So es wird mal wieder Zeit etwas zum Stand meiner Diplomarbeit zu sagen. Die theoretischen Anforderungen an eine Massendatenverarbeitung habe ich abgeschlossen. Dies soll hier auch nicht Thema sein, sondern direkt die Inhalte meiner Fallstudie gezeigt werden. Zuerst einmal folgt nun die fachliche Beschreibung der Fallstudie. Hier ein Auszug aus meiner Diplomarbeit:
Zielbestimmung & Funktionalität
Ziel der Fallstudie Gehaltsabrechnungssystem ist es verschiedene Lösungsansätze mit Java EE für die Stapelverarbeitung zu vergleichen. Da es sich hier um eine Fallstudie handelt und um kein einzusetzendes produktives System, sind die Anforderungen sehr atypisch gehalten und nicht zu vergleichen mit einer Gehaltsabrechnungssoftware im herkömmlichen Sinne. Somit kann die Fallstudie höchstens als Grundlage für ein zu entwickelndes produktiv einzusetzendes Gehaltsabrechnungssystem dienen.
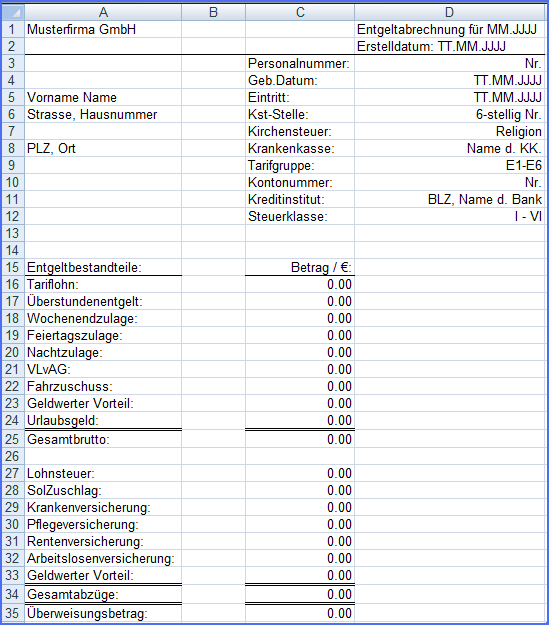
Die Funktionalität des Gehaltsabrechnungssystems in der Fallstudie besteht aus drei Aufgaben bzw. Funktionen. Es enthält eine beliebige Anzahl von fiktiven Daten zu Mitarbeitern eines fiktiven Unternehmens. Diese Daten sind in einem ersten Batchlauf programmatisch zu generieren. Auf Grundlage dieser Daten, findet dann eine monatliche Gehaltsabrechnung für die Mitarbeiter dieses Unternehmens in weiteren (monatlichen) Batchläufen statt. Die einzelnen Gehaltsabrechnungen werden in Excel Arbeitsmappen zu je 1000 Tabellenblättern in einem letzten Batchlauf ausgegeben. Die Formatierung der Excel Tabellenblätter ist in der folgenden Abbilung zu sehen.
Eine Weboberfläche, die als Administrationskonsole verstanden werden kann, bietet die Möglichkeit eine Anzahl an neu zu generierenden Mitarbeitern vorzugeben, die dann von der Anwendung erstellt, in der Datenbank gespeichert werden. Dabei wird das Jahr und der Monat für die ebenfalls zu generierenden Überstunden und Zulagen eines jeden Mitarbeiters mit angegeben. Die monatlich zu allen Mitarbeitern erstellbare Gehaltsabrechnung kann zum einen über die Weboberfläche manuell gesteuert werden und zum anderen kann über einen automatisch zeitgesteuerten Mechanismus die Gehaltsabrechnungen des Vormonats zu jedem Monatsanfang berechnet werden. Dieser Mechanismus ist ebenfalls über die Weboberfläche zu aktivieren oder zu deaktivieren. Die Ausgabe der Entgeltabrechnungen in Excel-Dateien erfolgt entweder manuell oder automatisch. Die genau zu erfassenden Daten sind im nächsten Abschnitt einzusehen.
