Der ein oder andere Punkt wird der Gliederung sicherlich noch ergänzt werden:
1. Einleitung
1.1. Motivation
u.a. Bezug zu meiner Projektarbeit, Anforderungen an Unternehmen, neue Technologien
1.2. Beschreibung der Thematik
Historie der Massendatenverarbeitung und Java EE
1.3. Zielsetzung
Effiziente Massendatenverarbeitung am Beispiel, Erläuterungen zu Java EE
1.4. Vorgehensweise
Siehe nächste Kapitel
2. Anforderungen an die Massendatenverarbeitung
Aufstellen von Thesen, was zu beachten ist
2.1. Funktionale Anforderungen
Unternehmensprozesse unterstützen und lösen
2.2. Nichtfunktionale Anforderungen
Technische Aspekte
3. Umsetzung der Massendatenverarbeitung
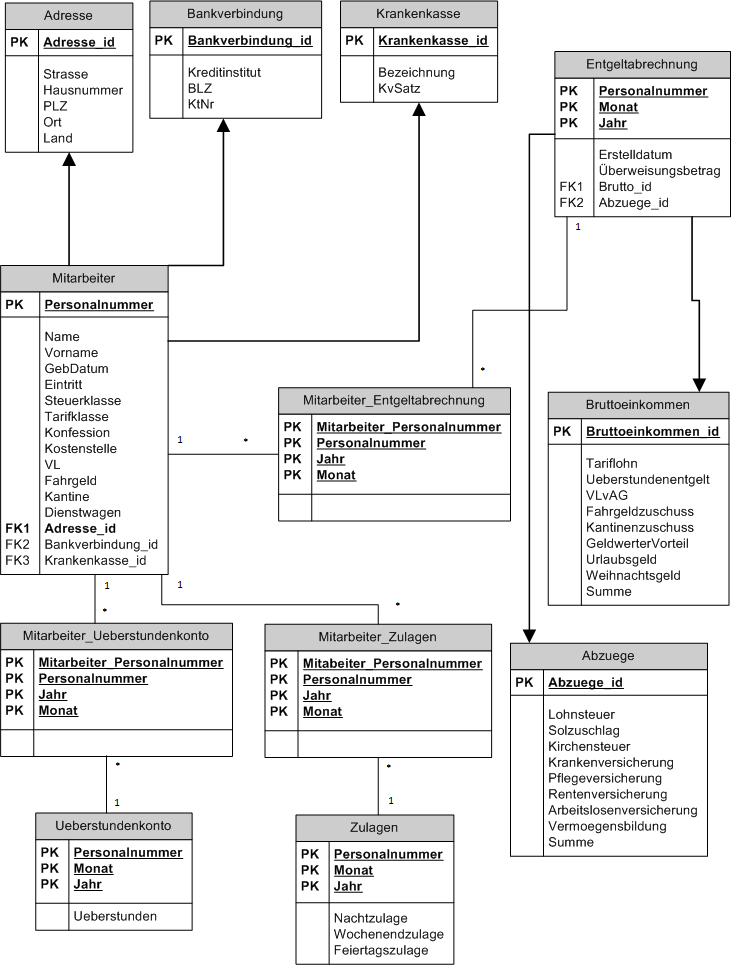
3.1. Fallstudie: Gehaltsabrechnungssystem
Pflichtenheft zur Fallstudie
3.2. Interceptoren zur Leistungsmessung
Möglichkeiten zur Messbarkeit der Leistung
3.3. Datenbankschicht über Entity Beans
Erläuterungen zu Entity Beans am konkreten Beispiel
3.4. Geschäftslogik über Session Beans
Erläuterungen der anderen Beanarten am konkreten Beispiel
3.5. Möglichkeiten der Batch-Initialisierung
u.a. TimerService
3.6. Parallelverarbeitung mit Message Driven Beans
Erklärung zu Kommunikation und Verbesserung der Verarbeitungsgeschwindigkeit
3.7. Parallelverarbeitung mit Threads
Erläuterung eines anderen Weges zur Verbesserung der Verarbeitungsgeschwindigkeit
4. Fazit und Ausblick