« May 2007 | Main | September 2007 »
June 29, 2007
Software release is like body building
If your are trying to make muscle gains, you eat more and do heavy lifting. But during this phase you are gaining fat as well. When bodybuilders prepare for the competition, they try to lose body fat to achieve better muscle definition. This “cutting” phase starts 3-4 months before competition. More tips and tricks from the guy I meet in the office daily (in German).
In a software project you have the requirement to develop new features while keeping the holy green build. This requirements are often contradictory in a bigger project (with 200 developers for example, like one I am currently working for).
If even only every second developer is working on some feature and committing only couple of lines a day, it destabilizes the whole system a lot. If the wish is to have a deliverable product from the mainline at any time, then you have no chance.

So you end up creating rigorous committing policy drastically reducing the development speed or stopping the development completely by proclaiming different sorts of code freeze.
I think you can not address this two requirements in a bigger project simultaneously despite all this agile propaganda. If you are going to make a release (to participate to a bodybuilder competition), you should prepare for this event. You should make a source code branch and concentrate on stabilizing - no new features, no refactoring, only needed bug fixing. On the development branch you make you vibrant development, reorganizing the code having your “off-season” in the bodybuilders language.
Posted by VladimirDobriakov at 10:48 PM
June 26, 2007
Aggregating iCal with a simple python script
My current solution is to use a universal iCal viewer of netvibes.com (one iCal source capable). Below is how it looks like:
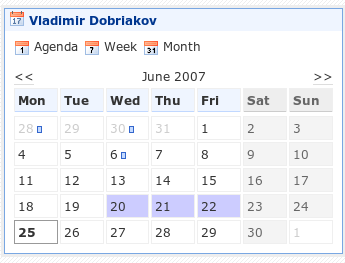
And here is a proxy script I have put on my web server, that aggregates multiple iCal sources.
"""
aggregates multiple google calendars (in iCal format) and returns them as http response
"""
import urllib
calendars = [
("vd", "http://www.google.com/calendar/ical/put_your_url1_here"),
("innoq", "http://www.google.com/calendar/ical/put_your_url2_here"),
]
def vdcal(req):
res = ""
is_first = True
for cal_id, cal_url in calendars:
content = urllib.urlopen(cal_url)
begin_emitting = False
for l in content:
if l.startswith("BEGIN:VEVENT") or is_first:
begin_emitting = True
if begin_emitting and not l.startswith("END:VCALENDAR"):
res += l
is_first = False
res += "END:VCALENDAR"
return res
For the first calender I take both the header and the events. For the following calenders I only take the events itself (starting with “BEGIN:VEVENT”). It’s that easy!
Posted by VladimirDobriakov at 9:38 PM
June 25, 2007
Fixing Google Calendar with Yahoo Pipes
I use Google Calendar for managing my appointments and similar stuff. In particular I created my personal calendar and a calendar for innoQ events, that can be shared by all colleagues. I can imagine couple more calendar instances like if my wife wants to have one or one for windsurfing club in Kaarst.
The main google calendar UI is great and you can select multiple calendars to see them at once. But unfortunately not in the embeddable version - you can only show them individually. And even iGoogle on google.de does not work properly. I mean it shows the month, but it does not show any appointments, as lot of people noticed.
The pipes

Luckily google offers the whole calendar data as both iCalendar and as a feed. OK, great opportunity to use Yahoo pipes for aggregating and adjusting the data, I thought. You can define RSS data sources, filter and connect them and even use regular expressions for manipulating the content.
Unfortunately with the Lego-style of programming you hit the limits pretty soon if you try a bit complexer transformation. And with a text oriented general purpose advanced programming language it is so much easier to achieve the desired result… see the next (upcoming) entry
Investigating google.de problems
One of the reasons why it so hard to process google’s XML calendar data is the strange localization approach. It seems like google is not interested in your “Accept-Language” http request header and urls like google.de or google.com have no particular meaning. The only thing, that counts, is the public IP address your request comes from. That is why, for example in the german office of a finnish company with English set as preferred language in the browser settings you get the google portal in Finnish language. Even if you type in “google.ru”, you will be redirected to google.fi. I know they want to show you the right ads, but it would be really helpful to get the user interface in the language you request.
By the way, this strange IP-based localization strategy seems to me (after some debugging) to be the cause why google calendar does not work on google.de. Even the content and meta data of the atom feed depends on public IP address of the computer the request comes from.
Here is an XML snippet:
<entry>
<id>http://www.google.com/calendar/feeds/d16....hus%40group.calendar.google.com/private-...
</id>
<published>2007-02-19T20:24:15.000Z</published>
<updated>2007-05-13T09:28:02.000Z</updated>
<category scheme="http://schemas.google.com/g/2005#kind" term="http://schemas.google.com/g/2005#event"/>
<title type="text">innoQ Event</title>
<summary type="html">
Wann: Do 10. Mai 2007 bis Fr 11. Mai 2007 <br> <br>Status des Termins: bestätigt
</summary>
As you can see under
I hope the new official API GData is more developer friendly or I’ll try a small script with the simpler text oriented iCal format. Stay tuned…
Posted by VladimirDobriakov at 9:50 PM
June 9, 2007
Six-hole-puncher 2.0
I was trying to switch to a paperless office for quite a time. Working on different computers and different operating systems it was impossible to find a tool or a set of tools that worked for me.
And from the functionality aspect I saw nothing comparable to my black paper based organizer. I was even thinking about buying a six-hole-puncher to implement ;-) some extensions or even simply to extend the useful life of my organizer.

So called Web 2.0 solutions were getting better and better and most of them are trying to support open standards like iCalendar or provide information via RSS or Atom feeds. So I found the solution of my dreams.

With Web 2.0 style aggregators you do not need to commit to one service provider. You can easily aggregate from different sources. For example, I’am using the Netvibes as an aggregator, calendar from Google, bookmark service from del.icio.us You can choose from about a zillion of widgets and gadgets or write your own. There is also a universal iframe widget. This one I use especially often in connection with my own server-based html scraping and aggregation scripts.
Netvibes is one of the pioneers of the Web 2.0 style portals. It works really well, even if it is called beta. I mean as opposite to really buggy iGoogle - more on bugs in the next post. Do not understand me wrong. I like google and all its applications. But they are simply not so mature and so all-embracing as netvibes gadgets. But I am afraid, a small French startup has no chance against the two Godzillas of the web. And do not forget the third, junior partner from Redmond, they have also somehow detected this Web 2.0 buzz.
Posted by VladimirDobriakov at 10:38 PM