Die drei beschriebenen Aufgaben (Datengenerierung, Entgeltberechnung und Ausgabe der Entgeltabrechnungen) sind Batchläufe, die über die Weboberfläche zeitlich zu messen sind, um die verschiedenen Implementierungsvarianten vergleichen zu können.
Zur besseren Übersicht folgt eine Auflistung der umgesetzten Punkte:
Das Gehaltsabrechnungssystem als Fallstudie soll Entwicklern Anregungen geben Massendatenverarbeitungsprogramme mit Java EE zu realisieren. Es soll als Grundlage zum Verständnis von Stapelverarbeitungsaufgaben dienen und einem Entwickler Lösungsvorschläge beispielhaft vorstellen.
Damit die Batchanwendung mit Java EE entwickelt werden kann, ist neben einer MySQL Datenbank als Datenhaltungsschicht ein Applikationsserver von Nöten, der die zu entwickelnden Geschäftsobjekte zur Batchverarbeitung managen kann. Hierbei wird auf die Dienste des Applikationsservers von SUN Microsystems®, der auch als Glassfish V2 bezeichnet wird, zurückgegriffen.
Datenstruktur
Zum besseren Verständnis werden hier die zu erfassenden bzw. zu generierenden Daten beschrieben und erläutert. Das exakte Datenbankschema für die zu erfassenden Daten findet sich dann in Kapitel 4 zur Umsetzung der Fallstudie.
Zunächst einmal sollen alle Daten, die zu einem fiktiven Mitarbeiter generiert werden sollen vorgestellt werden. Die Tabelle zeigt die 27 Eigenschaften, die zu einem Mitarbeiter erzeugt werden.
| Personalnummer | Firmeneintritt (TT.MM.JJJJ) | Krankenkasse |
| Name | Steuerklasse (I-VI) | KvSatz (10% - 15%) |
| Vorname | Tarifklasse (E1-E6) | Kreditinstitut |
| Geburtsdatum | Konfession | BLZ |
| Strasse | Kostenstelle (6-stellig) | Kontonummer |
| Hausnummer | VL (ja/nein) | Überstunden/Monat |
| PLZ | Fahrgeld (ja/nein) | Wochenendzulage/Monat |
| Ort | Kantine (ja/nein) | Nachtzulage/Monat |
| Land | Dienstwagen (ja/nein) | Feiertagszulage/Monat |
Einige dieser Daten dienen nur zur Identifizierung oder zusätzlichen Angabe eines Mitarbeiters wie Personalnummer oder die Adressdaten wie Strasse und Postleitzahl. Sie werden nur benötigt, um bei der Ausgabe der Entgeltabrechnung mit angegeben zu werden. Viele Angaben dienen aber der Berechnung für die monatlichen Entgelte. Die Angabe, ob der Mitarbeiter einen Dienstwagen besitzt oder nicht wird beispielsweise für die Ermittlung des geldwerten Vorteils benötigt. Die monatlichen Angaben zu Überstunden oder Zulagen fließen ebenfalls in die Gehaltsabrechnung mit ein.
Die Werte für diese Daten werden wie schon erwähnt von der Anwendung in einem ersten Batchlauf generiert und in der Datenbank persistiert. Wie die Generierung genau abläuft wird in der Umsetzung in Kapitel 4 beschrieben und erläutert. Hier soll zum besseren Verständnis die Struktur der zu generierenden Werte erklärt werden.
