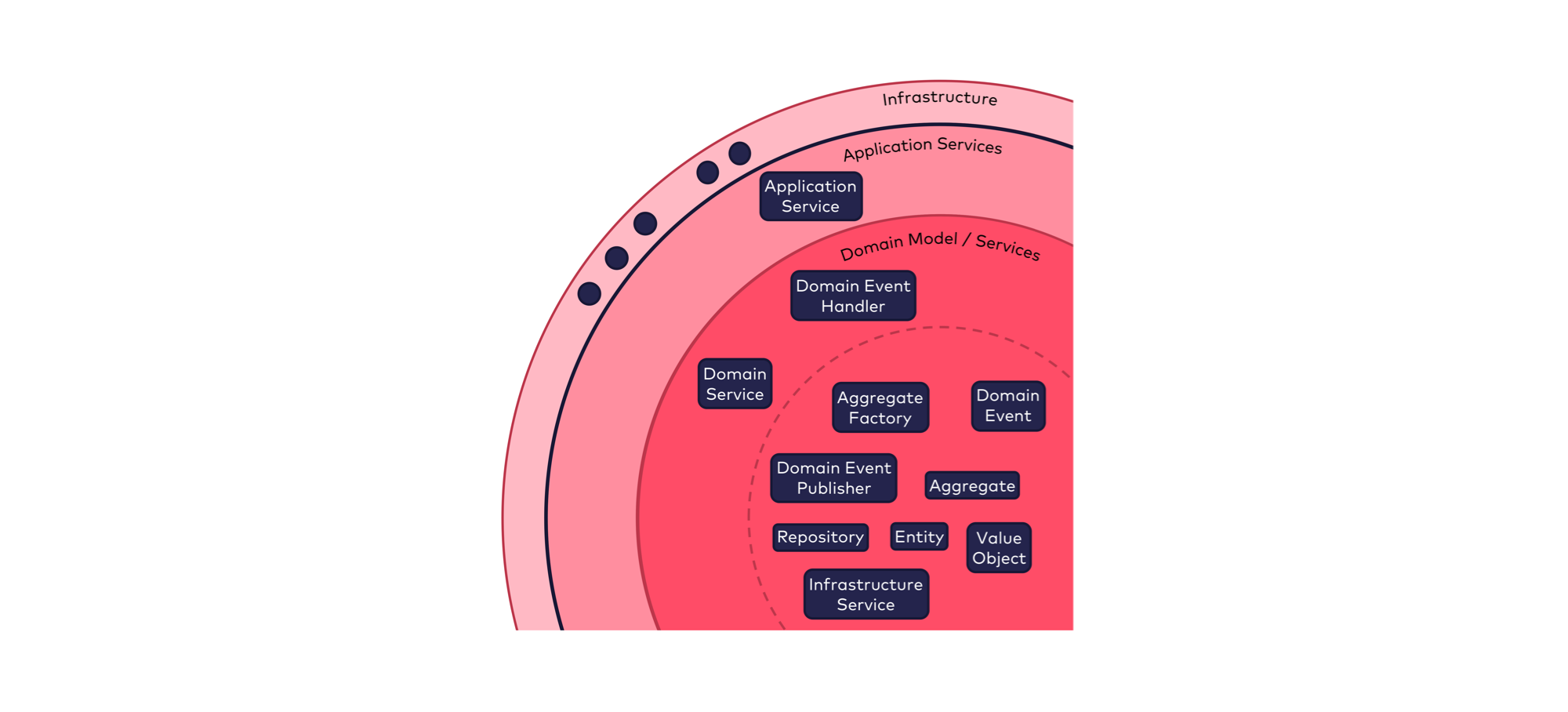
Wenn gefordert wird, dass jede Klasse im Code genau einen Stereotypen trägt, werden Entwickler dazu motiviert, sich bewusster Gedanken zur Bedeutung der jeweiligen Klasse zu machen und dies im Code auch für alle anderen sichtbar zu dokumentieren. Dies dient dem Verständnis und hilft, allenfalls Abweichungen zwischen der durch den Stereotypen angegebenen Semantik und der eigentlichen Verantwortlichkeit der Klasse identifizieren zu können.
Darüber hinaus können basierend auf Stereotypen Regeln definiert werden, welche in der Applikationsarchitektur gelten sollen. Diese Regeln lassen sich dann mit Tools wie z.B. jQAssistant oder ArchUnit automatisch im Build gegen die konkrete Code-Basis überprüfen.
All diese Möglichkeiten zielen darauf ab, ein Code-Basis zu erhalten, welche aus Elementen besteht, die eine klare Bedeutung im Sinne der Applikationsarchitektur ausdrücken und welche die grundlegenden definierten Regeln einhalten. In Bezug auf die angestrebte Trennung zwischen fachlichem und technischem Code aber leisten Stereotypen einen ganz wesentlichen Beitrag. So kann das Vorhandensein von bestimmten Stereotypen auf Elementen im Code dazu benutzt werden, technische Aspekte eines Frameworks für diese Elemente zu konfigurieren. Diesen Ansatz kennen wir bereits aus vielen Frameworks wie Spring oder JakartaEE, und er hat nicht unwesentlich zu einem Überfluss an technischen Annotationen innerhalb unseres Code geführt. Hier drehen wir den Spiess aber um, denn wir wollen jetzt ja nicht wieder im Kern unseres Domänenmodells Annotationen von Spring z.B. für die Steuerung der Transaktionsgrenzen verwenden müssen. Also nutzen wir besser unsere eigenen Stereotyp-Annotationen und instruieren das Framework so an, dass es sich an diese Annotationen anschmiegt. So ist es z.B. mit wenigen Zeile Code möglich, Spring so zu konfigurieren, dass auf der Ebene jedes Application Services eine Transaktion eröffnet werden soll: jeder Application Service ist ja bereits mit dem entsprechenden Stereotypen ausgezeichnet. Spring kann diesen Stereotypen verwenden, um Application Services als Spring Bean zu erkennen und den Interceptor für die Transaktionsdemarkation zu ergänzen. Alles, ohne dadurch nur einen einzigen Import auf Spring innerhalb des Application Core zu erhalten.
Basierend auf der gleichen Idee lassen sich auch folgende (und viele weitere) Aspekte realisieren:
Erkennen weiterer Komponenten für den Dependency Injection Container, nicht nur direkt ausgezeichnete Elemente wie Application Services oder Domain Services, sondern z.B. auch Implementation von Interfaces, welche selbst mit dem Stereotyp „Repository” gekennzeichnet sind (dies sind ja genau die Implementation der Repositories, welche mittels Inversion of Control zur Laufzeit zur Verfügung gestellt werden sollen)
Erzeugen von Boilerplate-Code durch Aspekt-orientierte Programmierung oder Compiler-Plugins, so z.B. Default-Konstruktoren für die Deserialisierung von Value Objects, Entities und Aggregates oder equals()/hashCode()-Methoden mit korrekter Semantik für Value Objects bzw. Entities
Konfiguration von nicht-funktionalen Aspekten, wie z.B. zentralen Logging- oder Fehlerbehandlungsmechansimen
All dies erledigen viele Frameworks bereits seit Jahren für uns, und dies sollen sie auch bei der Trennung von fachlichem und technischen Code weiterhin für uns tun - allerdings basierend auf der Semantik unserer Stereotypen, ganz ohne Verschmutzung des Application Core durch Frameworkabhängigkeit. Inversion of Control in Reinform!
Hier ist ein umfangreiches Code-Beispiel für eine Umsetzung der hier beschriebenen Konzepte verfügbar.