Die Personalnummer ist der einzige Wert, der automatisch von der Datenbank erstellt wird, damit wird sichergestellt, dass keine Personalnummer innerhalb der Datenhaltung doppelt vergeben wird. Die Werte, die aus Zeichenketten bestehen, werden aus 8 zufälligen Groß- und Kleinbuchstaben des Alphabets zusammengesetzt. Die Zeichensatzlänge 8 ist hier willkürlich gesetzt und kann auf bis zu 1024 Zeichen erweitert werden. Die aus Zeichenketten bestehenden Werte sind nachfolgend aufgeführt:
- Name; Vorname; Strasse; Ort, Land; Krankenkasse; Kreditinstitut
Zusätzlich gibt es noch einige Daten, die auch aus Zeichenketten bestehen, aber eine bestimmt Semantik beinhalten sollen. Diese Daten sind in der Anwendung als Enumeration (Aufzählung) hinterlegt. Beispielsweise darf die Konfession nur Werte besitzen wie evangelisch, katholisch, islam etc., diese sind für die Berechnung der Kirchensteuer von Bedeutung. Daten die auf der Grundlage von Enumerations beruhen sind:
- Konfession; Steuerklasse; Tarifklasse
Datumswerte in der Form TT.MM.JJJJ werden für die Daten Geburtsdatum und Firmeneintritt nach logischen Gesichtspunkten generiert. Das Geburtsdatum liegt zwischen 1940 und 1990, da das Jahr 2008 das Jahr der Anwendungserstellung ist und ein Mitarbeiter mindestens das 18. Lebensjahr erreicht haben sollte, um in das Unternehmen eintreten zu können. Das Datum für den Eintritt ins Unternehmen ist daher mindestens 18 Jahre vom Geburtsdatum entfernt.
Die Boolschen Werte, die mit ja/nein in der Liste gekennzeichnet sind, geben an ob ein Mitarbeiter zusätzliche Leistungen vom Unternehmen erhält oder nicht. Diese Werte werden zufällig mit true oder false zu jedem Mitarbeiter gesetzt.
- Vermögenswirksame Leistungen (VL); Fahrgeld; Kantine; Dienstwagen
Die übrig gebliebenen Daten sind alles Zahlenwerte. Dabei beinhalten folgende Werte Ganzzahlen, die ebenfalls zufällig erstellt werden:
- Hausnummer (1-300); PLZ (10.000 – 99.999); Kostenstelle (102030 – 102130); BLZ (10.000.000 – 100.000.000); Kontonummer (1.000.000 – 10.000.000)
Die anderen Daten beinhalten zufällige Fließkommazahlen in einem gewissen Wertebereich:
- KvSatz (10.0% - 15.0%); Überstunden (0.00 – 50.00, 0.25er Schritte); Wochenendzulage (0.00 – 36.00, 8.00er Schritte); Nachtzulage (0.00 – 80.00, 40.00er Schritte); Feiertagszulage (0.00 – 24.00, 8.00er Schritte)
Als nächstes werden die Daten (Werte) aufgelistet, die für die Entgeltberechnung aus den generierten Mitarbeiterdaten ermittelt werden.
| Personalnummer | Feiertagszulage | SolZuschlag |
| Jahr | VLvAG | Kirchensteuer |
| Monat | Fahrgeldzuschuss | Krankenversicherung |
| Erstelldatum | Kantinenzuschuss | Pflegeversicherung |
| Überweisungsbetrag | Geldwerter Vorteil (Brutto) | Rentenversicherung |
| Tariflohn | Urlaubsgeld | Arbeitslosenversicherung |
| Überstundenentgelt | Weihnachtsgeld | Vermögensbildung |
| Nachtzulage | Brutto_Summe | Geldwerter Vorteil (Abzüge) |
| Wochenendzulage | Lohnsteuer | Abzüge_Summe |
Die Berechnung der Entgelte, was in Kapitel 4 ebenfalls gezeigt wird, erfolgt nicht nach gesetzlichen Vorschriften, da dies nicht Bedingung für das Ziel der Fallstudie ist und zudem die Komplexität der Berechnung und die damit verbundene weitere Datengenerierung um ein Vielfaches gesteigert hättet. Dennoch sind die wichtigsten Bestandteile einer Entgeltabrechnung vorhanden. Bei genauerer Betrachtung fällt auf, dass Redundanzen bei den Daten auftreten. Die Summen für Brutto und Abzüge beispielsweise könnten auch bei jeder Abfrage oder Ausgabe einer Entgeltabrechnung aus den übrigen Werten berechnet werden. Diese Art der Denormalisierung, die bereits in Kapitel 2.2.4 erläutert wurde, wird also schon im Vorhinein für die Umsetzung einer performanten Anwendung berücksichtig und in Kapitel 4 noch einmal erörtert. Die Angaben zu den Überstunden und Zulagen sind bei den generierenden Mitarbeiterdaten zeitliche Werte und bei den Daten zur Entgeltabrechnung Geldwerte.
Wie auch schon bei den generierbaren Daten zu jedem Mitarbeiter, soll hier die Datenstruktur der Daten für die Entgeltabrechnungen gezeigt werden.
Die Personalnummer eines Mitarbeiters wird für die Identifizierung der Entgeltabrechnung aus den Mitarbeiter Stammdaten übernommen. Schließlich muss jede Abrechnung einem bestimmten Mitarbeiter zugeordnet werden können.
Das Jahr (JJJJ) und der Monat (MM) sind bei der automatischen Erzeugung jeweils die aktuellen Werte des vorherigen Monats oder können manuell über die Weboberfläche vorgegeben werden.
Das Erstelldatum ist das aktuelle Tagesdatum (TT.MM.JJJJ) an dem die Entgeltabrechnungen erstellt werden.
Die übrigen Daten beinhalten alle Fließkommazahlen als Werte. Nachfolgend sind diese Daten mit ihren eventuellen Wertebereichen aufgelistet:
- Überweisungsbetrag
- Tariflohn (je nach Tarifklasse 1990.95 – 2866.45)
- Überstundenentgelt (Überstunden x 11.54)
- Nachtzulage (Nachtzulage(Zeit) x 6.72)
- Wochenendzulage (Wochenendzulage(Zeit) x 4.53)
- Feiertagszulage (Feiertagszulage(Zeit) x 7.28)
- VLvAG (0.00 oder 39.88)
- Fahrgeldzuschuss (0.00 oder 150.00)
- Kantinenzuschuss (0.00 oder 60.75)
- Geldwerter Vorteil für den Dienstwagen (0.00 oder 200.00)
- Urlaubsgeld nur für Monat Mai (95% vom Tariflohn)
- Weihnachtsgeld nur für Monat November (100% vom Tariflohn)
- Brutto_Summe
- Lohnsteuer (15% - 25% von Brutto_Summe)
- SolZuschlag (1% von Brutto_Summe)
- Kirchensteuer (0%, 8% oder 9% vom Steuer-Brutto)
- Krankenversicherung (KvSatz von Summe_Brutto)
- Pflegeversicherung (1.95% von Summe_Brutto)
- Rentenversicherung (9.75% von Summe_Brutto)
- Arbeitslosenversicherung (3.25% von Summe_Brutto)
- Vermögensbildung aus VLvAG z.B. Bausparvertrag (siehe VLvAG)
- Geldwerter Vorteil für die Verrechnung (s.o.)
- Abzüge_Summe
Alle Werte zur Entgeltberechnung werden beim letzten Batchlauf, der Erzeugung der Abrechnungen für einen bestimmten Monat in Excel-Dateien, für jeden Mitarbeiter ausgelesen und den entsprechenden Feldern eines Excel-Tabellenblattes zugewiesen.
Mit den Kenntnissen der Zielbestimmung und Beschreibung der Funktionalität sowie der Datenstruktur wird nun im nächsten Kapitel die Umsetzung mit der Java EE Spezifikation erläutert und durch Messungen die Performanz der unterschiedlichen Lösungsvarianten ermittelt. Auf Grundlage der Messungen, werden dann Gründe und Verbesserungen zu den einzelnen Varianten dargestellt.